开篇词|为什么想用Rust写一个消息队列?
本课程为精品小课,不标配音频
你好,我是文强,一个长期在基础架构领域摸爬滚打的技术人,也是极客时间 《深入拆解消息队列47讲》 的作者。这次为你带来《深入拆解消息队列47讲》的后续课程:《Rust 实战 · 手写下一代云原生消息队列》。
没错,这门课程的关键词将是 Rust 编程。
学习 Rust 的关键问题是什么?
近几年,Rust 这门语言不断地出现在我们的视野中,我们经常会看到 “Rust 重写一切” 这句话。作为使用过多门编程语言的老研发,我对这种口号一般是免疫的。因为每一种新语言出现时,都会有类似的口号,比如 Scala、Golang、Haskell 等等。
真正让我想去尝试 Rust 这门语言的契机是: Rust 进入了 Linux 内核。当时我就在想,这么多年来,除了 C 和 C++ 外,Rust 还是第一门进入内核的新兴语言。像 Linus这么轴的人竟然能让 Rust 进入内核,说明这个语言一定有非常厉害的地方。
在学习了 Rust 一段时间后,我遇到了第一个关键问题: 语法记不住,各种语法糖、技巧不会用,不会写。 其实对于我们这种长期编程的人来说,一般接触一门语言,花个几天就能开始产出了。但是,在 Rust 中我花了很长时间看完基础语法和各种特性后,第一个感觉就是好像懂了,但是真正要写点东西的时候,又发现好像啥都没懂。
本着实践是效率最高的学习方式,我开始去找能提升 Rust 技能的实战项目,这时我遇到了第二个关键问题: 没有合适的项目让我去学习和实践。而且,这个问题还挺普遍。业界有很多偏基础语法、语言特性的资料,却少有让我们能够真正熟练掌握和应用这门语言的资料。
为何想用 Rust 编写项目?
怎么办?不能放弃啊!尤其是在体验了 Rust 的各种优点后,比如生命周期管理、无GC、借用等等特性。
这让我想起了我在一几年的时候,负责过的一个用 C++ 重写的 Kafka 项目。这个项目最终商业化了,还产生了不错的收益,但是最后,这个 C++ 重写的 Kafka 却不再维护了,用回了社区版本 Java 写的 Kafka。放弃的主要原因是 C++ 版本的 Kafka 特性支持跟不上社区的进度。而跟不上的一个核心原因就是 C++ 的开发效率确实比 Java 低很多,但是 C++ 语言特性带来的性能提升却是实实在在的,比 Java 写的社区版本高很多。
得益于多语言经历,我发现 Rust 具有不输 C++ 的性能,但是编码效率却比C++高很多。
所以我萌生了用 Rust 写一个消息队列的想法。一方面,我希望能让自己快速掌握这门语言,并应用于实际开发;另一方面,也是想把自己在消息队列这块的积累用 Rust 刷新一下,并沉淀成具体的项目。
很高兴,在过去一年的时间里,这个消息队列已经初具雏形了。
在这段编码过程中,我经历了从 Rust 小白到用 Rust 写成一个分布式基础软件的过程。由于Rust 确实是一门学习曲线很陡的语言,我在这期间踩了很多坑,也走了很多弯路,所以我想将这个过程分享出来,希望能带给你直接的帮助。
这门课是如何设计的?
这就不得不提到我们的课程设计。
诚如你所见,这个专栏目前只有十几讲,手写一个分布式基础软件又该是怎样的一个工作量,想必你有概念。所以,这将是一个系列课程。我们的整体学习路径是:从0开始,用 Rust 写成一个分布式的基础软件(消息队列)。期间会讲解 Rust 的实战技巧,带你融会贯通这门语言。最终,我们一起打造出一个牛逼的开源基础软件。
系列中的每一门课,都将按照 10 讲左右的篇幅去设计,定位实战,所以会包括技术方案设计、Rust 代码实现及讲解两大部分。
看到这里,你可能还会有点顾虑,如果没有消息队列的技术背景,我能学明白吗?
在我看来,影响不大。消息队列隶属基础软件,而分布式基础软件的基础模块都是通用的,比如单机网络、存储、分布式一致性、分布式高性能读写等等。换句话说,你可以忽略技术背景,而去关注项目编程本身,去关注 Rust 这门语言有哪些不同之处和使用优势。
那么,作为系列课程的第一门课,我们要怎么出发呢?
既然是实战,就不能只讲实现思路,而忽略实现过程,所以我们要聚焦一下,这门课程我们将主要讲解如何用 Rust 实现一个消息队列架构中的必要组件:类Zookeeper的分布式协调服务。而且这部分从代码实现逻辑上看,也是和消息队列业务逻辑无关的,所以更无需担心自己是否具有消息队列基础。
课程设计思路如下:
-
先完成消息队列的整体技术方案设计,讲清楚我们整个系列课程是要做成什么样的消息队列。
-
在开始编码之前,我们需要重点掌握 Rust 的哪些知识点,并对这些知识点做一个精简的讲解和资料链接。
-
教你如何组织、管理、编译一个复杂的 Rust 项目,并完成最基础的命令行参数、配置、日志、测试用例部分的编写,即完成代码的初始框架。
-
通过单机网络层、单机存储层、分布式集群这三个步骤,构建一个简单的分布式集群化的存储集群。
-
在当前的分布式集群化的存储集群的基础上,实现存储消息队列集群元数据所需要的 KV 存储能力。
-
从客户端和服务端的角度讲解提高性能的常用技巧,如客户端的连接池、连接复用、失败重试等,服务端的主节点读写、从节点可读的能力等。
完成本课程的学习后,你就掌握了如何用 Rust 编写一个分布式的 KV 模型存储的元数据集群。具体内容还可以参考下本课程的知识脑图。
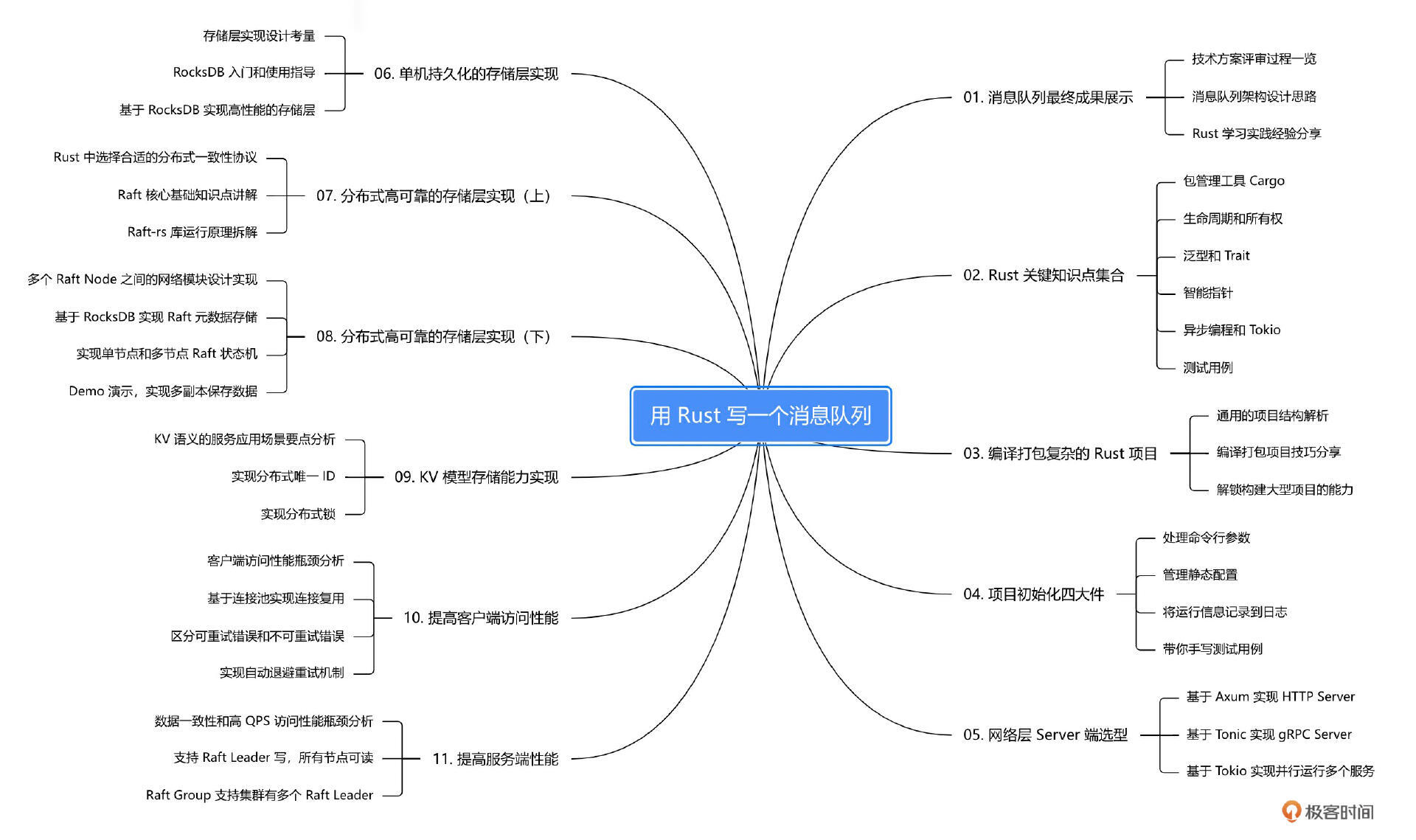
在这里,你会看到项目核心逻辑以及 Rust 编程实现过程,还会有可运行的 Demo 支持大家学习和讨论。而随着系列课程的展开,你还会看到项目中更多功能模块的实现,更多 Rust 语法和特性的使用,期待你能在实践中收获全新的编程体验。
本课程所有可运行的源代码都在这里,请参考 robustmq-geek。
好,现在就开启我们的 Rust 编程之旅吧!
以终为始:手写开源消息队列最终成果展示
本课程为精品小课,不标配音频
你好,我是文强。
在课程的最开始,我想先带你了解一下我们的最终产出是什么,也就是这个消息队列它是什么样子的,还会分享一些我自己在学习 Rust 这门语言过程中的经验,帮助你大胆入门。
对比经典的消息队列
开篇词中我分享过,本系列课程的目标是完成一个分布式基础软件:消息队列。所以我们不妨先来看一张经典的消息队列系统架构图。
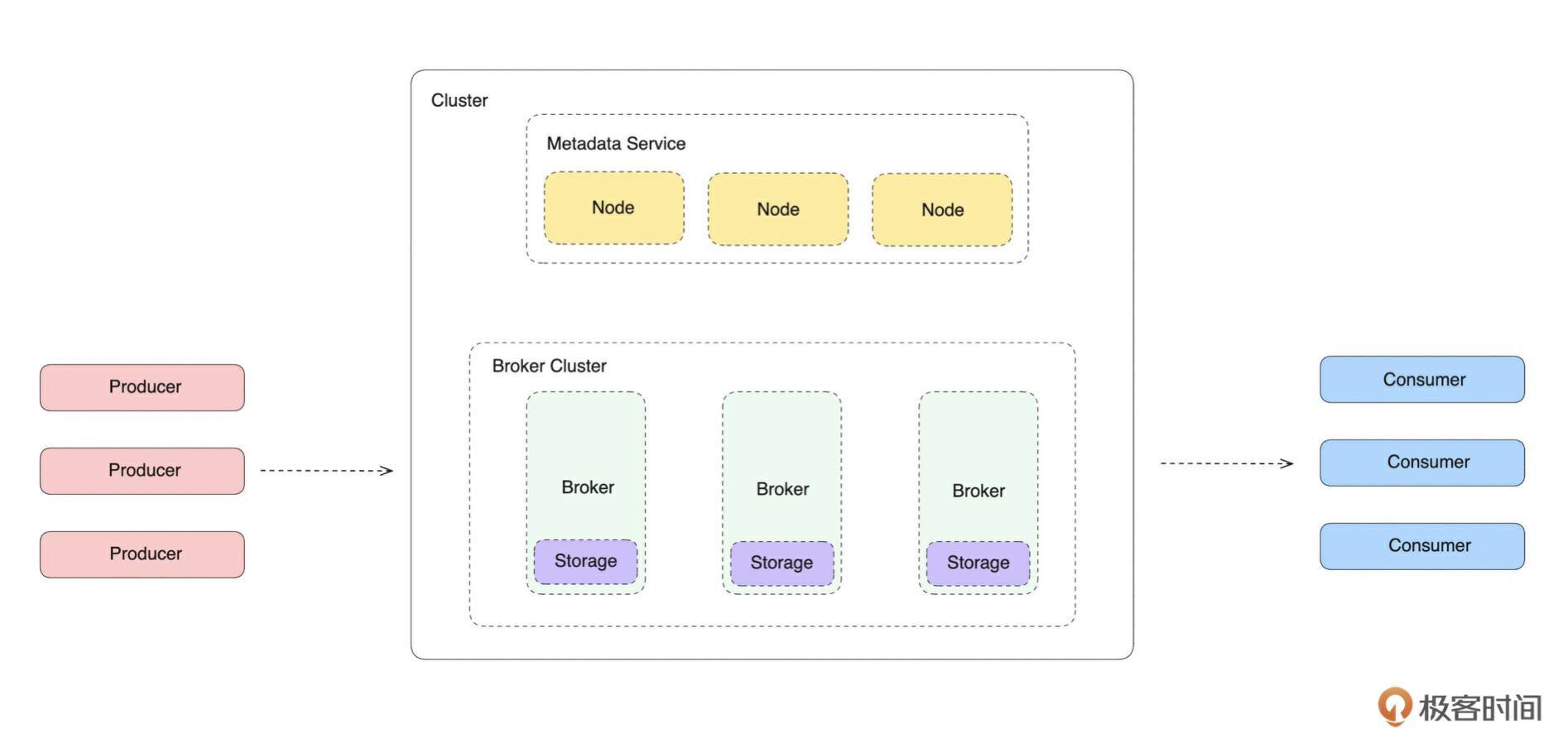
如上图所示,消息队列在架构上分为 客户端、 服务端集群、 消费端 三大部分。我们这门课要实现的是服务端集群这部分。相当于现在社区主流的消息队列,比如 RocketMQ、Kafka、RabbitMQ 、Pulsar等。
从架构的角度,服务端集群都是由 Broker 集群和元数据集群两部分组成。Broker 集群负责消息数据的读写,元数据集群负责 Broker 集群元数据的管理和部分 Broker 集群的管控、调度操作。
从实现来看,Broker 集群可以分为计算层和存储层,计算层负责消息队列相关逻辑的处理,存储层负责消息数据的持久化存储。
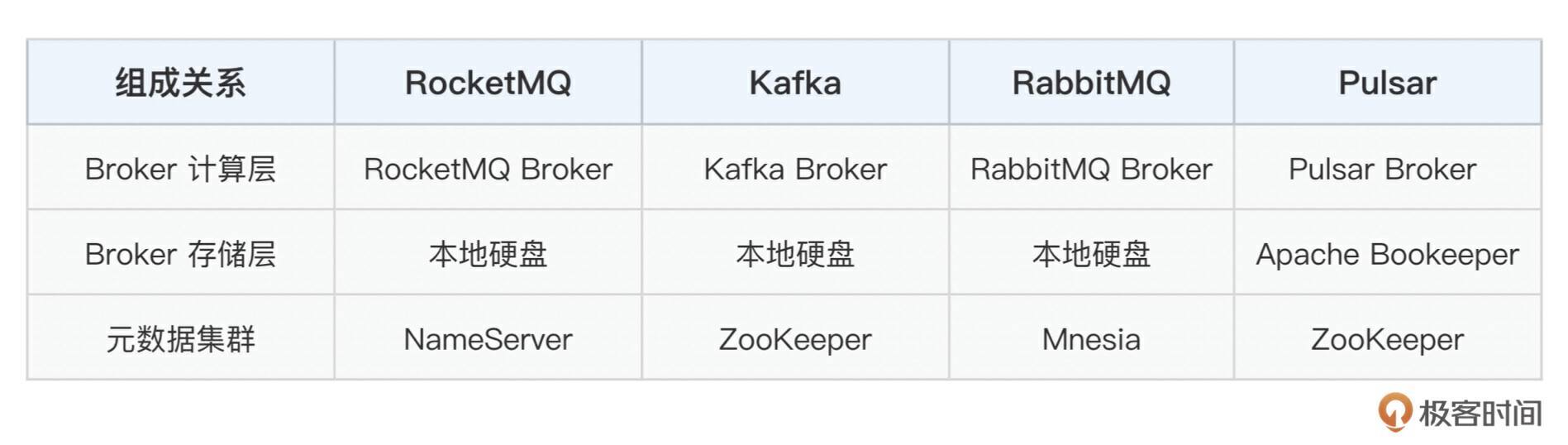
在当前主流的消息队列中,Broker 集群和元数据集群的组成关系如下:
我们在开篇词中讲了,我们希望做成一个很牛逼的消息队列。那你可能有疑问,既然有这么多成熟的消息队列了,为什么还要再写一个?会有什么优势?你可以去我的 项目官网 中找找答案,也欢迎在留言区与我交流!
不过这里我更想强调的是,我们不是在做一个玩具,这也不是一个单纯练手的项目。 项目的一切设计和实现,都是按照标准工业级别的开源基础软件要求来设计和落地的。
那我们最终会做成一个什么样子的消息队列呢?
最终作品:云原生 Serverless 消息队列
先来下个定义:
目标是基于 Rust 实现可以兼容多种主流消息队列协议、架构上具备完整 Serverless 能力的消息队列。
从定义来看,你要围绕着“ 兼容多种主流消息队列协议”和“ 架构上具备完整 Serverless 能力”这两个点来理解我们后续的架构设计。
先看一下我们最终要完成的消息队列系统架构图。
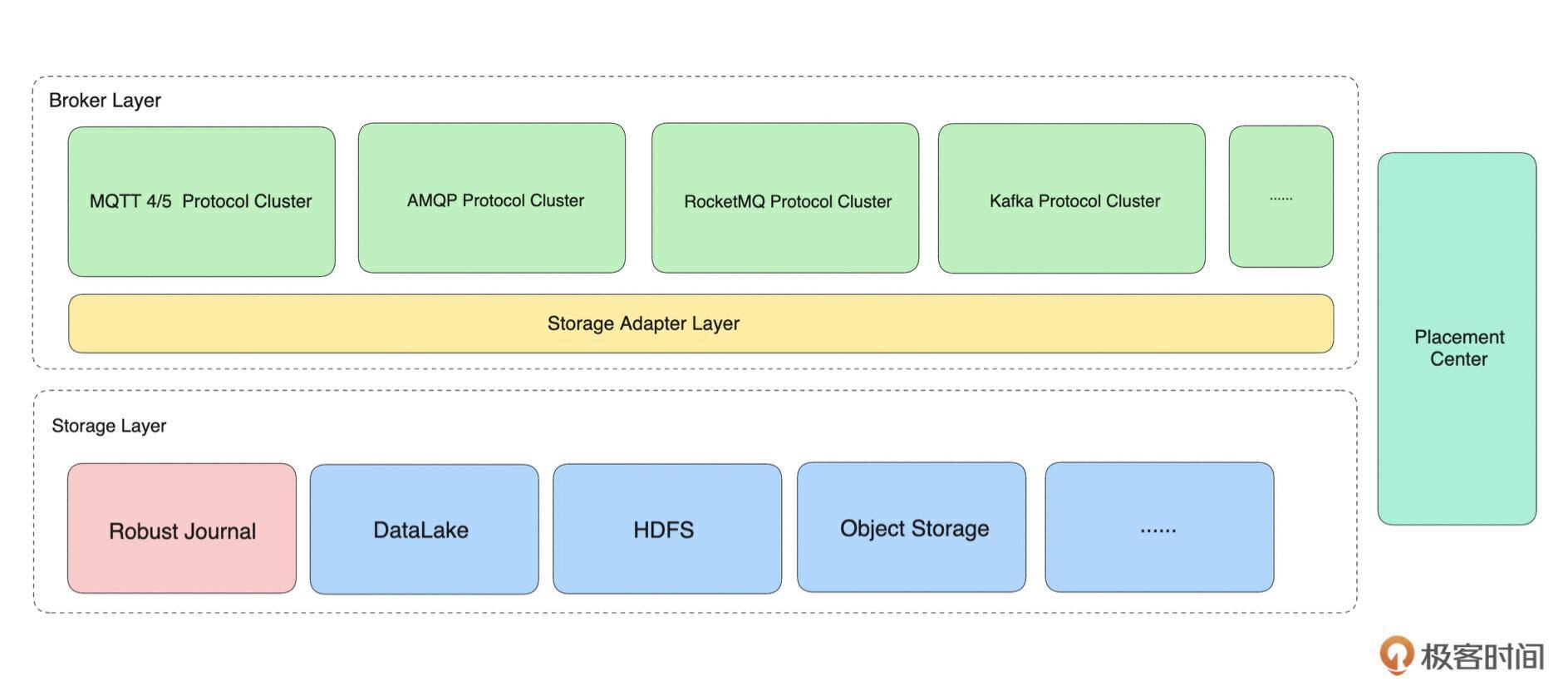
如上图所示,从设计上来看,我们要完成的 MQ 也是由 Broker 集群(计算层 + 存储层)和元数据集群两部分组成。元数据集群对应图中的 Placement Center,Broker 集群也分为计算层和存储层,每个部分具备分布式集群化部署、快速水平扩容的能力。
和上面的表格关系对应如下:
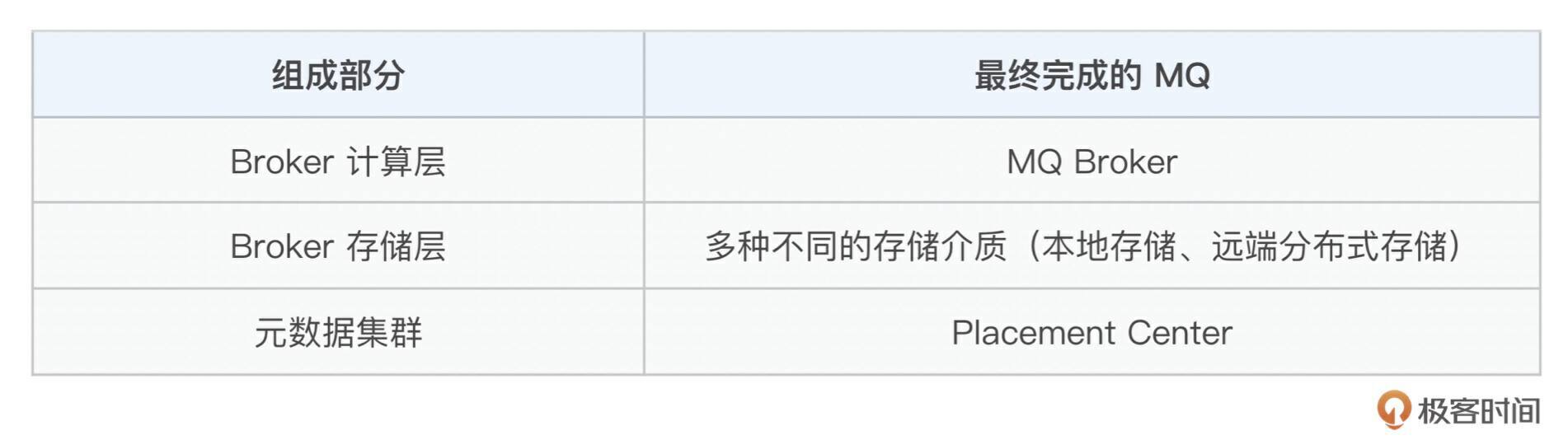
了解了大致的系统架构,接下来我们放一张 MQ 最终架构的详细设计图,针对以上三部分做了展开,你可以尝试理解一下。因为这门课并不能覆盖全部实现,所以这里就不详细展开讲了,有需要的话,我们可以在评论区讨论。
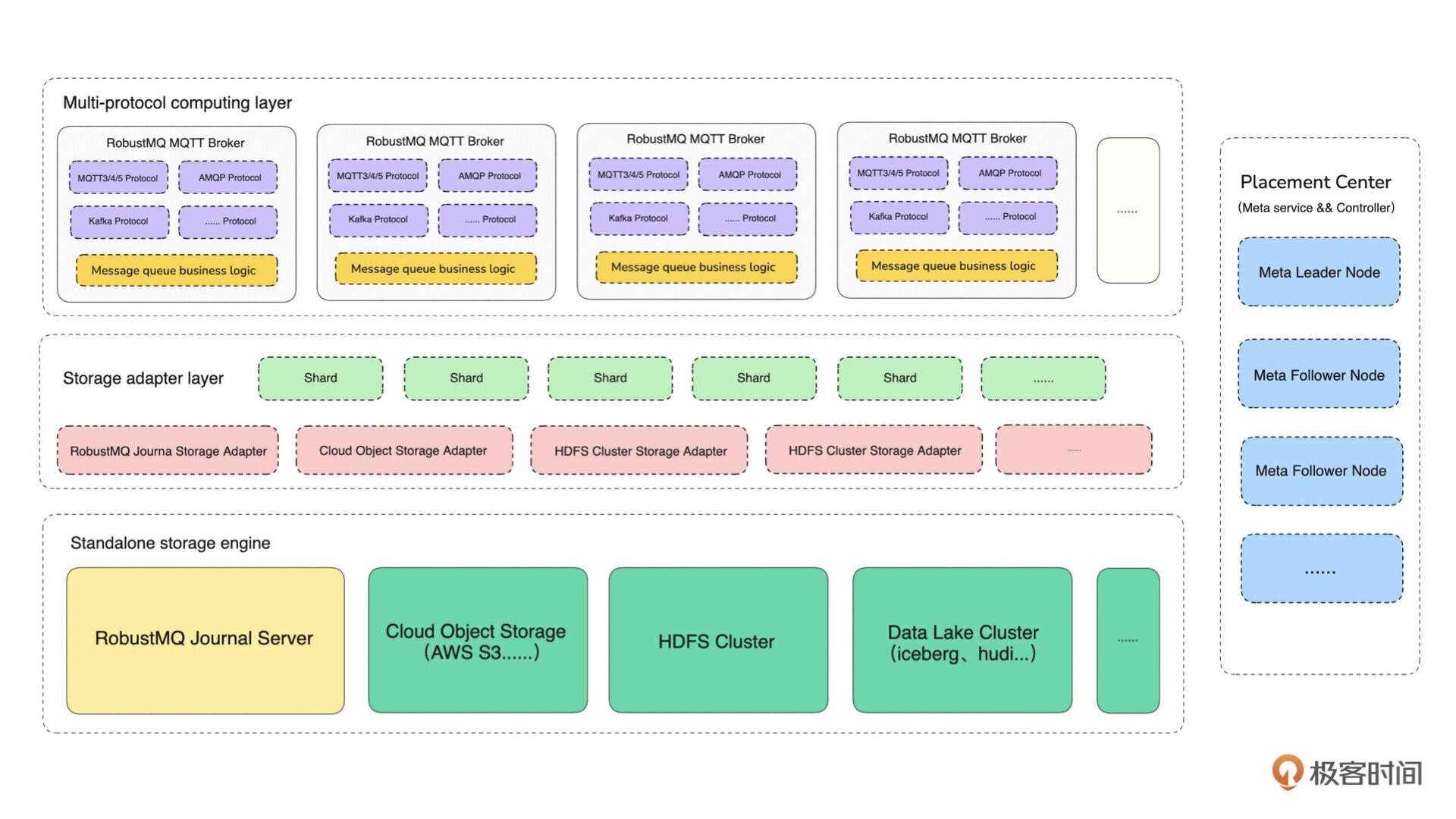
值得一提的是,从实现来看,整个 MQ 的实现是 100% 用 Rust 开发完成的。 在系列课程的第一阶段,我将会带你完成元数据集群(Placement Center)主体功能的开发。
第一阶段作品:元数据存储服务
在我们的设计中,元数据集群功能分为两部分: 元数据存储 和 集群调度。
元数据存储部分,你可以把它理解为一个分布式的 KV 存储引擎(类似 ZooKeeper),集群调度可以理解为在存储引擎之上,实现了对 Broker 集群的一些管控、调度逻辑。
所以,你可以把第一阶段的课程,简单理解为我们在实现一个 分布式的 KV 存储引擎。接下来,我们来看下元数据服务的详细架构图,从而来拆解我们在这个阶段的课程要做哪些事情。
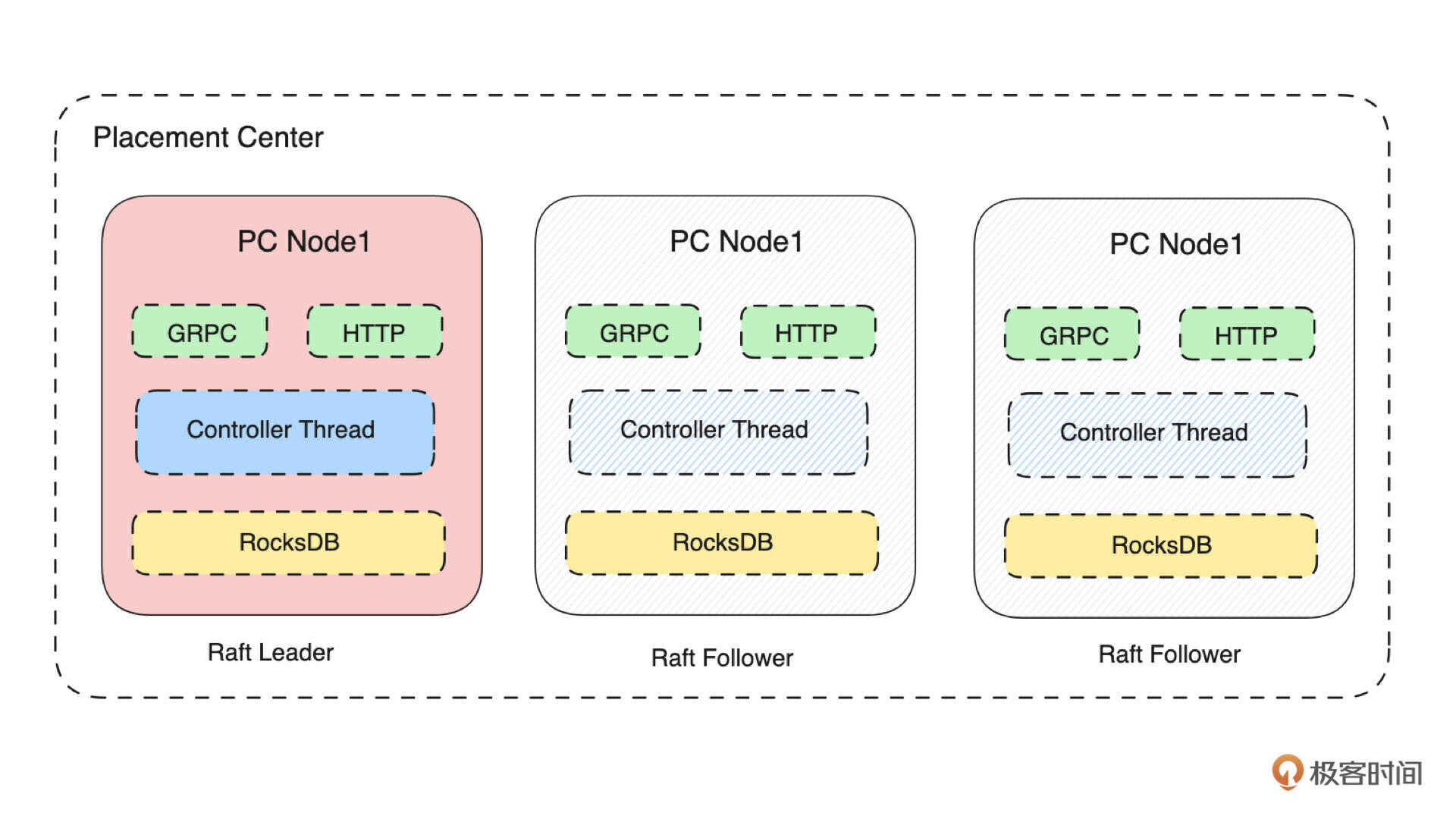
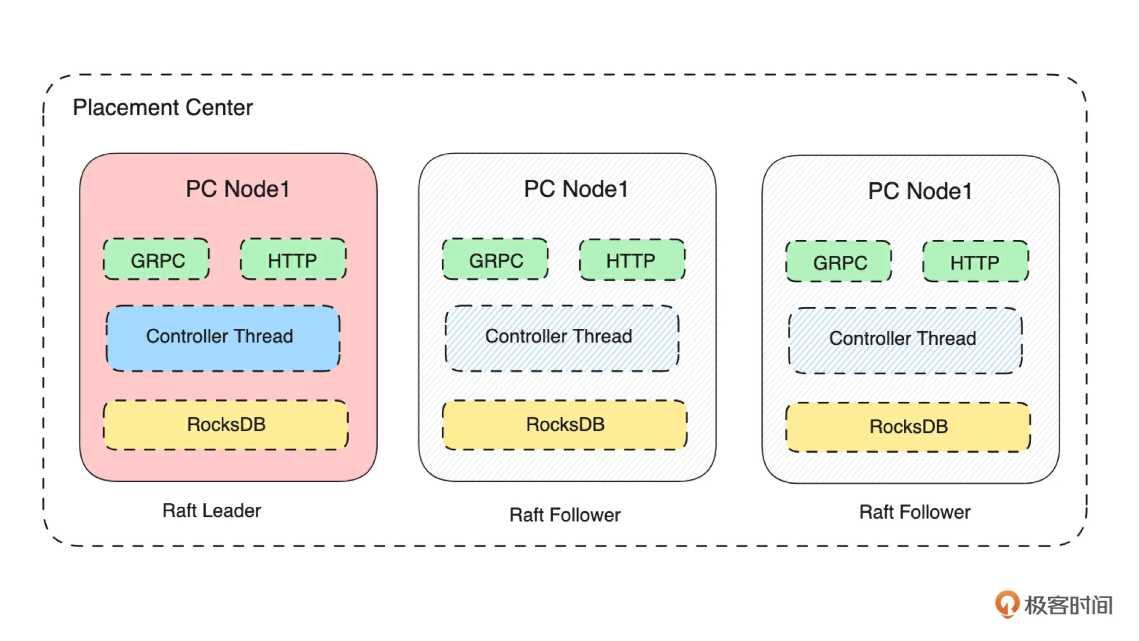
如上图所示,我们把元数据集群命名为 Placement Center。它是一个由多台 Server 组成的、基于 Raft 协议构建的集群,每台 Server 的存储层是基于 RocksDB 构建的 KV 存储模型。所以我们在实现元数据集群的过程中,就需要实现网络 Server、单机存储、分布式集群三个大模块。在接下来的课程中,我们会详细讲解各个部分的设计。
我们都知道,Rust 的学习经验陡峭。那么如果用 Rust 开发完成消息队列这种复杂的基础软件,需要先具备哪些能力呢?具体的知识点储备有很多,下节课我会集中整理,这里我想先分享一下我个人在 Rust 上的学习实践经验,你也可以在心里建立一个预期。
Rust 学习实践经验分享
在我看来,说 Rust 这个语言学习曲线陡峭的原因在于: 它的语法和语言特性和其他主流语言是有很大区别的,并且语法和特性都比较复杂。比如它通过生命周期来代替垃圾回收(GC),就衍生了所有权、借用、各种智能指针、Sync/Send/.await 等多线程编程语法等等的概念和用法。
在我看来,Rust 是拔高了其语言学习本身的成本,换来了其高性能和高安全性。这也是它现在被很多人推崇的原因。也就是: 学会了,就很好用。
在我自己学习实践 Rust 的过程中,我总结了四条经验。
经验一:学习 Rust 语言的基础知识点,主要选择《Rust语言圣经》这份资料就够了,然后需要具备检索和举一反三的能力。
在我开始学习 Rust 时,我买了很多 Rust 的书籍。但是我发现,这些书籍的学习效果都不是特别理想。整个过程下来,我个人对 Rust 语言本身基础知识点的学习,80% 都来源于 《Rust语言圣经》。这本书,你需要重点关注第 一、 二、 四、 八、 九、 十一 等6个章节。这里包含了 Rust 编程会用到的几乎所有知识点。
从表达上来看,它也更适合中文的阅读习惯。它的问题是有的点讲得不够详细,这就需要通过其他资料来扩充,比如这三份:
-
基础知识点补充: 《Rust 程序设计语言-中文版》 和 《Rust 程序设计语言-英文原版》 是官方的 Rust 书,对每个知识点讲得很细。只是这里面的内容大部分在《Rust语言圣经》中已经讲到了,所以不建议直接看这本书,而是把它作为补充,在看《Rust语言圣经》有不明白的地方,就按照目录索引来这里找找有没有想要的答案。
-
Tokio:你只要用 Rust 编程,Tokio 就一定要掌握。而学习 Tokio,主要看这两个文档: 《Tokio 官网》 和 《Rust异步编程和Tokio框架》。你一定要掌握 Tokio 的几个主要知识点:Runtime、Task、Network、Channel、Mutex、RwLock、Notify、Barrier、Semaphore。在实践中非常常用。
-
宏编程:宏编程作为 Rust 的一个主要特性,它主要是用来简化重复代码的。在很多开源项目中会大量使用宏,但是在自己的项目中,宏的使用不是必须的。不过从学习的角度来看,宏是必须掌握的,只是优先级比较低,因为不掌握它有时很难看懂一些成熟的 Rust 项目。宏的学习我推荐 《Rust 宏小册》。
经验二:刚开始学习时,不要试图一遍记住某个知识点的所有内容,只要做到记住这个知识点大概是做什么的,有什么能力即可。
在学习 Rust 语法阶段,如果看每个知识点都试图完全理解的话,那是非常痛苦的,也是不现实的。因为Rust 的很多语法很复杂,只有在实践中才能真正领会。所以在这个阶段不要在一个知识点上死磕,学习时只要知道:大概有这么个东西,它大概是怎么用的,它的资料在哪里就够了。
不同的知识点联动起来才有意义,才能体现出作用,才能更好地被记住。而联动的最佳方式是带着目的和需求,不断地复习、实践,反复多次,才能彻底掌握。在我看来,这就是学习 Rust 最高效的方式。
经验三:在深入学习时,一定要学习和实践反复切换着来,在写的同时不断地反复去回顾前面的知识点。
相信大多数人会遇到类似的问题,在学完了基础语法后,好像懂了,又好像什么都不懂。然后可能有人就放弃了。
在完成基础学习的阶段后,最需要的是选择一个适合自己的项目来提升 Rust 编程的功力。现在业界有很多简单的项目可以练习,比如编写命令行工具、Web Server、简单的 KV 存储。
但这类项目很难让我们彻底熟练地掌握 Rust。 因为它不是一个真正意义上的业务需求,很难将 Rust 那些核心特性、语法用上,并且做到精益求精。
此时最好的方式是找一个成熟的开源项目,学习它的实现,参与它的工作,跟着它一起成长。但最大的问题是:开源项目往往比较复杂,参与起来需要投入大量精力,并且很多任务并不适合初学者。 这也是本系列课程希望解决的问题。
经验四:不仅仅是 Rust。保持耐心,带着目的去学习。用好工具。
想学好 Rust,就不应该将它仅仅看作是学习 Rust。我们要知道,Rust 只是一门编程语言,说白了,它也只是一个工具,你可以把它理解为一个做木工的锤子。通常意义上说,学习 Rust,就是学习它的基础语法、特性、语法糖,也就是去学这个锤子本身怎么用。
而真正能做好家具,还得配合其他计算机领域的知识点。所以在学习 Rust 的过程中,我们会自然而然地接触到网络、存储、操作系统、分布式系统设计等等这些知识点。你要学会 Rust 本身,并且学会这些相关知识点,才算真正学会 Rust。
最重要的是,在学习 Rust 的时候,你一定一定要保持耐心。我个人从开始学习 Rust 到真正有入门的体验,大概花了四个月的时间。这四个月是在保持平均每天至少有两个小时的投入,带着问题和目的去学习的状态下。作为一个老研发,这是让我比较惊讶的一点,因为之前我对一门新语言的定义是,学个两三天就能产出了。
另外,就是善于利用现有的一些平台和工具。在今天,Rust 的资料和开源项目已经比较齐全了。我给你推荐两个常用的工具和相关论坛。
-
Crates.io:这是各种 Rust 开源库的管理平台,类似 Java 的 Maven。这里每个仓库都有非常详细的说明和示例。另外有个小技巧是,如果在 Crates.io 对某个库没有详细说明,那么就可以直接跳转到库对应的 GitHub 仓库。一个成熟的开源库,在 GitHub 仓库都会有很详细的使用说明。
-
awesome-rust:这是一个 Rust 成熟开源项目的集合索引项目,它整合了 Rust 领域有影响力的项目。你可以在这里找到自己感兴趣的项目,把源码下载下来,学习它们的语法和实现方式。看成熟项目的代码,是一个效率很高的学习方式,也是我常用的。因为在学习了很多知识点后,其实很难一下子去融会贯通,而看别人写的代码,再通过这些写法去理解这些语法,效率就很高。
比如看到这段代码,你会想到什么呢?
#![allow(unused)] fn main() { async fn report_broker_sysdescr<S>( client_poll: &Arc<ClientPool>, metadata_cache: &Arc<CacheManager>, message_storage_adapter: &Arc<S>, ) where S: StorageAdapter + Clone + Send + Sync + 'static, { let topic_name = replace_topic_name(SYSTEM_TOPIC_BROKERS_SYSDESCR.to_string()); let info = format!("{}", os_info::get()); if let Some(record) = MQTTMessage::build_system_topic_message(topic_name.clone(), info) { write_topic_data( &message_storage_adapter, &metadata_cache, &client_poll, topic_name, record, ) .await; } } }
你需要看懂这段代码使用了哪些Rust 语法,比如 Arc、where、S、&等等。
- Rust 语言中文社区 和 Rust 官方论坛:这是我经常逛的两个 Rust 论坛。一个是国内中文的论坛,基本可以了解到国内 Rust 这个领域最新发生的一些事情,看看大家都在做什么。一个是 Rust 官方的英文论坛,里面会有很多 Rust 语言本身的比如特性、Bug 等相关的讨论。如果想学好 Rust,建议养成日常浏览这两个论坛的习惯,毕竟抬头看天,看一下业界都在做什么是很重要的。
希望这些经验之谈,能为你学好 Rust 这门语言扫清一些障碍。同时,这门课程其实也是在记录我通关的过程,基于我所走过的弯路,经过系统的梳理和总结,并结合真实的工程实践,去拉平 Rust 的学习曲线。
不妨先体验一下,我们用一个 Trait 的例子来入门 Rust 编程。
从一个 Trait 的例子开始
下面这个代码是一个实际的业务需求。
在持久化存储数据的时候,数据存储需要支持不同的存储引擎,比如 Redis、本地文件、MySQL 等等。此时如何用 Rust 来实现这个存储层,适配不同类型的存储,该怎么写?再加一个条件,这个存储层需要能在多线程环境下运行。
接下来,我们看一下这个适配多个存储引擎的存储层的主要代码。你要重点关注 build_driver 方法。
- 定义 AuthStorageAdapter Trait
#![allow(unused)] fn main() { pub trait AuthStorageAdapter { async fn read_all_user(&self) -> Result<DashMap<String, MQTTUser>, MQError>; async fn get_user(&self, username: String) -> Result<Option<MQTTUser>, MQError>; } }
- AuthStorageAdapter 的实现:PlacementAuthStorageAdapter
#![allow(unused)] fn main() { pub struct PlacementAuthStorageAdapter { } impl PlacementAuthStorageAdapter { pub fn new() -> Self { return PlacementAuthStorageAdapter {}; } } #[async_trait] impl AuthStorageAdapter for PlacementAuthStorageAdapter { async fn read_all_user(&self) -> Result<DashMap<String, MQTTUser>, RobustMQError> { return Ok(DashMap::with_capacity(2)); } async fn get_user(&self, username: String) -> Result<Option<MQTTUser>, RobustMQError> { return Ok(None); } } }
- AuthStorageAdapter 的实现:MySQLAuthStorageAdapter
#![allow(unused)] fn main() { pub struct MySQLAuthStorageAdapter { } impl MySQLAuthStorageAdapter { pub fn new() -> Self { return PlacementAuthStorageAdapter {}; } } #[async_trait] impl AuthStorageAdapter for MySQLAuthStorageAdapter { async fn read_all_user(&self) -> Result<DashMap<String, MQTTUser>, RobustMQError> { return Ok(DashMap::with_capacity(2)); } async fn get_user(&self, username: String) -> Result<Option<MQTTUser>, RobustMQError> { return Ok(None); } } }
- build_driver 方法:通过 Arc<dyn AuthStorageAdapter + Send + 'static + Sync> 返回一个可以在多线程间共享的 AuthStorageAdapter Trait 实现
#![allow(unused)] fn main() { pub fn build_driver() -> Result<Arc<dyn AuthStorageAdapter + Send + 'static + Sync>, RobustMQError> { if storage_is_placement(&auth.storage_type) { let driver = PlacementAuthStorageAdapter::new(); return Ok(Arc::new(driver)); } if storage_is_mysql(&auth.storage_type) { let driver = MySQLAuthStorageAdapter::new(); return Ok(Arc::new(driver)); } return Err(RobustMQError::UnavailableStorageType); } }
上面这段代码,我们先不展开细讲,后续课程都会涉及。但我可以先告诉你,我们的代码中都使用了哪些 Rust 知识点。
- Rust 基础语法(变量、类型、函数、流程控制等)
- 特征 Trait
- 智能指针 Arc、Box
- 特征对象 Dyn
- 生命周期-静态变量 'static
- 多线程编程 Send、Sync
短短的这么一段代码,几乎就囊括了 Rust 语法的核心部分。你看,这就是动手实践的意义!
总结
这节课我分享了最终作品的架构是什么样子的,明确了我们在系列课程的第一阶段要完成的元数据服务(也就是类 ZooKeeper 的分布式协调服务)的系统架构。同时也分享了很多我在学习实践 Rust 过程中的经验。
最后我想强调的是,学习 Rust 的最好方式是带着目的去学习,以终为始。通过需求来组合各个知识点,不要死记硬背,更不要抄代码,要先理解需求,理解 Rust 语法,然后再去写代码。
思考题
课程中的 build_driver 这段代码是什么意思?重点解释:Result<Arc<dyn AuthStorageAdapter + Send + 'static + Sync>, RobustMQError> 这句代码的作用。
#![allow(unused)] fn main() { pub fn build_driver( client_poll: Arc<ClientPool>, auth: Auth, ) -> Result<Arc<dyn AuthStorageAdapter + Send + 'static + Sync>, RobustMQError> { return Err(RobustMQError::UnavailableStorageType); } }
期待你的分享,如果今天的课程对你有所帮助,也欢迎你转发给有需要的同学,我们下节课再见!
做好准备:写一个基础软件需要掌握哪些Rust知识点?
本课程为精品小课,不标配音频
你好,我是文强。
从这节课开始,我们正式进入实践落地阶段。为了能让你更好地理解本课程后续的内容,我会先带你了解写一个分布式基础软件所需要用到的 Rust 关键知识点。
Tips:这节课只是起到一个“引导点明”的作用,不会详细展开讲解各个知识点。建议你先根据上节课推荐的资料把 Rust 的相关知识点都过一遍,再来看这节课的内容,会更好理解。
接下来,我整理了一个常用的 Rust 知识点集合(这个信息来源于多份学习资料,我只是做了一下总结)。你可以根据表格来看一下自己对 Rust 的掌握程度,然后查缺补漏。
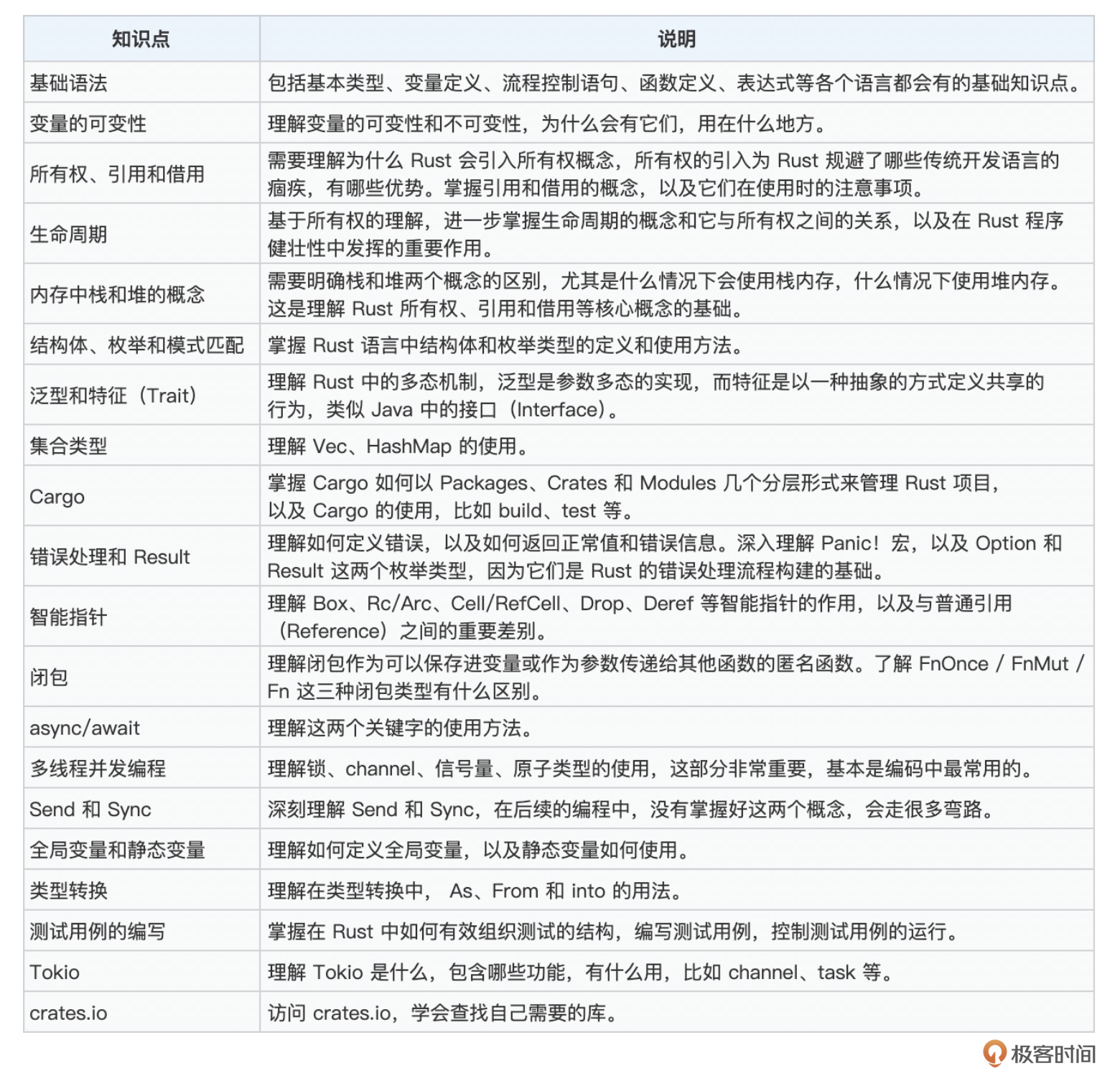
基于上面的表格,接下来我们重点讲一下在编码过程中最常用到且在理解上有一定挑战的几个知识点。
- 包管理工具:Cargo
- 生命周期和所有权
- 泛型和Trait
- 智能指针
- 并发编程和Tokio
- 测试用例
包管理工具:Cargo
无论是哪份学习资料,都会告诉你 Cargo 的重要性。在我看来 Cargo 是 Rust 的核心竞争力之一,是学习 Rust 必须完整掌握的知识点。想要学好 Cargo 看这份资料即可 《Cargo 使用指南》。
在 Cargo 里面重点关注以下三个命令,掌握后基本就入门了。
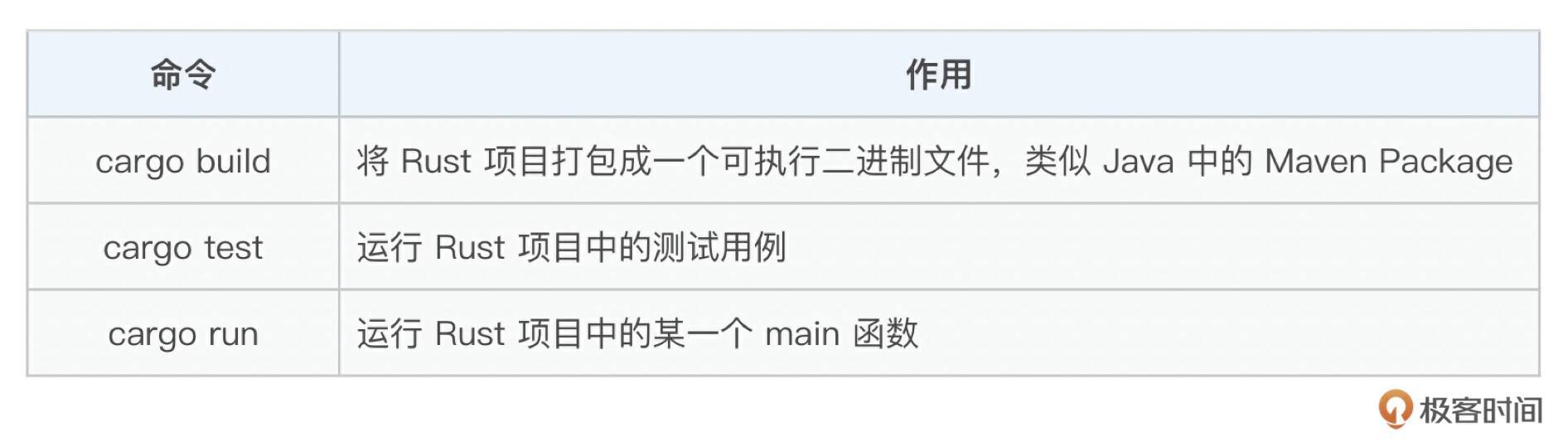
使用示例如下:
# 用 cargo build 根据 release 标准将项目打包成一个可执行的二进制文件
cargo build --release:
# 运行名为 mqtt-broker 的这个模块里面的测试用例
cargo test --package mqtt-broker
# 执行 cmd 包中名字为 placement-center 的 bin 的 main 函数,并给这个main函数传递conf参数
cargo run --package cmd --bin placement-center -- --conf=config/placement-center.toml
接下来通过真实项目中的两个 cargo.toml 来看一下如何编写 cargo 文件。
- 文件1
#![allow(unused)] fn main() { [workspace] members = [ "src/mqtt-broker" ] resolver = "2" [workspace.package] version = "0.0.1" edition = "2021" license = "Apache-2.0" [workspace.dependencies] serde = { version = "1.0", features = ["derive"] } # workspaces members mqtt-broker = { path = "src/mqtt-broker" } }
- 文件2
[package]
name = "cmd"
version.workspace = true
edition.workspace = true
license.workspace = true
default-run = "robustmq"
[[bin]]
name = "mqtt-server"
path = "src/mqtt-server/server.rs"
[dependencies]
serde.workspace = true
上面这两个文件,第一个文件是项目根目录的 cargo.toml,用处是导入依赖、组织管理子项目。第二个是子项目的cargo.toml,它是一个可执行的package,依赖父项目workspace的管理。文件内出现了以下四个知识点:
-
Cargo 中 Workspace 的使用。包括根项目中 workspace 的使用,子项目基于 workspace 特性管理依赖、版本信息等。
-
Cargo package 的定义(包括命名、版本、license)。
-
Cargo package bin 的用法。
这里就不详细展开说明每个细节了,如果你看不懂上面的语法,就完整看一下 《Cargo 使用指南》。如果你能看懂上面两个文件,说明你对 Cargo 的理解就差不多了。接下来就是在实际项目中使用 Cargo 的 build、run、test 命令看一下效果了。
接下来,来看看 Rust 的生命周期和所有权。
生命周期和所有权
可以说 Rust 这个语言的核心就是 生命周期 和 所有权 了。基本所有的语法点都是围绕这两个点来组织的。写好 Rust 代码的关键就是把这两个点理解透。这两个特性有关的知识点太多,我主要讲一下我们在实际编码中,主要会涉及的5个重点。
- 变量的可变性和不可变性。意思是 Rust 在定义变量的时候就需要指明它是否能够被修改,来看下面这个代码示例。
#![allow(unused)] fn main() { let x = 1; # 变量 x 不能被修改 let mut y = 1 # 变量 y 能被修改 }
上面代码中的 mut 关键字就是表示,这个变量能不能被修改,默认情况下变量是不能被修改的。所以在实际编码过程中,你会看到很多这样的代码写法:
#![allow(unused)] fn main() { pub struct ClientKeepAlive { stop_send: broadcast::Sender<bool>, } impl ClientKeepAlive { pub async fn start_heartbeat_check(&mut self) { loop { let mut stop_rx = self.stop_send.subscribe(); select! { val = stop_rx.recv() =>{ ...... } } } } } }
上面代码的核心是:&mut self 的使用,表明可以通过 mut self 来获取对象的可变属性,并修改它。而如果不需要修改,则改为 &self 即可。了解更多可以看 《变量绑定与解构》 这个资料。
Tips: 变量可变/不可变的特性是 Rust 安全性的一个重要来源。默认情况下变量都是不可变的,只有手动定义了mut 后,数据才能被修改。这样可以保证数据不会在某些地方被莫名修改,从而保证了数据的安全。
对于变量的可变性,再推荐一个在日常开发中会大量使用到的开发库 《DashMap》。它是HashMap 的替代品,我们在日常开发中会大量用 HashMap 来存储数据。此时就会大量用到类似 Arc<RwLock<HashMap<String,String>>> 的语法,这个用法很繁琐,性能也很低。此时可以使用DashMap来替代这个语法的使用。
- 变量的所有权和借用。Rust 语言能够没有GC(垃圾回收),其所有权特性的设计功不可没。关于 Rust 为什么可以没有 GC,你可以看 《所有权和借用》 和 《Drop 释放资源》 这两份资料来理解。
在实际编码中,所有权和借用特性主要体现在 clone() 和 & 两个语法的使用。来看个例子:
#![allow(unused)] fn main() { pub fn is_system_topic1(topic_name: String) -> bool { return true; } pub fn is_system_topic2(topic_name: &String) -> bool { return true; } let topic_name = "test".to_string(); is_system_topic1(topic_name.clone()); is_system_topic1(topic_name.clone()); is_system_topic2(&topic_name); is_system_topic2(&topic_name); }
上面定义了 is_system_topic1 和 is_system_topic2 两个方法,传递参数分别是 String和 String的引用。is_system_topic1 是把 topic_name 的所有权转移到函数中,is_system_topic2 传递了一个topic_name的引用到函数中,没有转移函数的所有权。
所以在编码中,你会大量用 clone 和 &(引用) 语法。那在编码中,什么时候用什么语法呢?来看它们在编码层面的主要区别。
-
传递引用:在多线程的环境下或者使用对象(struct)时,因为生命周期的限制,就会产生很复杂的问题,会大大增加编码的复杂度(这点会在后面的实践中展开讲,让你体会更深)。一些情况下可能还需要引入“生命周期约束”的特性。此时就需要用到所有权的转移,或者通过引入智能指针 Arc 来实现一个变量有多个所有者。
-
所有权转移:这个是最简单的用法,在每次参数传递时,都创建变量的副本,当数据较大时,会比较消耗性能。从语法上看会大量类似 xx.clone() 语法,不太友好。
所以在实践中: 建议默认优先使用引用,需要在多线程间传递数据的时候再使用clone()。
- 静态/全局变量:在实际编码中会大量用到静态和全局变量。而在生命周期和所有权的机制中,静态和全局变量的使用就变得比较复杂。相关资料可以看 《静态变量》、 《全局变量》 这两个文档。从学习的角度,只要会用就可以,底层的原理主要还是围绕生命周期来展开。来看个具体使用的例子:
#![allow(unused)] fn main() { 通过static 定义一个静态变量 static CONNECTION_ID_BUILD: AtomicU64 = AtomicU64::new(1); 通过 const 定义一个静态常量 pub const REQUEST_RESPONSE_PREFIX_NAME: &str = "/sys/request_response/"; }
再推荐一个定义静态变量经常会用到的库 《库 lazy_static》,因为静态变量是在编译期初始化的,因此无法使用函数调用进行赋值,而lazy_static允许我们在运行期初始化静态变量。
#![allow(unused)] fn main() { 通过lazy_static 动态定义静态变量 lazy_static! { static ref BROKER_PACKET_NUM: IntGaugeVec = register_int_gauge_vec!( "broker_packet_num", "broker packet num", &[ METRICS_KEY_MODULE_NAME, METRICS_KEY_PROTOCOL_NAME, METRICS_KEY_TYPE_NAME, ] ) } }
-
生命周期约束:生命周期约束是一个用得比较少,但是需要重点学习的特性。因为在某些情况下,只能用它来解决问题。详细资料可以看这个文档 《生命周期约束》。在实际编码中,生命周期约束主要用在标注引用的生命周期。 从实践的角度,建议能不用生命周期约束就不用,一般需要用到生命周期约束的地方都会有替换方案。
-
《生命周期》 和 《认识生命周期》:这两章可以放最后看,讲得比较晦涩,编码上用得少,不过加深对生命周期的理解有好处,建议你稍微看一下。
接下来,来看一下泛型和 Trait。在实际业务场景中,我们会频繁遇到需要使用泛型和Trait的场景。
泛型和 Trait
关于泛型和 Trait,你主要看这两个资料: 《泛型》 和 《特征 Trait》。看完这两篇基本就入门了。需要重点关注以下知识点:
-
泛型:泛型的定义,泛型的约束,泛型如何进行参数传递。
-
特征:特征定义,特征的实现,特征约束,特征对象,以及特征对象如何在多线程传递。
接下来通过两个例子,看一下在实际编码中,会怎么用这两个知识点。 只要你能完全理解这两段代码想表达的意思,那你对于泛型和 Trait 的了解基本就没问题了。
- 泛型
#![allow(unused)] fn main() { #[async_trait] pub trait StorageAdapter { // Streaming storage model: Append data in a Shard dimension, returning a unique self-incrementing ID for the Shard dimension async fn stream_write( &self, shard_name: String, data: Vec<Record>, ) -> Result<Vec<usize>, RobustMQError>; } pub struct MessageStorage<T> { storage_adapter: Arc<T>, } impl<T> MessageStorage<T> where T: StorageAdapter + Send + Sync + 'static, { pub fn new(storage_adapter: Arc<T>) -> Self { return MessageStorage { storage_adapter }; } // Save the data for the Topic dimension pub async fn append_topic_message( &self, topic_id: String, record: Vec<Record>, ) -> Result<Vec<usize>, RobustMQError> { let shard_name = topic_id; match self.storage_adapter.stream_write(shard_name, record).await { Ok(id) => { return Ok(id); } Err(e) => { return Err(e); } } } }
上面这段代码定义了名为 StorageAdapter 的 Trait,然后定义名为 MessageStorage 的对象,MessageStorage 包含一个变量 storage_adapter 是一个泛型。这段代码的重点是对变量storage_adapter的泛型约束:where T: StorageAdapter + Send + Sync + 'static。表示这是一个泛型,这个泛型需要满足 StorageAdapter + Send + Sync + 'static 四个约束。
然后在 MessageStorage 的方法中,append_topic_message 使用泛型约束StorageAdapter的方法 stream_write。
- Trait
#![allow(unused)] fn main() { #[async_trait] pub trait AuthStorageAdapter { async fn read_all_user(&self) -> Result<DashMap<String, MQTTUser>, RobustMQError>; } pub struct AuthDriver { driver: Arc<dyn AuthStorageAdapter + Send + 'static + Sync>, } impl AuthDriver { pub fn new(cache_manager: Arc<CacheManager>, client_poll: Arc<ClientPool>) -> AuthDriver { let driver = match build_driver() { Ok(driver) => driver, Err(e) => { panic!("{}", e.to_string()); } }; return AuthDriver { driver: driver, }; } pub async fn read_all_user(&self) -> Result<DashMap<String, MQTTUser>, RobustMQError> { return self.driver.read_all_user().await; } } }
上面这段代码在上节课就出现过,其定义了名为AuthStorageAdapter的Trait和名为AuthDriver的 Struct,通过build_driver方法构建Trait的不同实现,通过Arc<dyn AuthStorageAdapter + Send + 'static + Sync> 实现变量在不同线程间的传递。
接下来我们来看看Rust中的智能指针。
智能指针
只要写 Rust 代码,智能指针基本就是最常用的特性之一,你如果没用到,那就说明你的项目不是一个真正的生产项目。要了解智能指针的详细信息,看这个资料 《智能指针》 即可。
Rust 中包含了丰富的智能指针,包括 Box、Rc/Arc、Cell/RefCell、Drop、Deref 等等。在实际编码中,我们最常用的是 Box、Rc/Arc、Cell/RefCell 三类,来看下它们各自的作用。
- Box
智能指针 Box 的核心功能是允许 将一个值分配到堆上,然后返回一个指针指向堆上的数据。从实际作用上来看,主要有以下3个使用场景:
-
将数据分配在堆上,比如在数据较大时,不想在转移所有权时进行数据拷贝。
-
类型的长度在编译期无法确定,但是在变量定义时又需要知道类型的长度时。
-
特征对象,用于说明对象实现了一个特征,而不是某个特定的类型。
上面第 1 点,直接将数据固定在堆上听起来很抽象,有啥用呢?举个例子。
在消息队列中,服务端 Server 需要大量接收客户端数据进行处理和保存。当数据很大时(比如 10MB),在数据转移所有权过程中,需要大量拷贝数据,此时数据太大,拷贝就需要消耗大量性能。
正常情况下,我们可以通过下面的结构体 RequestPackage 来传递数据,客户端的数据放在 packet 属性里面。
#![allow(unused)] fn main() { #[derive(Clone, Debug)] pub struct RequestPackage { pub connection_id: u64, pub addr: SocketAddr, pub packet: MQTTPacket, } }
如果 packet 太大,则会严重影响性能。此时可以把代码改为:
#![allow(unused)] fn main() { #[derive(Clone, Debug)] pub struct RequestPackage { pub connection_id: u64, pub addr: SocketAddr, pub packet: Box<MQTTPacket>, } }
改完后,packet 只是一个Box指针,不包含实际的数据体,所以在转移所有权拷贝数据过程中,拷贝的是引用指针数据,此时就可以避免在转移所有权过程中因数据太大而带来的性能问题。
2和3属于一个类型,属于 Box 的用法,本质上来看,也是将数据固定在堆上,返回一个引用。这个资料可以参考 《特征对象》。
- Rc/Arc
解决Rust中一个值在同一时刻只能有一个所有者的问题,即 允许一个值在同一时刻拥有多个所有者。如果你对 Rust 的所有权机制有足够了解,则很容易理解这句话的意思。如果不理解,可以看一下前面提到的《生命周期和所有权》部分。
从实际编码中,Rc 用得相对比较少,基本用的都是 Arc。因为 Rc 用于单线程,Arc 用于多线程。而在实际业务中,基本都是多线程编程。所以你需要重点了解 Arc 的用法,主要参考这份资料 《Rc 与 Arc 实现 1vN 所有权机制》。
下面来看一段 Arc 经典使用案例的代码。
#![allow(unused)] fn main() { pub struct MqttBroker { subscribe_manager: Arc<SubscribeManager>, connection_manager: Arc<ConnectionManager>, } impl MqttBroker { pub fn new( client_poll: Arc<ClientPool>, cache_manager: Arc<CacheManager>, ) -> Self { let subscribe_manager = Arc::new(SubscribeManager::new( cache_manager.clone(), client_poll.clone(), )); let connection_manager = Arc::new(ConnectionManager::new(cache_manager.clone())); return MqttBroker { subscribe_manager, connection_manager, }; } } }
这段代码的意思是,我们定义两个 subscribe_manager 和 connection_manager 分别来管理消息队列的订阅和连接数据。在实际场景中,这两个数据都需要在不同的线程中被操作(比如读取和写入)。此时如果不用智能指针 Arc,则 SubscribeManager 和 ConnectionManager 这两个 struct 是不能在多线程共享的。
简单来说就是: 如果一个数据要在多线程间共享,就必须使用 Arc。
- Cell/RefCell
通过学习所有权的部分,我们知道在 Rust 的定义中: 一个变量同时只能拥有一个可变引用或多个不可变引用,不能既拥有一个可变引用,又拥有多个不可变应用。在实际编码中,这个语法会给我们带来很大的限制,导致我们无法实现某些功能或大大增加实现成本。
Tips:提醒一下,不要一开始就用 Rust 去写 LeeCode 的数据结构算法,会写到怀疑人生。其中一个很大原因就是上面这个限制。
所以 Rust 提供了智能指针 Cell/RefCell 来绕过这个限制,即: 通过 Cell/RefCell 可以在拥有不可变引用的同时修改目标数据。简单来说就是, 变量可以在拥有不可变引用的同时拥有可变引用。
在看到这个语法时,我的第一反应是,这不是绕过了 Rust 的安全机制吗?一个变量可以同时读和写,会降低 Rust 的安全性吧。如果你也这样想,就表示你对 Rust 的所有权和安全性的理解是不错的。
是的,就是会有这个问题。那为什么还有这个语法呢?
主要原因是,编译器不可能做到尽善尽美,太死的限制会导致我们编码遇到很大的问题(在我看来,限制太多是导致 Rust 学习曲线陡峭的主要原因之一)。而当你对自己代码很有信心时,你就可以通过 Cell 和 RefCell 来绕过所有权的限制。所以 用这个语法后你需要自己保证数据的安全性。
因此这个语法在实际业务类编码当中用得比较少,反而在一些基础库中是一个常见用法。在我们要实现某些很基础功能的时候,你应该就会用到它。对它有兴趣,你可以看 《Cell 与 RefCell 内部可变性》,再去看看这个库 《DashMap》 的源码。
接下来我们来看看并发编程和 Tokio。
异步编程和 Tokio
在任何语言中,并发编程都是语言的核心,在 Rust 中也是一样的。从学习资料的角度,建议你先看 《async/await 异步编程》,然后再看这两个资料 《Tokio 官网》 和 《Rust 异步编程和 Tokio 框架》,基本就对 Rust 异步编程有个大概的了解了。这三份资料大部分在讲异步编程的底层原理,目的是帮助你更好地理解 Rust 异步编程,这部分反复看到能理解就可以。
从实际编码的角度,使用方式很简单,主要就是对 async、await、tokio 的使用。从功能上看,这三者的关系是: async 定义异步代码块,然后在 Tokio(Runtime)里面调用代码块的 .await 方法,运行这个异步任务。
接下来来看一段实际的业务代码。
#![allow(unused)] fn main() { let runtime = create_runtime( "storage-engine-server-runtime", conf.system.runtime_worker_threads, ); pub async fn report_heartbeat(client_poll: Arc<ClientPool>, stop_send: broadcast::Sender<bool>) { loop { let mut stop_recv = stop_send.subscribe(); select! { val = stop_recv.recv() =>{ match val{ Ok(flag) => { if flag { debug(format!("Heartbeat reporting thread exited successfully")); break; } } Err(_) => {} } } _ = report(client_poll.clone()) => { } } } } runtime.spawn(async move { report_heartbeat(client_poll, stop_send).await; }); }
在上面的代码中:
-
通过 create_runtime 创建一个 Tokio Runtime。
-
通过 async 定义一个名为 report_heartbeat 的异步运行的函数。这个函数的功能是定时上报心跳。
-
将report_heartbeat函数放在 Runtime 里面运行,Runtime 里面再通过.await 方法驱动异步任务运行。
这段代码是经典的Rust 异步编程的实现,其他的实现基本都是这段代码的变种。 在实际编码中,你还需要重点理解一下 Rust 闭包的用法,经常会用到。具体可以看这个资料 《闭包 Closure》。
在上面的例子中,异步任务是运行在 Tokio Runtime 中的。接下来通过一张图,来理解一下 Tokio 是什么,以及 Rust 异步编程(async/await)和 Tokio 的关系。
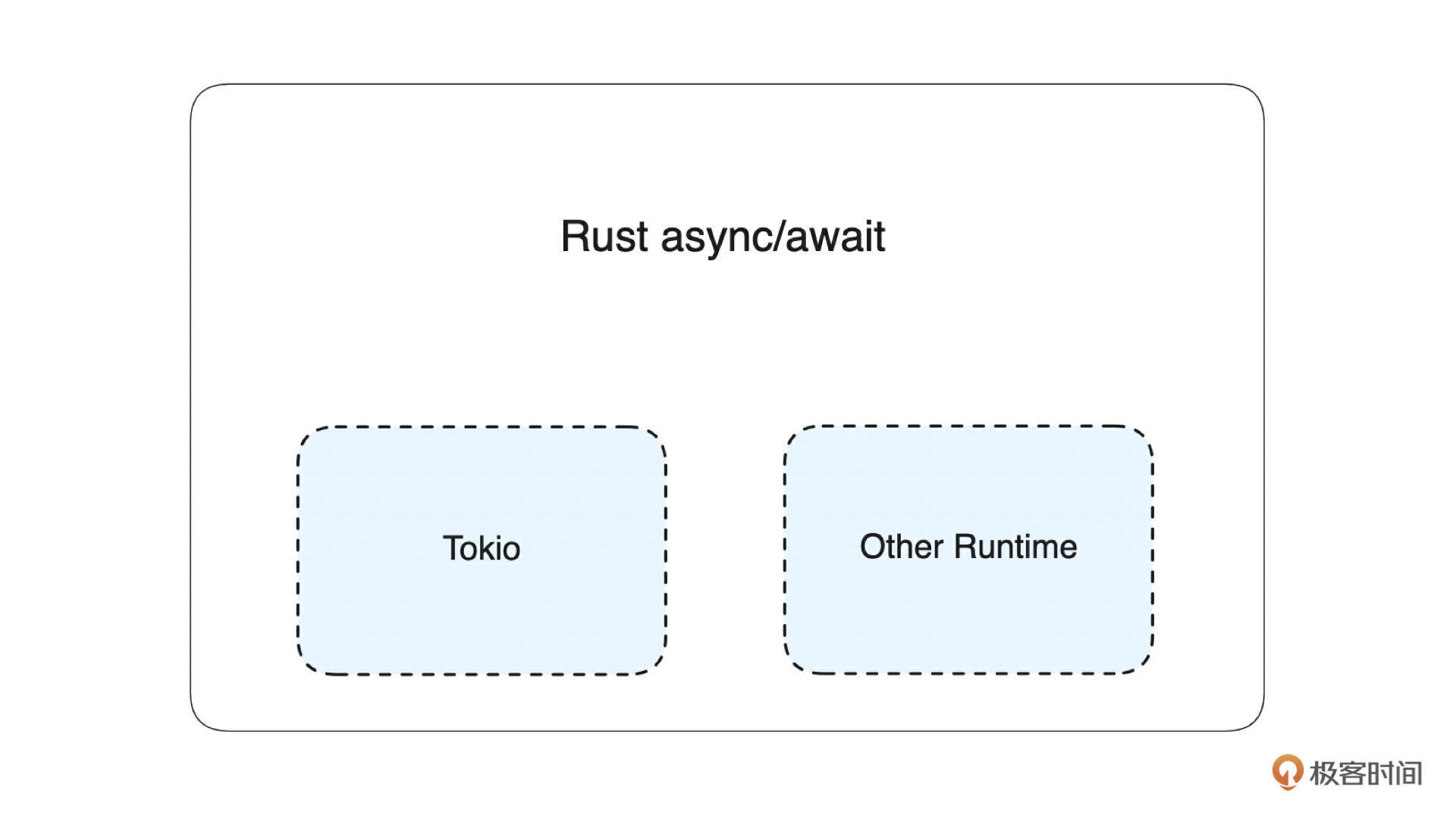
如上图所示,Tokio(Runtime)是 Rust 异步编程的一种实现。在 Rust 中,官方是没有提供给异步任务运行的地方(也就是 Runtime),是依赖社区提供的 Runtime,比较主流的实现有 Tikio、async-std 等等。 随着社区的发展,Tikio 是实现最好 、 性能最高的一个,逐步成为了唯一的选择。
Tokio 是一个生态,Runtime只是它的一部分。它还包含下面这些生态库(详细信息看 Tokio 官网):
-
Hyper:支持 HTTP 1 和 2 协议的 HTTP 客户端和服务器库。
-
Tonic:gRPC 客户端和服务器库。
-
Tower:用于构建可靠客户端和服务器的模块化组件,包括重试、负载平衡、过滤、请求限制功能等。
-
Mio:操作系统事件 I/O API 之上的最小可移植 API。
-
Tracing:对应用程序和库的统一洞察,提供结构化、基于事件的数据收集和记录。
-
Bytes:网络应用程序的核心是操作字节流,Bytes 提供了一组丰富的实用程序来操作字节数组。
从编码常用功能的角度,Tokio 还实现了异步版本的 channel、 Mutex 、 RwLock 、 Notify 、 Barrier 、 Semaphore 等实现,来提供线程间的数据通信以及状态同步、协调等等。其中 channel 和 lock 在编码过程中会大量用到,这块需要重点学习。
从学习 Tokio 的角度看,你首先要理解它的 Runtime 实现,然后再根据自己的需要了解对应的生态库,然后在编码中领会 Tokio 各种 channel 和 lock 等的使用。
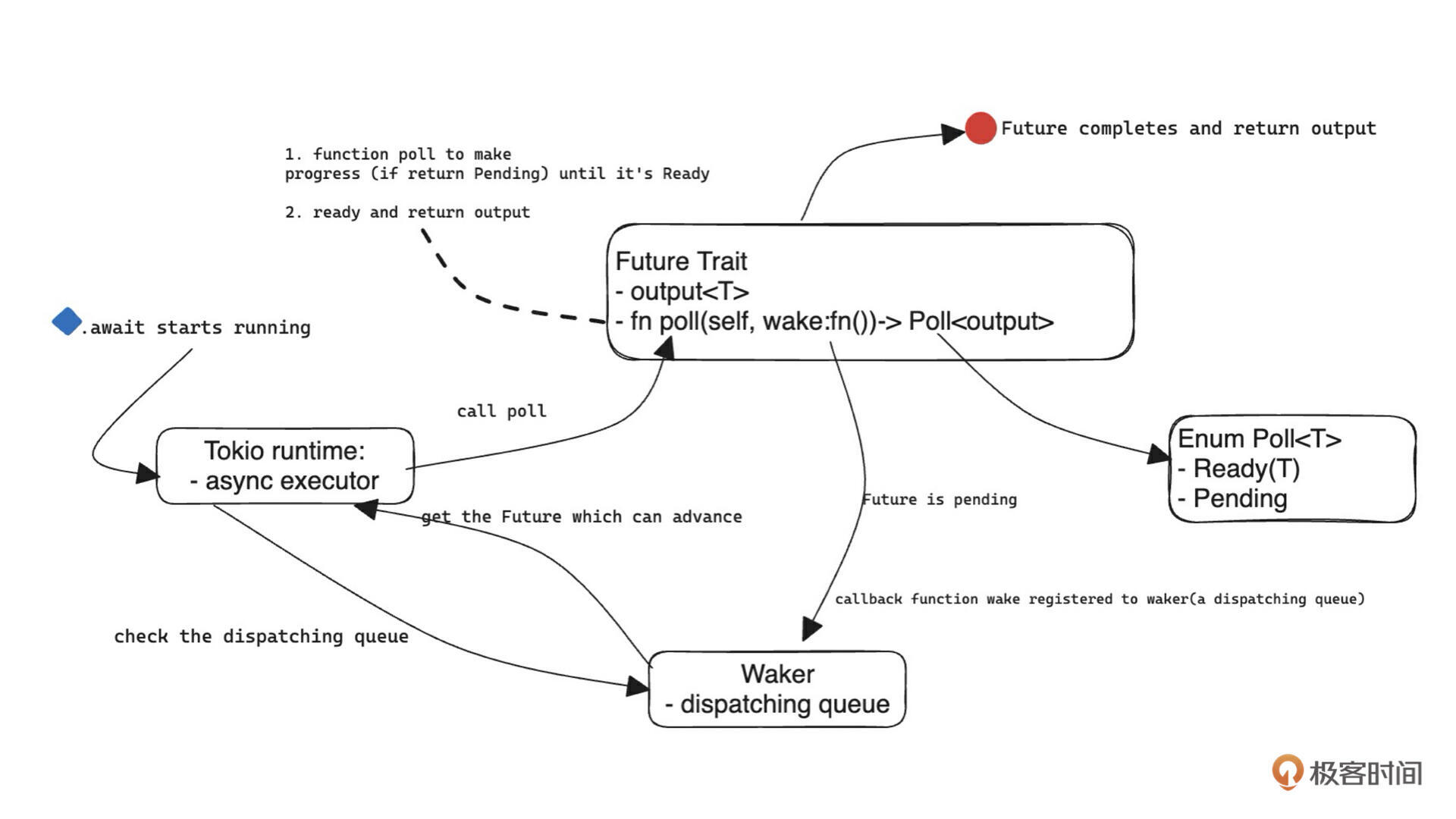
最后,放一张 Tokio 内核运行原理的架构图。你可以结合上面推荐的资料来理解它,这里就不展开了。
最后,再来看看测试用例。
测试用例
Rust 的测试用例从语法上看比较简单,主要关注 assert_eq! 和 assert! 两个语法,就不展开讲了,详细资料可以参考这个文档 《自动化测试》。测试用例的核心操作是通过 assert 来判断数据是否符合预期,比如:
#![allow(unused)] fn main() { assert_eq!(res.len(), 2); # 判断res 的长度是否等于 2,等于 2 就成功,不等于 2 就失败 assert!(!res.is_none()); # 判断 res 是否为 none }
在实际场景中, 写测试用例关注的主要不是语法,而是如何写一个好的测试用例来验证我们的代码逻辑是没问题的。 那怎么写呢?来看个实际的例子。
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use std::sync::Arc; use crate::storage::mqtt::topic::MQTTTopicStorage; use crate::storage::rocksdb::RocksDBEngine; use common_base::config::placement_center::PlacementCenterConfig; use metadata_struct::mqtt::topic::MQTTTopic; #[tokio::test] async fn topic_storage_test() { let mut config = PlacementCenterConfig::default(); config.data_path = "/tmp/tmp_test".to_string(); config.data_path = "/tmp/tmp_test".to_string(); let rs = Arc::new(RocksDBEngine::new(&config)); let topic_storage = MQTTTopicStorage::new(rs); let cluster_name = "test_cluster".to_string(); let topic_name = "loboxu".to_string(); 1. 保存数据 let topic = MQTTTopic { topic_id: "xxx".to_string(), topic_name: topic_name.clone(), retain_message: None, retain_message_expired_at: None, }; topic_storage .save(&cluster_name, &topic_name, topic) .unwrap(); 2. 保存数据 let topic_name = "lobo1".to_string(); let topic = MQTTTopic { topic_id: "xxx".to_string(), topic_name: topic_name.clone(), retain_message: None, retain_message_expired_at: None, }; topic_storage .save(&cluster_name, &topic_name, topic) .unwrap(); 3. 判断是否写入两条数据 let res = topic_storage.list(&cluster_name).unwrap(); assert_eq!(res.len(), 2); let res = topic_storage .get(&cluster_name, &"lobo1".to_string()) .unwrap(); assert!(!res.is_none()); 4. 删除一条数据 let name = "lobo1".to_string(); topic_storage.delete(&cluster_name, &name).unwrap(); 5. 判断数据是否存在 let res = topic_storage .get(&cluster_name, &"lobo1".to_string()) .unwrap(); assert!(res.is_none()); } } }
这是一个很典型的测试用例。其功能是:判断 MQTTTopicStorage 这个对象中的数据增删改查的代码行为是否符合预期。在代码中,第 1 和 2 步,保存了两行数据,第3 步判断是否成功写入两条数据,第4步删除数据,第5步判断数据是否删除成功。通过这五个步骤,完成了逻辑验证的闭环。
这段代码的核心是通过不同的 assert 操作来验证逻辑的闭环。而这也是我们写测试用例的目标。所以我们在写测试用例的时候,重要的是 逻辑闭环,即能够通过获取各个操作的结果,来判断行为是否符合预期。
关于在实际业务中,如何通过集成测试来保证代码质量,我们后面再详细展开讲。
总结
这节课我们挑了几个在写分布式应用过程中需要重点了解的知识点来展开讲。内容相对比较精简,但都给了对应的资料地址,当你对知识点有疑惑时,应该跳转到对应的资料去看。只要能看透,基本就能掌握相关知识点。
不过要想用 Rust 真正写一个工业应用,你还得把课程开头的《Rust 知识点集合》100% 掌握才行。Rust 是一门学习成本较高的语言,就是需要你反复地去学习和体会各个语法和特性。
思考题
你觉得我们的《Rust 知识点集合》还缺少哪些内容呢?
欢迎补充,如果今天的课程对你有所帮助,也欢迎你转发给有需要的同学,我们下节课再见!
正式开工:如何组织、编译、打包复杂的Rust项目?
本课程为精品小课,不标配音频
你好,我是文强。
这节课开始,我们就正式来写消息队列架构中的元数据集群部分。首先我们需要初始化一个项目,接下来我会详细讲解如何组织项目结构,以及如何编译打包 Rust 项目。
Rust 的 bin、lib 和 mod
在初始化项目之前,我们先来学习 3 个基础概念,cargo 中的 bin、lib、mod。
在 Rust 中,项目代码是通过 bin、lib、mod 这三种形式来组织的,先介绍下它们的功能。
1. bin
用来存放主入口 main 函数的目录。如下所示,它是通过 cargo.toml 中的 [[bin]] 语法指定的。name 表示编译生成的二进制文件的名称,path 表示主入口 main 函数所在的文件。当然,你可以在 cargo 文件中指定多个 [[bin]] ,生成多个目标二进制文件。
[[bin]]
name = "placement-center"
path = "src/placement-center/server.rs"
[[bin]]
name = "placement-center1"
path = "src/placement-center/server1.rs"
2. lib
这是 Library 的简写,表示功能库的集合。比如我们有一批通用的功能,就可以通过 lib 来组织,封装成一个独立的 lib,给其他项目调用。在 https://crates.io/ 上的各种基础功能库都是lib 的形式。从功能来看,Rust 中 lib 的概念相当于 Java Maven 中的 module。
lib 的特征是在 src 的目录下必须有一个 lib.rs 文件。比如我们在 common 目录下定义一个 base 的 Library,则它的结构如下:
├── common
│ └── base
│ ├── Cargo.toml
│ ├── src
│ │ └── lib.rs
│ └── tests
│ └── test.rs
3. mod
这是 Module 的缩写,从功能上来看,它相当于 Java 中的 package,它用来在 lib 中组织独立的代码功能。所以可以简单理解,mod 是包含在 lib 中的。比如我们在 common 中定义一个config 的 mod,此时目录结构如下:
├── common
│ └── base
│ ├── Cargo.toml
│ ├── src
│ │ ├── config
│ │ │ └── mod.rs
│ │ └── lib.rs
│ └── tests
│ └── test.rs
一般情况下,从功能上来看: 一个 lib 会包含多个 mod,一个 bin 需要调用多个 lib。
接下来我们来看一下如何组织我们的代码结构。
如何组织代码结构
如果你对我之前推荐的资料看得比较仔细,可能会关注到有这一章节 《标准的 Package 目录结构》。这里推荐了一个项目目录结构:
├── Cargo.lock
├── Cargo.toml
├── src/
│ ├── lib.rs
│ ├── main.rs
│ └── bin/
│ ├── named-executable.rs
│ ├── another-executable.rs
│ └── multi-file-executable/
│ ├── main.rs
│ └── some_module.rs
├── benches/
│ ├── large-input.rs
│ └── multi-file-bench/
│ ├── main.rs
│ └── bench_module.rs
├── examples/
│ ├── simple.rs
│ └── multi-file-example/
│ ├── main.rs
│ └── ex_module.rs
└── tests/
├── some-integration-tests.rs
└── multi-file-test/
├── main.rs
└── test_module.rs
从编码的角度来看,推荐的这个项目结构适合单体项目,比如微服务架构中某个服务的项目结构,它不适合复杂的项目。这是因为, 在这个项目结构中,只有一个 lib 和 bin,当项目中需要多个 lib 和多个 bin 的时候,这个目录结构就不够用了。而大部分项目,都是需要多个 lib 和多个 bin 的。
在 cargo 的定义中, 在业务逻辑比较复杂的项目中,一般需要通过 workspace 来组织多个 lib 和 bin。
那项目结构应该是什么样子呢?我们来看一下项目初始化后的目录结构,如下所示:
├── Cargo.toml # Cargo 的定义文件
├── LICENSE # 项目 的LICENSE 文件,比如Apache2.0
├── README.md # 项目说明 README文件
├── benches # 压测代码所在目录
├── bin # 项目启动命令存放的目录
├── build.rs # cargo中的构建脚本 build.rs。可参考这个文档:https://course.rs/cargo/reference/build-script/intro.html
├── config # 存放配置文件的目录
├── docs # 存放技术文档的目录
├── example # 存放项目调用 Demo 的项目
├── makefile # 用于编译打包项目的makefile文件
├── src # 源代码目录
│ ├── cmd
│ │ ├── Cargo.toml
│ │ ├── src
│ │ │ └── placement-center
│ │ │ └── server.rs
│ │ └── tests
│ │ └── test.rs
│ ├── placement-center
│ │ ├── Cargo.toml
│ │ ├── src
│ │ │ └── lib.rs
│ │ └── tests
│ │ └── test.rs
│ └── protocol
│ ├── Cargo.toml
│ ├── src
│ │ └── lib.rs
│ └── tests
│ └── test.rs
├── tests # 存放测试用例代码的文件
└── version.ini # 记录版本信息的文件
各个文件和目录的说明已经有标注,就不再赘述了。我们重点来看 src 目录的组织结构。这个目录结构得配合根目录的 cargo.toml 和子目录的 cargo 文件来解释,下面分别是根目录和子目录的 cargo 文件。
- 根目录 cargo.toml
[workspace]
members = [
"src/common/base",
"src/placement-center",
"src/cmd",
"src/protocol",
]
resolver = "2"
[workspace.package]
version = "0.0.1"
edition = "2021"
license = "Apache-2.0"
[workspace.dependencies]
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
## workspaces members
placement-center = { path = "src/placement-center" }
cmd = { path = "src/cmd" }
protocol = { path = "src/protocol" }
common-base = { path = "src/common/base" }
- 子目录 cargo.toml
[package]
name = "cmd"
version.workspace = true
edition.workspace = true
license.workspace = true
[dependencies]
[[bin]]
name = "placement-center"
path = "src/placement-center/server.rs"
这个项目结构的核心是:在项目的根目录通过 workspace 来组织管理 cmd、protocol、placement-center、common-base 等 4 个子项目。从定义上看,protocol、placement-center、common-base 是 lib 类型,分别完成相关业务逻辑,cmd 是 bin 类型。也就是说主入口 main 函数是写在 cmd/src/placement-center/server.rs 中的。
当然,在 cmd 中可以支持多个主入口 main 函数,来支持启动多个不同类型的服务。比如在最开始的架构图中有一个 Broker Server,我们就可以在 cmd 中的 toml 加一个 bin,如下所示:
[package]
name = "cmd"
version.workspace = true
edition.workspace = true
license.workspace = true
[dependencies]
[[bin]]
name = "placement-center"
path = "src/placement-center/server.rs"
[[bin]]
name = "mqtt-broker"
path = "src/mqtt-broker/server.rs"
从实践的角度看, 对于大多数项目 ,这个 项目结构基本是通用的,可以直接复制。接下来,我们来看一下如何打包项目。
通过 Cargo build 编译打包
在 Rust 中,打包项目是一件很简单的事情,就是在项目根目录直接执行 cargo build 即可。基于上面的 cargo 文件,执行完会在 target/debug目录下生成一个 placement-center 文件,效果如下:

此时,你可以执行 ./placement-center 命令,它会调用 cmd/src/placement-center/server.rs 中的主入口 main 函数,从而启动服务。如下图所示,会输出:
Get Started
因为我们在 cmd/src/placement-center/server.rs 中的内容是:
fn main() { println!("Get Started"); }
这里有一点需要注意的是: 你必须先了解 Cargo 中 Profile 的含义。
Profile 是 Cargo 的一个功能,详细内容你可以参考这个文档 《发布配置 Profile》。Profile 默认包含 dev、 release、 test 和 bench 4 种配置项。正常情况下,我们无需去指定,Cargo 会根据我们使用的命令来自动进行选择。例如:
-
cargo build 自动选择 dev profile
-
cargo test 则是 test profile
-
cargo build --release 自动选择 release profile
-
cargo bench 则是 bench profile
从运行的角度,编译器会根据这 4 种不同的配置提供不同的优化机制,比如优化编译速度、优化运行速度等等。例如在开发时,我们需要更快的构建速度来验证代码。此时,我们可以牺牲运行性能来换取编译性能,所以应该选择 dev 模式。而在线上环境,我们希望代码运行得更快,可以接受编译速度降低,则需要选择 release 模式。
因为默认情况下是 dev 模式,所以我们在开发测试时,编译时可以直接使用:
cargo build
而发布线上包,则需要使用:
cargo build -- release
编译生成可执行的二进制文件后,不清楚你会不会有疑问。我们平时下载的开源软件包,一般是 .tar.gz 的形式,而且下载解压完成后的目录结构一般是下面这种形式:
.
├── bin
├── config
└── libs
在这种结构中,bin 目录一般放启动脚本,config 目录一般放配置文件,libs 一般放一些依赖的可执行文件。启动时通过 bin 中的启动脚本来启动服务。
那能通过 Cargo 打出这种形式的 tar.gz 的包吗? 答案是不行的。那应该怎样打出这种包呢?
从实践来看,如果要实现类似的效果,一般需要依赖 make 和 makefile 来完成打包。
通过 make 和 makefile 来编译打包
可以说, 是否掌握 make 和 makefile,某种程度上意味着你是否掌握了构建大型项目的能力。所以建议你要去了解一下 make 命令和 makefile 的语法。这块语法,网上教程很多,你直接搜一下即可,我就不推荐了。
从功能上看,make 是一个编译命令,makefile 是 make 命令的语法文件。当执行 make 命令的时候,会默认在当前目录下寻找名称为 makefile 的文件,解析文件内容,并执行完成编译。
接下来,来看我们项目的 makefile 文件,通过这个文件看一下应该如何写 makefile。
TARGET = robustmq-geek
BUILD_FOLD = ./build
VERSION:=$(shell cat version.ini)
PACKAGE_FOLD_NAME = ${TARGET}-$(VERSION)
release:
# 创建对应目录
mkdir -p ${BUILD_FOLD}
mkdir -p $(BUILD_FOLD)/${PACKAGE_FOLD_NAME}
mkdir -p $(BUILD_FOLD)/${PACKAGE_FOLD_NAME}/bin
mkdir -p $(BUILD_FOLD)/${PACKAGE_FOLD_NAME}/libs
mkdir -p $(BUILD_FOLD)/${PACKAGE_FOLD_NAME}/config
# 编译 release 包
cargo build --release
# 拷贝 bin目录下的脚本、config中的配置文件、编译成功的可执行文件
cp -rf target/release/placement-center $(BUILD_FOLD)/${PACKAGE_FOLD_NAME}/libs
cp -rf bin/* $(BUILD_FOLD)/${PACKAGE_FOLD_NAME}/bin
cp -rf config/* $(BUILD_FOLD)/${PACKAGE_FOLD_NAME}/config
chmod -R 777 $(BUILD_FOLD)/${PACKAGE_FOLD_NAME}/bin/*
# 将目录打包成.tar.gz 文件
cd $(BUILD_FOLD) && tar zcvf ${PACKAGE_FOLD_NAME}.tar.gz ${PACKAGE_FOLD_NAME} && rm -rf ${PACKAGE_FOLD_NAME}
echo "build release package success. ${PACKAGE_FOLD_NAME}.tar.gz "
test:
sh ./scripts/integration-testing.sh
clean:
cargo clean
rm -rf build
在上面的 makefile 中,我们定义了 release、test、clean 等 3 个 target,即我们的 make 支持下面三个命令:
make release # 编译项目并打包成名称为robustmq-geek-{***}-beta.tar.gz的安装包
make test # 通过脚本./scripts/integration-testing.sh 运行测试用例,
make clean # 清理编译文件
接下来我们用 release target 来讲一下 makefile 的语法。
-
首先,定义了 TARGET、BUILD_FOLD、VERSION、PACKAGE_FOLD_NAME 4 个变量,分别表示项目的名称、构建完成后的包的存放目录、包的版本、项目名称+版本号组成的安装包的名称。
-
release target 里面是一段 shell 代码,拆解开来主要有下面四部分逻辑:
-
创建对应目录
-
编译 release 包
-
拷贝 bin 目录下的脚本、config 中的配置文件、编译成功的可执行文件
-
将目录打包成 .tar.gz 文件
-
当我们写完 makefile 后,接下来就可以执行 make release 命令打包即可,打包过程如下:
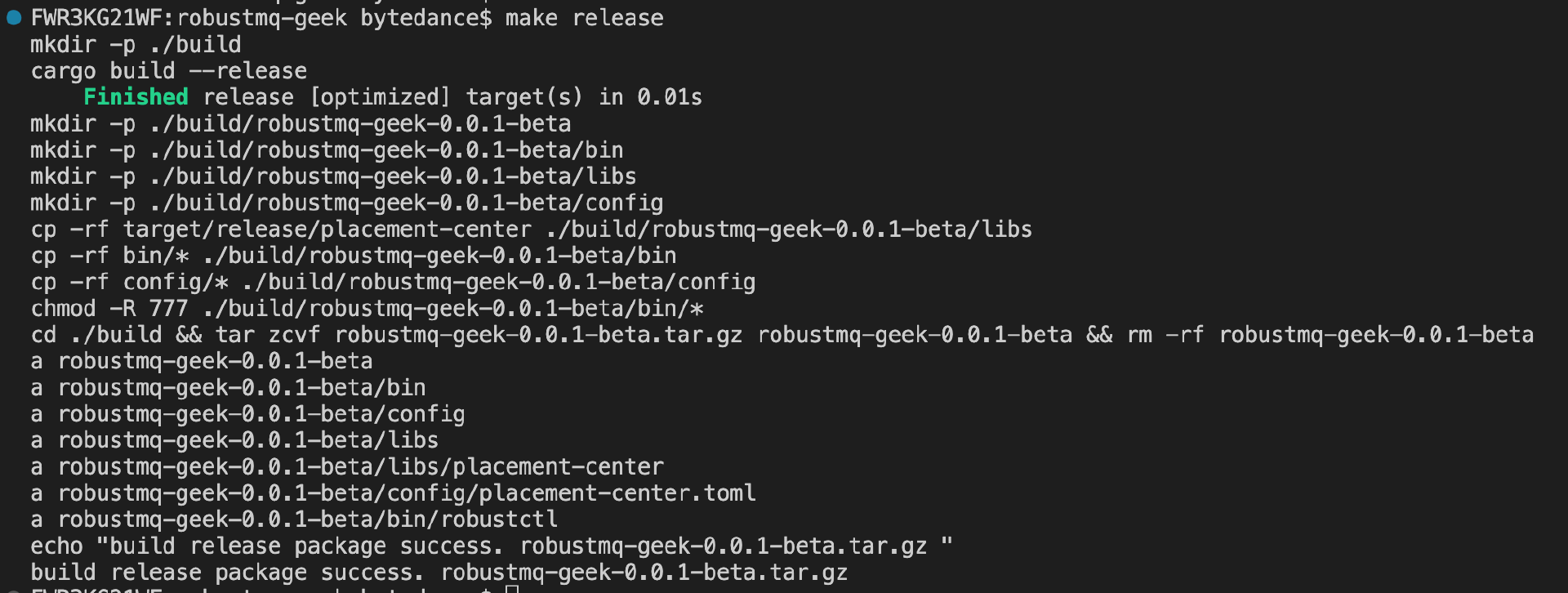
打包完成后,会在 build 目录下生成一个 robustmq-geek-0.0.1-beta.tar.gz 安装包,解压后效果如下:
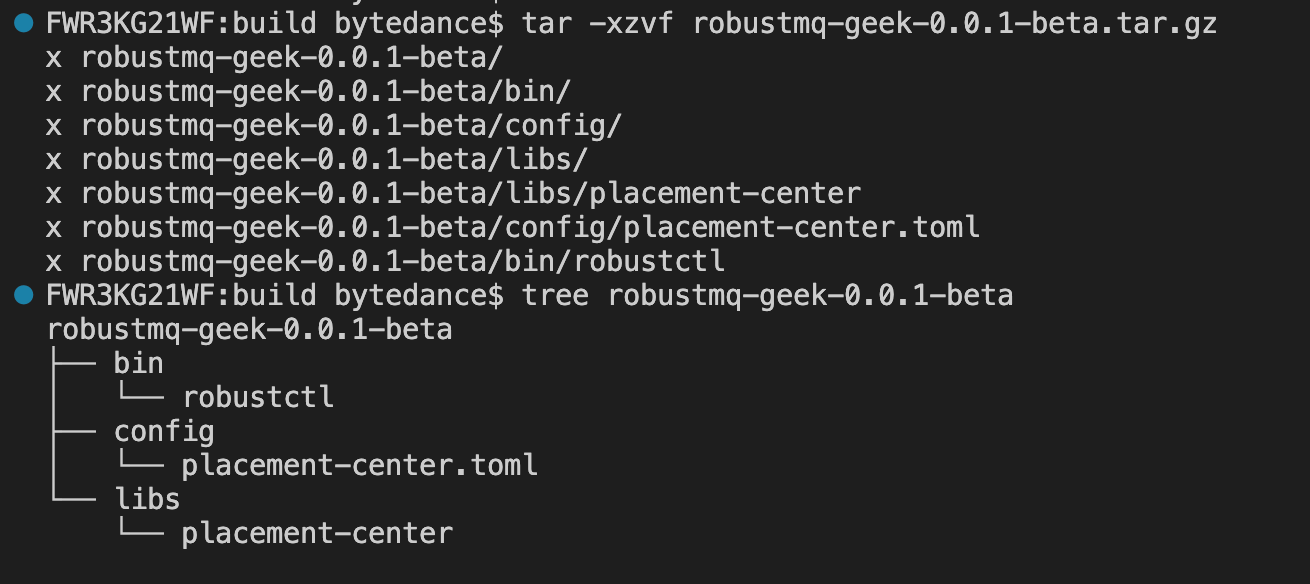
到这里,我们就完成了项目的初始化、编译、打包的整个流程了。
总结
tips:从本节课开始,每节课的代码都能在项目 https://github.com/robustmq/robustmq-geek 中找到源码,有兴趣的同学可以下载源码来看。
这节课的核心,我们完成了 如何组织项目结构 和 如何编译打包项目 两个工作。如果你要初始化一个项目,你直接按照这节课的思路去组织项目就可以了。
在组织复杂的 Rust 项目时,workspace 是需要重点关注的一个功能。另外在项目组织这块,你需要多去了解 Cargo 的各种语法。在 Cargo 中提供了很多好用的命令,比如 cargo bench 可以帮你压测代码的性能,cargo test 可以运行测试用例等等。
值得一提的是,Rust 在语言基础设施这块做得非常好,所以,当你熟悉了它的各种语法后,实际的工作量是很低的。
思考题
从这节课开始,我们的思考题换个方式。
我会在 https://github.com/robustmq/robustmq 项目中发布一些 good first issue 的任务,让你来完成,目的是让你有真正动手的机会,你可以选择自己感兴趣的任务来执行。当然如果你基础更好,也可以完成一些复杂的任务。当你完成自己认领的任务后,在评论区回复即可,我会找时间 check 一下大家的完成情况。
这里是本节课推荐的相关 issue 的任务列表,请点击查看 《Good First Issue》。 欢迎给我的项目 https://github.com/robustmq/robustmq 点个 Star 啊!
项目初始化四大件:命令行参数、配置、日志、测试用例
本课程为精品小课,不标配音频
你好,我是文强。
上节课我们完成了项目的初始化,这节课我们来完成 如何处理命令行参数、 如何管理配置、 如何记录日志、 如何运行测试用例 四个任务。有了这四个基础部分,项目的基础模块就基本成型了。
处理命令行参数
Rust 处理命令行参数推荐使用 clap 这个库。
这里,我想同时跟你聊一下如何更好地使用前面提过的 https://crates.io/ 这个网站,它是 Rust 的公共库的代码仓库。
在我看来, 能不能把 crates.io 用好,决定了你能不能学好Rust 这个语言。 接下来我们就以使用 clap 库来处理命令行参数这个 case 来讲解一下如何用好 crates.io。
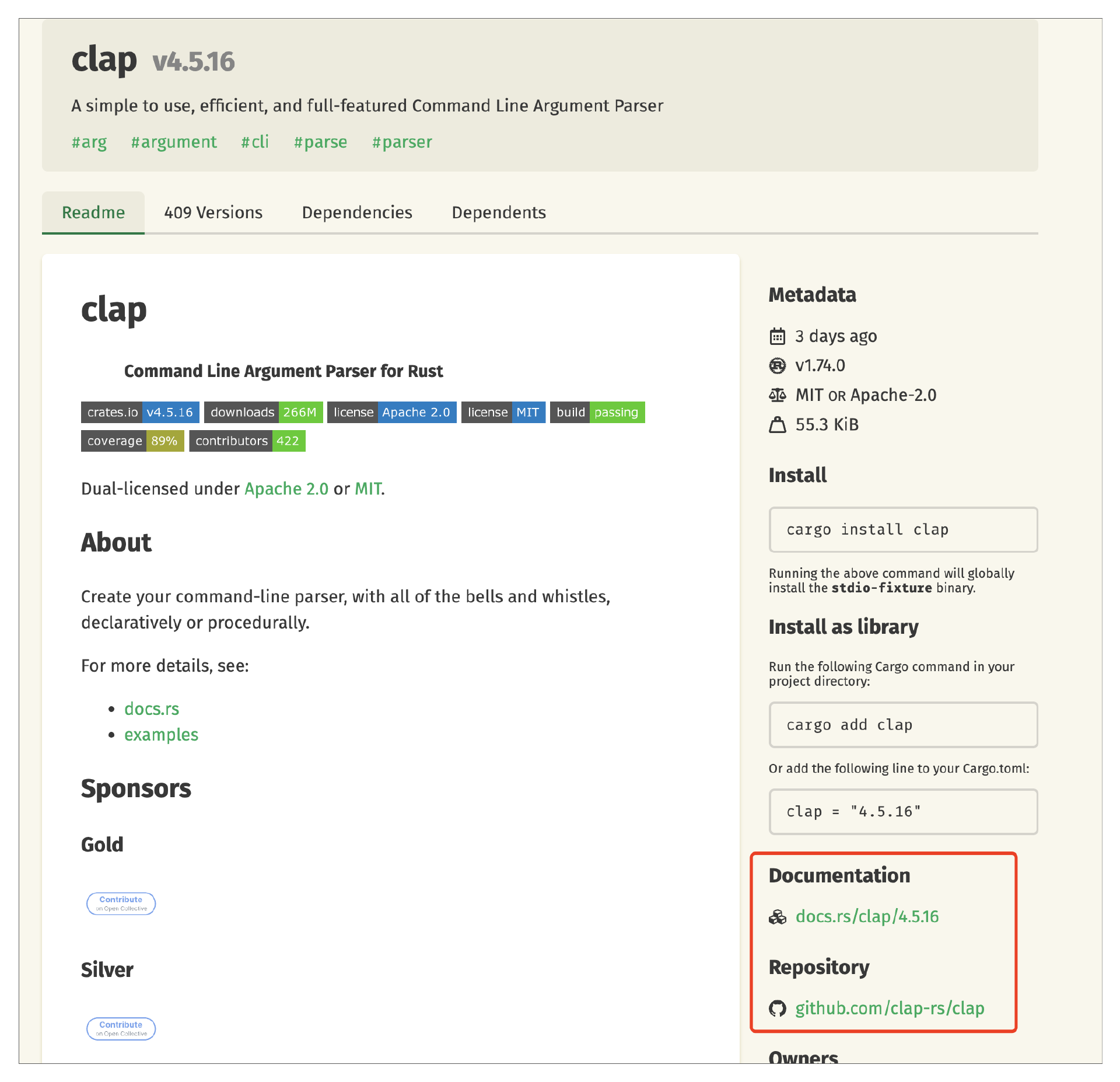
比如我们需要使用库 clap,下图是 clap 库的首页。一般在首页都会有关于这个库详细的使用说明,比如使用方法、使用 demo。所以你得重视这个页面,在这个页面可以得到很多信息。另外需要关注右下角两个链接,一个是库的 Rust 文档地址,格式是统一的;另一个一般是源码所在地址,一般是 GitHub 仓库的地址。
这里有个技巧是: 如果在文档中找不到你想要的信息,可以尝试去 GitHub 仓库找,GitHub 仓库一般有更详细的 example 信息。
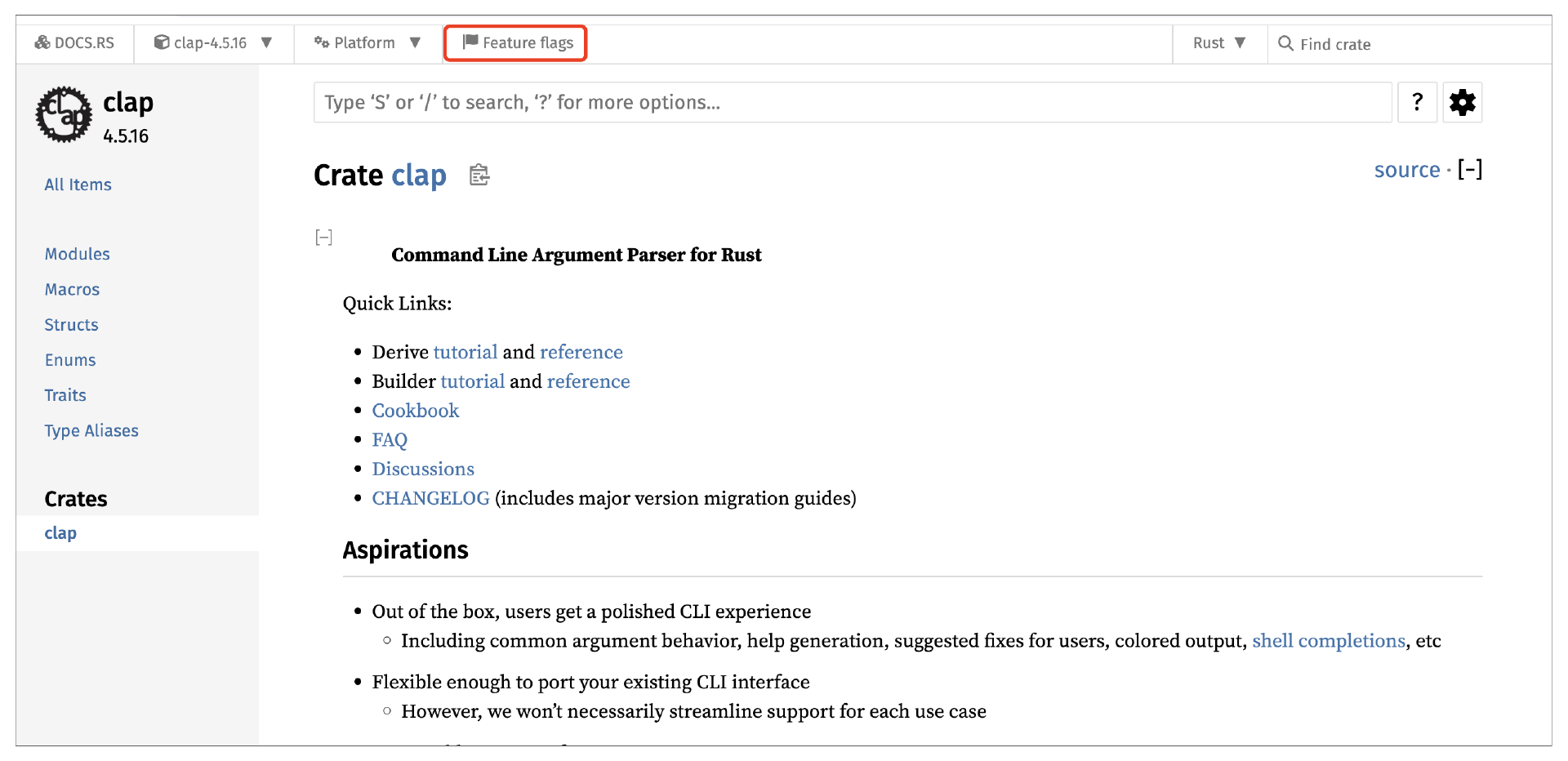
如下图所示,库的文档首页是统一格式的。它会展示库中 Modules、Macros、Structs、Enums、Traits、Type Aliases 六部分信息,分别会列举库中的 mod、宏、结构体、枚举、Trait、Type Alias 等相关信息。你可以根据需要查看对应部分的内容。
比如我想知道 clap 要怎么用,那就直接看首页的 demo 即可。

接下来来看一下我们的项目是怎么处理命令行参数的。在当前阶段,我们需求是: 能从命令行接收配置文件路径,则代码应该在 src/cmd/src/metadata-service/server.rs 中,代码如下:
use clap::command; use clap::Parser; // 定义默认的配置路径,即当命令行没传配置路径时,默认的配置文件路径 pub const DEFAULT_PLACEMENT_CENTER_CONFIG: &str = "config/placement-center.toml"; // 定义接收哪些参数 #[derive(Parser, Debug)] #[command(author="robustmq-geek", version="0.0.1", about=" RobustMQ: Next generation cloud-native converged high-performance message queue.", long_about = None)] #[command(next_line_help = true)] struct ArgsParams { #[arg(short, long, default_value_t=String::from(DEFAULT_PLACEMENT_CENTER_CONFIG))] conf: String, } fn main() { // 解析命令行参数 let args = ArgsParams::parse(); println!("conf path: {:?}", args.conf); }
这里,处理命令行参数主要分为两步:
-
定义一个结构体 ArgsParams,结构体包含自定义的 conf 属性,即需要接收的配置文件路径。
-
通过 ArgsParams::parse() 解析参数。
上面的代码可以通过下面的命令执行得到结果:
cargo run --package cmd --bin placement-center -- --conf=config/placement-center.toml
效果如下所示:

如果要了解更多关于 clap 这个库的语法,可以看它在 crates 的官方文档。
管理静态配置
在管理项目配置文件时,第一件事就是要思考: 要用哪种格式的配置文件。有 Java 背景的同学会习惯用 yaml 或 properties 的配置文件,另外可能可能会用到 json、toml 等配置文件。
那应该用哪种呢?我在一开始写 Rust 的时候也遇到了这个问题。后来我研究后的结果是: 使用 toml 文件。
原因很简单,一是因为 toml 格式简单好用,能满足各种配置场景;二是因为大部分开源的 Rust 项目都是使用 toml 格式的配置文件。
那么如何读取和处理 toml 格式的配置文件呢?在 Rust 中,建议通过 toml 这个库,这个库的功能比较简单,你可以先不看下面的代码,去看一下 crates.io 上的内容,看是否知道怎么写。
接下来我们来开发我们的配置文件模块,总共分为三步。
- 定义我们元数据服务的配置文件 placement-center.toml,先定义节点 ID 和节点监听的 GRPC 端口两个属性
#![allow(unused)] fn main() { node_id = 1 # 节点 ID grpc_port = 1228 # 节点监听的 GRPC 端口 }
- 定义解析配置文件的结构体
#![allow(unused)] fn main() { use serde::Deserialize; #[derive(Debug, Deserialize, Clone, Default)] pub struct PlacementCenterConfig { #[serde(default = "default_node_id")] pub node_id: u32, #[serde(default = "default_grpc_port")] pub grpc_port: usize, } pub fn default_node_id() -> u32 { 1 } pub fn default_grpc_port() -> usize { 9982 } }
- 解析配置文件
#![allow(unused)] fn main() { static PLACEMENT_CENTER_CONF: OnceLock<PlacementCenterConfig> = OnceLock::new(); pub fn init_placement_center_conf_by_path(config_path: &String) -> &'static PlacementCenterConfig { // n.b. static items do not call [`Drop`] on program termination, so if // [`DeepThought`] impls Drop, that will not be used for this instance. PLACEMENT_CENTER_CONF.get_or_init(|| { let content = read_file(config_path); let pc_config: PlacementCenterConfig = toml::from_str(&content).unwrap(); return pc_config; }) } pub fn placement_center_conf() -> &'static PlacementCenterConfig { match PLACEMENT_CENTER_CONF.get() { Some(config) => { return config; } None => { panic!( "Placement center configuration is not initialized, check the configuration file." ); } } } }
上面的代码不复杂,主要有两步:
-
#[serde(default = "default_node_id")]的使用,这个语法是定义配置 node_id的默认值,即如果没有配置 node_id 的时候,node_id 的默认值是多少。其中default_node_id是一个函数名,对应上面的 fn default_node_id(), 所以默认值是这个函数的返回值。 -
第二个是下面这两行代码,表示读取指定配置文件的内容,并让
toml::from_str解析配置文件的内容。
#![allow(unused)] fn main() { let content = read_file(config_path); let pc_config: PlacementCenterConfig = toml::from_str(&content).unwrap(); }
理论上 1 和 2 就完成了配置的管理。这里如果每次获取配置都执行 2 来获取配置内容,那每次都要解析文件,就太重了,就得想办法把配置文件缓存到内存里面,比如某个静态变量。
此时,我们是通过OnceLock这个语法来实现的。OnceLock 都是 Rust 标准库中用于实现懒加载的数据结构, 它能够确保一个变量只被初始化一次 , 也就是我们在其他语言中用到的单例模式。
关键代码是:
-
PLACEMENT_CENTER_CONF.get_or_init:获取或者初始化值。这个函数特殊的地方在于,不管调用多少次,只会初始化一次。 -
PLACEMENT_CENTER_CONF.get:获取已经初始化后的值。
所以我们在 main 函数初始化配置后,就可以通过placement_center_conf随时获取到配置,代码如下:
fn main() { let args = ArgsParams::parse(); init_placement_center_conf_by_path(&args.conf); }
执行后效果如下:

接下来我们来看看如何初始化我们的日志模块。到这里你可以在脑子里面想一下这个日志模块应该需要满足什么功能需求?
如何记录日志
通用的日志模块核心是四个需求:
-
支持多个不同的日志级别。
-
支持多种日志滚动方式,比如按时间滚动、按大小滚动。
-
支持自定义日志格式。
-
支持根据不同的类型将日志打印到不同的文件。
在 Rust 中,日志文件建议直接用 log4rs 库即可,它满足我们上面的这几点需求。初始化日志模块主要分为三步:
-
编写 log4rs.yaml 文件
-
初始化日志模块
-
记录日志
接下来我们来看一下我们的 log4rs.yaml 文件, 下面重点关注 loggers 模块,这块官方文档写得不太清晰。
appenders:
# 定义一个名为stdout的appender,功能是将日志输出到控制台
stdout:
kind: console
# 定义一个名为server的appender,功能是将日志输出到名为server.log的滚动文件
# 每个文件大小 1gb,文件序号从 0 开始到 50
# 日志的格式为"{d(%Y-%m-%d %H:%M:%S)} {h({l})} {m}{n}"
# 日志格式参考这个文档:https://docs.rs/log4rs/1.3.0/log4rs/encode/pattern/index.html
server:
kind: rolling_file
path: "{$path}/server.log"
encoder:
pattern: "{d(%Y-%m-%d %H:%M:%S)} {h({l})} {m}{n}"
policy:
trigger:
kind: size
limit: 1 gb
roller:
kind: fixed_window
pattern: "{$path}/server-{}.log"
base: 0
count: 50
# 参考 server
requests:
kind: rolling_file
path: "{$path}/requests-log.log"
encoder:
pattern: "{d(%Y-%m-%d %H:%M:%S)} {h({l})} {m}{n}"
policy:
trigger:
kind: size
limit: 1 gb
roller:
kind: fixed_window
pattern: "{$path}/requests-log-{}.log"
base: 0
count: 50
# 默认清况下,所有的日志都会输出到 stdout和 server 两个 appender
root:
level: info
appenders:
- stdout
- server
# 这个需要重点注意,可以将不同 lib 或 mod 中的日志输出到不同的文件
loggers:
# 将 placement_center::server模块的日志会写入到 stdout 和 server 两个 appender
placement_center::server:
level: info
appenders:
- stdout
- server
additive: false
# 将 placement_center::requests模块的日志会写入到 stdout 和 requests 两个 appender
placement_center::requests:
level: info
appenders:
- stdout
- requests
additive: false
log4rs.yaml 的语法都写在注释里,就不展开了。编写好文件后,就需要初始化配置,来看下面代码:
#![allow(unused)] fn main() { pub fn init_placement_center_log() { // 1. 获取配置信息 let conf = placement_center_conf(); // 2. 检查日志配置 .yaml 文件是否存在 if !file_exists(&conf.log.log_config) { panic!( "Logging configuration file {} does not exist", conf.log.log_config ); } // 3.尝试初始化日志存放目录 match create_fold(&conf.log.log_path) { Ok(()) => {} Err(e) => { panic!("Failed to initialize log directory {}", conf.log.log_path); } } // 4. 读取日志配置.yaml 文件的内容 let content = match read_file(&conf.log.log_config) { Ok(data) => data, Err(e) => { panic!("{}", e.to_string()); } }; // 5. 替换日志文件的存放路径 let config_content = content.replace("{$path}", &conf.log.log_path); println!("{}","log config:"); println!("{}", config_content); // 6. 解析 yaml 格式的配置文件 let config = match serde_yaml::from_str(&config_content) { Ok(data) => data, Err(e) => { panic!( "Failed to parse the contents of the config file {} with error message :{}", conf.log.log_config, e.to_string() ); } }; // 7. 初始化日志配置 match log4rs::init_raw_config(config) { Ok(_) => {} Err(e) => { panic!("{}", e.to_string()); } } } }
上面代码整体分为七步,如果对 log4rs 学习比较充分的同学,可能会有一个想法,初始化日志配置需要这么复杂吗?用下面的代码不就好了吗?
#![allow(unused)] fn main() { log4rs::init_file("log4rs.yml", Default::default()).unwrap(); }
是的,理论上这样是可以的。
但是因为用户修改日志存放目录,是一个常见的需求,并且除了修改日志存放目录外,大部分情况下,用户不需要去修改日志的配置文件内容。
所以希望进一步优化使用体验,即: 希望用户大部分清况下不用去理解 log4rs 的语法,且修改日志存放目录时,不需要修改 log4rs.yaml 中的日志路径。
所以为了达到上面的效果,我们在配置文件中加了下面这两行配置:
#![allow(unused)] fn main() { [log] log_config = "./config/log4rs.yaml" log_path = "./logs" }
然后再手动读取 log4rs.yaml 的内容,并且在第 5 步 替换了 log4rs.yaml 中的日志目录路径。最后通过log4rs::init_raw_config(config) 完成了日志模块的初始化。
最后在 main 函数中调用init_placement_center_log初始化日志。
fn main() { let args = ArgsParams::parse(); // 初始化配置文件 init_placement_center_conf_by_path(&args.conf); // 初始化日志 init_placement_center_log(); let conf = placement_center_conf(); // 记录日志 info!("{:?}", conf); start_server(); }
当完成初始化后,就可以通过 info!、debug!、warn!、error! 等方法记录日志了,并将 placement_center::requests 模块的日志写入到 request.log 和 stdout,再将placement_center::server 模块的日志写入到 server.log 和 stdout,其他日志默认全部写入 server.log 和 stdout。
到这里我们就完成了日志模块的初始化。接下来我们来看一下如何写测试用例。
运行测试用例
接下来我们以读取静态配置的流程为 case,写一个测试用例验证我们读取静态配置的代码是没问题的。
写测试用例的时候, 一般会把测试用例和代码写在一起。比如我们要测试common/base/src/config/placement_center.rs 中的代码,则可以把下面的测试用例放在这个文件中。
测试文件用例如下:
#![allow(unused)] fn main() { mod tests { use crate::config::placement_center::{ init_placement_center_conf_by_path, placement_center_conf, }; #[test] fn config_init_test() { let path = format!( "{}/../../../config/placement-center.toml", env!("CARGO_MANIFEST_DIR") ); init_placement_center_conf_by_path(&path); let config = placement_center_conf(); assert_eq!(config.node_id, 1); assert_eq!(config.grpc_port, 1228); } } }
这里我写了一个 config_init_test 方法来验证 init 日志是否正常。主要依赖 assert_eq 来判断读取的数据是否符合预期。
基本所有测试用例都是这个逻辑: 初始化某个数据,然后判断数据是否符合预期。我们可以通过 cargo test --package common-base 来测试这个模块中的测试用例。
最后分享一个运行测试用例的技巧。
我们通常会运行 Server 来提供服务,一般都需要测试我们提供的服务是否正常,我们通常会写测试用例验证服务接口的进出参是否正常。此时,如果运行 Cargo 就会遇到一个问题,如果 Server 没启动,那么 Cargo Test 执行就会失败。
此时,可以通过一个 shell 脚本封装 Cargo Test 来测试,脚本内容伪代码如下:
start server
cargo test --package common-base
stop server
这里给一个我们封装好的 shell 示例,给你参考,比较简单,就不展开讲了。
#!/bin/sh
start_placement_center(){
nohup cargo run --package cmd --bin $placement_center_process_name -- --conf=tests/config/$placement_center_process_name.toml >/dev/null 2>&1 &
sleep 3
while ! ps aux | grep -v grep | grep "$placement_center_process_name" > /dev/null; do
echo "Process $placement_center_process_name has not started yet, wait 1s...."
sleep 1
done
echo "Process $placement_center_process_name starts successfully and starts running the test case"
}
stop_placement_center(){
pc_no=`ps aux | grep -v grep | grep "$placement_center_process_name" | awk '{print $2}'`
echo "placement center num: $pc_no"
kill $pc_no
sleep 3
while ps aux | grep -v grep | grep "$placement_center_process_name" > /dev/null; do
echo "”Process $placement_center_process_name stopped successfully"
sleep 1
done
}
# 1. 启动placement center
start_placement_center
# 2. Run Cargo Test
cargo test
# 3. stop server
if [ $? -ne 0 ]; then
echo "Test case failed to run"
stop_placement_center
exit 1
else
echo "Test case runs successfully"
stop_placement_center
fi
总结
tips:每节课的代码都能在项目 https://github.com/robustmq/robustmq-geek 中找到源码,有兴趣的同学可以下载源码来看。
这节课我们完成了命令行参数、静态配置、日志模块、测试用例的开发。
-
命令行参数推荐使用 clap 库。
-
配置文件建议用 toml 格式文件,通过 toml 库配合 OnceLock 来实现配置文件的单例加载。
-
日志模块通过 log4rs 来初始化即可。
-
测试用例建议和代码写在同一个文件,如果需要依赖外部系统完成测试用例,建议在 Cargo Test 上配合 shell 来完成对应的工作。
思考题
这里是本节课推荐的相关 issue 的任务列表,请点击查看 《Good First Issue》,任务列表会不间断地更新。欢迎给我的项目 https://github.com/robustmq/robustmq 点个 Star 啊!
逻辑功能开发:网络层Server端如何选型?
本课程为精品小课,不标配音频
你好,我是文强。
前面我们完成了项目初始化和基础模块的开发,这节课我们正式进入逻辑功能部分的开发。我们第一个要做的就是网络 Server 模块。
开发网络 Server 模块的核心是: 从业务需求视角出发,分析 Server 应该具备哪些能力,从而根据这些信息选型出技术层面网络层和应用层的协议。
前面我们讲到,第一阶段我们会完成消息队列中的 “元数据服务” , 那么接下来我们就来看一下这个元数据存储服务的网络 Server 怎么选型。
网络 Server 模块选型
先来看一下元数据服务(Placement Center)的架构图。
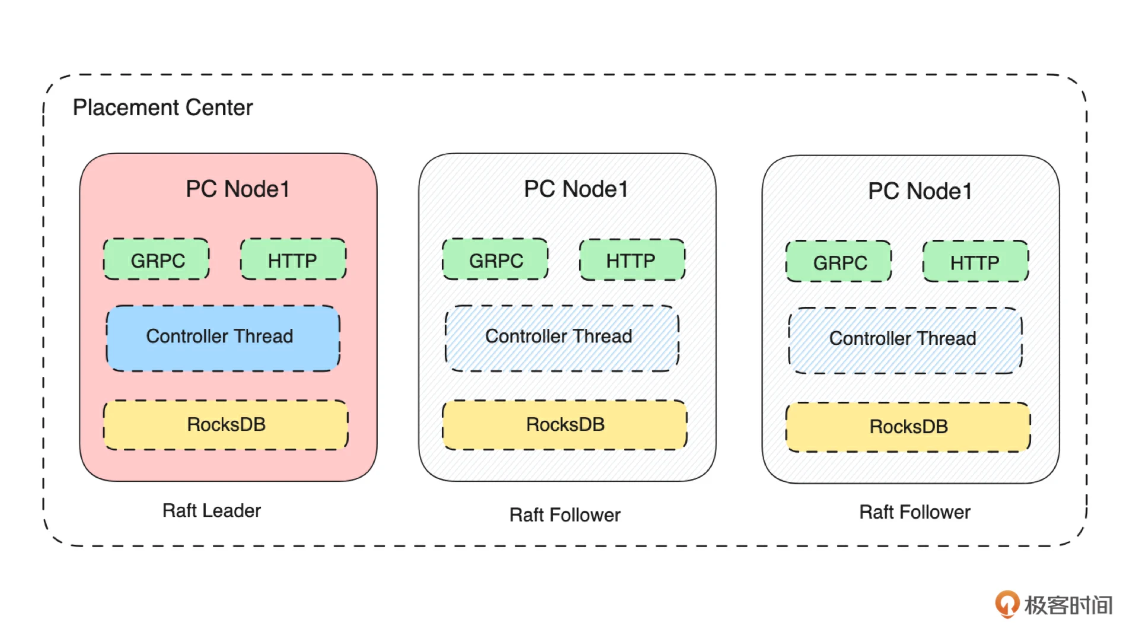
在前面的定义中,我们的元数据服务有两个功能:
-
分布式的 KV 存储能力:需要给 Broker 集群提供分布式的 KV 存储能力,从性能来看,需要支持较高并发的读写。
-
集群管控和调度能力: 根据运行信息对 Broker 集群进行管控、调度,比如元数据更新、Leader 切换等等。
所以从网络模块的角度来看,就需要能支持: 较高的吞吐和并发能力。那协议怎么选择呢?
从技术上来看,很多开源组件会选择 TCP + 自定义协议 来完成网络 Server 的开发。我们最终选择的是 基于 gRPC 协议来实现我们的 Server。考虑如下:
-
gRPC 是标准的网络通讯框架,具备现成的 Server 端库和多语言 SDK。基于 gRPC 框架实现网络 Server 会极大地降低开发成本。
-
gRPC 协议底层是基于 HTTP2 和 Protobuf 来实现数据通信的,具备较高的吞吐性能。
-
元数据服务是用来给 Broker 集群提供服务的,所以从业务特点上不会有非常高的数据量的吞吐。
-
元数据服务是集群化部署,允许多节点快速横向部署扩容,不需要单机具备极高的性能。
另外作为一个元数据存储服务,它一般 需要提供 HTTP 协议的接口来给管控页面或者用户做一些管理操作。比如增删改查集群、用户、权限信息,查看集群运行的监控数据等等。所以我们还需要提供 HTTP 协议的 Server 来支持这类场景。
总结来看,我们的元数据服务需要提供 基于 gRPC 协议的数据面 Server 和 基于 HTTP 协议的管控面 Server。
接下来我们来看看如何基于 Axum 来实现 HTTP Server。
基于 Axum 支持 HTTP Server
在 Rust 中,Axum 是实践中选择最多的框架。教程很齐全,就不展开细讲各个技术细节了,需要的话你可以看 《官方文档》 和 《Demo 示例》。 在 Demo 里面你几乎可以找到所有需要的用法。
从元数据服务的管控功能来看,我们需要提供 HTTP 协议的对资源的增删改查接口。所以我们的 HTTP Server 需要具备以下四个功能:
-
支持 Restful 规范的 HTTP 接口。
-
支持多版本接口的管理。
-
返回 JSON 格式的请求和返回。
-
支持在接口中处理各种业务逻辑,比如数据读写、缓存读取等。
这四个功能基本包含了我们对一个 HTTP Server 的基本诉求,接下来我们从主要代码来讲解一下实现的逻辑。
首先通过函数 start_http_server 来启动 HTTP Server。
#![allow(unused)] fn main() { pub async fn start_http_server(state: HttpServerState, stop_sx: broadcast::Sender<bool>) { 读取配置 let config = placement_center_conf(); 组装监听地址和端口 let ip: SocketAddr = match format!("0.0.0.0:{}", config.http_port).parse() { Ok(data) => data, Err(e) => { panic!("{}", e); } }; // 构建路由信息 let app = routes(state); let mut stop_rx = stop_sx.subscribe(); // 绑定端口,如果端口绑定失败,直接退出程序 let listener = match tokio::net::TcpListener::bind(ip).await { Ok(data) => data, Err(e) => { panic!("{}", e); } }; // 通过 select 来同时监听进程停止信号和 Server 运行 select! { val = stop_rx.recv() =>{ match val{ Ok(flag) => { if flag { info!("HTTP Server stopped successfully"); break; } } Err(_) => {} } }, // 监听服务 val = axum::serve(listener, app.clone())=>{ match val{ Ok(()) => { // info!("HTTP Server started successfully, listening on port {}",config.http_port) }, Err(e) => { // HTTP 服务监听失败,直接退出程序 panic!("{}",e); } } } } } }
上面的代码主要逻辑都在注释中,不再展开。我们主要关注select和panic这两个语法。
-
在 Rust 中 select 的功能是等待多个并发分支,如果有一个分支返回,则取消剩余分支。在上面的代码中,如果接收到停止进程的信号或者 HTTP Server 停止,则 select 就会返回。因此, 用 select 语法从功能上是为了能够正确处理进程停止信号。select 相关详细资料可以参考 《Tokio Select》。
-
panic 是退出进程的信号,当出现不可逆异常时,可以通过这个语法退出进程。
接下来,来看看定义路由的代码,这块属于 Axum Router 的官方语法的使用,细节可以参考这个文档 《Axum Router》。
#![allow(unused)] fn main() { #[derive(Clone)] pub struct HttpServerState { mysql:DB } impl HttpServerState { pub fn new(mysql:DB) -> Self { return Self {mysql}; } } fn routes(state: HttpServerState) -> Router { // 定义不同的http path 路径被哪个服务处理 let common = Router::new() .route(&v1_path(&path_list(ROUTE_ROOT)), get(index)) .route(&v1_path(&path_create(ROUTE_ROOT)), post(index)) .route(&v1_path(&path_update(ROUTE_ROOT)), put(index)) .route(&v1_path(&path_delete(ROUTE_ROOT)), delete(index)); // 构建路由信息并返回,Axum的 merge 和 with_state 语法 let app = Router::new().merge(common); return app.with_state(state); } // 业务处理逻辑 index 函数 pub async fn index(State(state): State<HttpServerState>) -> String { state.mysql.query("select * ....."); return success_response("{}"); } // 通过 serde_json 返回json 格式的数据。 pub fn success_response<T: Serialize>(data: T) -> String { let resp = Response { code: 0, data: data, }; return serde_json::to_string(&resp).unwrap(); } }
在上面的代码中,需要关注的有 HttpServerState、Route merge、success_response 三个语法。
-
HttpServerState 是一个我们自定义的数据结构,它是和 app.with_state 结合起来用的,允许我们将自定义变量通过HttpServerState 传递给真正的业务逻辑。比如 HttpServerState 包含了一个变量 MySQL,它是 MySQL driver。所以我们在上面的 index 函数中,就可以通过 state.mysql 来获取到 MySQL driver,执行 SQL 进行数据查询。因此如果有其他的全局变量都可以通过这个 state 来传递给各个 HTTP Server 处理。
-
Route merge 是一个官方语法,主要功能是方便你管理多个 route,直接参考 《Axum Router》 即可。
-
在success_response方法中,使用 serde_json 将数据编码成 json 格式进行返回。
细心的同学会关注到类似 v1_path 和 path_get 两个函数。它是我们自定义的一个函数,用来实现 API 版本管理的。逻辑很简单,贴个代码你就懂了。
#![allow(unused)] fn main() { pub(crate) fn v1_path(path: &str) -> String { return format!("/v1{}", path); } pub(crate) fn path_get(path: &str) -> String { return format!("{}/get", path); } }
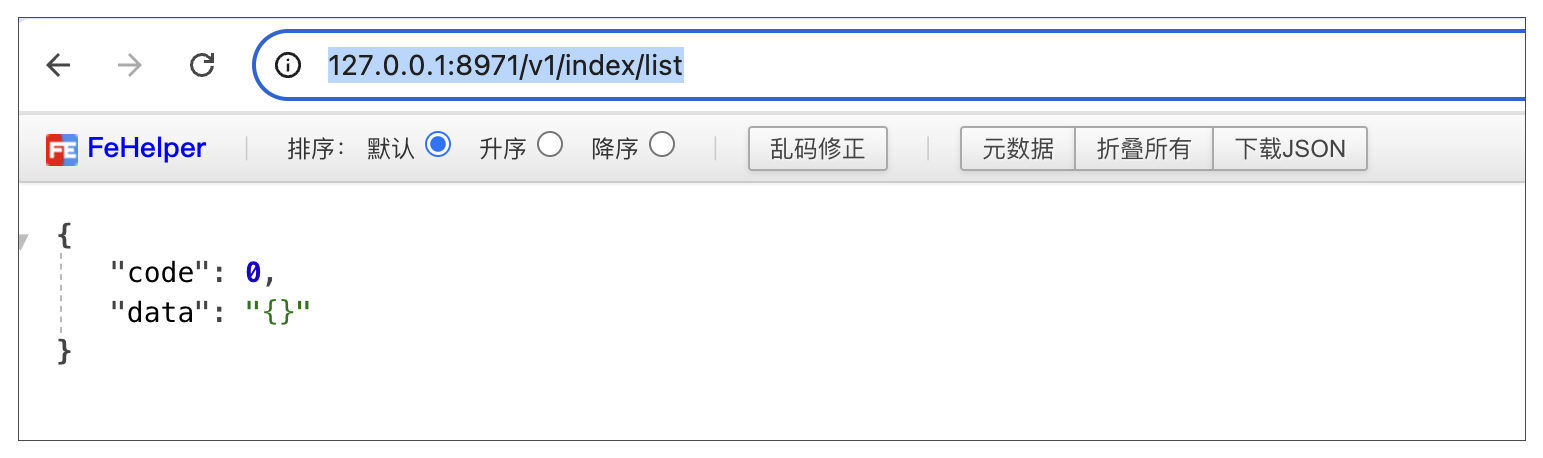
当完成上面的代码后,最后访问地址 http://127.0.0.1:8971/v1/index/list,效果如下:
到了这里,我们就完成了满足上述 4 个需求的 HTTP Server 了,更多细节就需要你自己去扩展了。
接下来我们来实现基于 gRPC 协议的数据面 Server。
基于 Tonic 实现 gRPC Server
从技术上来看,Rust 中 gRPC 的实现是比较成熟的,有现成的框架可以用。从实践来看,我建议使用 《Tonic 库》 来实现。我推荐两个 gRPC 代码示例库 《Example1》 和 《Example2》,这里面有各种场景的 gRPC 示例。
从编码角度来看,基于 Tonic 库实现 gRPC Server 主要包含五步:
-
编写 protobuf 文件,即通过 protobuf 语法定义 RPC 的方法和参数
-
编译 protobuf 文件
-
在服务端,实现 RPC Service
-
启动 gRPC Server
-
运行测试用例
首先来编写元数据服务的 gRPC Server 的 protobuf 文件。我们知道它的一个重要功能就是 KV 型数据的存储,所以 gRPC Server 就得支持 KV 中 set/delete/get/exists 四个功能。
所以 Server 的 Protobuf 文件 placement_center.proto,内容如下:
#![allow(unused)] fn main() { syntax = "proto3"; package kv; import "common.proto"; service KvService { rpc set(SetRequest) returns(common.CommonReply){} rpc delete(DeleteRequest) returns(common.CommonReply){} rpc get(GetRequest) returns(GetReply){} rpc exists(ExistsRequest) returns(ExistsReply){} } message SetRequest{ string key = 1; string value = 2; } message GetRequest{ string key = 1; } message GetReply{ string value = 1; } message DeleteRequest{ string key = 1; } message ExistsRequest{ string key = 1; } message ExistsReply{ bool flag = 1; } }
上面的语法很简单,定义了 set、delete、get、exists 四个 RPC 方法,以及对应的request/reply 参数。我们使用的是 protobuf 3 的语法,关于 protobuf 3 的语法,你可以去看 《protobuf 3 指南》。
接下来这一步是需要重点关注的: proto 文件只是定义 RPC 的调用信息,如果要在Rust 使用这个 proto 文件,则需要将其编译成 .rs 文件。
在 Rust 使用 protobuf,有两种方式。
- 第一种方法:使用 tonic 库中的宏 tonic::include_proto!,使用姿势如下:
#![allow(unused)] fn main() { pub mod placement_center_grpc { tonic::include_proto!("placement_center"); } }
Rust 中宏的作用直观理解就是: 翻译/填充代码。在上面的示例中,就是把placement_center.rs 文件编译成 Rust 的代码,然后把生成的代码填充到 placement_center_grpc 的模块中。 为了代码简洁,基于宏是主流推荐的用法。
- 第二种用法:手动使用 《tonic_build》 库将protobuf 代码编译成 Rust 代码。然后再正常 通过 use 使用编译完成的代码。为了让你能更加理解这个流程,我们的课程使用这种用法,下面是编译 protobuf 文件到 Rust 代码的代码示例。
#![allow(unused)] fn main() { fn build_pb() { tonic_build::configure() .build_server(true) // 指定生成的rust 存放的目录 .out_dir("src/") // you can change the generated code's location .compile( &[ // 指定需要编译的 proto 文件 "src/kv.proto", ], // 指定在哪个目录寻找 .proto 文件 &["src/"], // specify the root location to search proto dependencies ) .unwrap(); } }
当执行完这个代码,就会自动在 src 目录下生成 kv.rs 的文件。如下所示:

第二种方法相比第一种方法麻烦了许多,每次修改 proto 文件后都得手动编译一次。其实从底层来看,tonic::include_proto 宏本质上也是使用 tonic_build 编译的 proto 文件。只是通过 Rust 宏的特性,自动执行了这一步而已。这里需要注意的是,topic_build 底层是调用 《prost 库》 实现Protocol Buffers编译的。
接下来我们来实现 gRPC Server 端的 KV Server,也就是 RPC 中的方法。代码如下:
#![allow(unused)] fn main() { use protocol::kv::{ kv_service_server::KvService, CommonReply, DeleteRequest, ExistsReply, ExistsRequest, GetReply, GetRequest, SetRequest, }; use tonic::{Request, Response, Status}; // 定义GrpcBrokerServices结构体 pub struct GrpcBrokerServices { // 初始化一个基于 DashMap 库的 HashMap data: DashMap<String, String>, } impl GrpcBrokerServices { pub fn new() -> Self { return GrpcBrokerServices { data: DashMap::with_capacity(8), }; } } // 在GrpcBrokerServices中实现 set/get/delete/exists 四个方法 // 当前实现是将数据保存在内存中的 #[tonic::async_trait] impl KvService for GrpcBrokerServices { async fn set(&self, request: Request<SetRequest>) -> Result<Response<CommonReply>, Status> { let req = request.into_inner(); self.data.insert(req.key, req.value); return Ok(Response::new(CommonReply::default())); } async fn get(&self, request: Request<GetRequest>) -> Result<Response<GetReply>, Status> { let req = request.into_inner(); if let Some(data) = self.data.get(&req.key) { return Ok(Response::new(GetReply { value: data.value().clone(), })); } return Ok(Response::new(GetReply::default())); } async fn delete( &self, request: Request<DeleteRequest>, ) -> Result<Response<CommonReply>, Status> { let req = request.into_inner(); self.data.remove(&req.key); return Ok(Response::new(CommonReply::default())); } async fn exists( &self, request: Request<ExistsRequest>, ) -> Result<Response<ExistsReply>, Status> { let req = request.into_inner(); return Ok(Response::new(ExistsReply { flag: self.data.contains_key(&req.key), })); } } }
上面的代码比较简单,基于 Tonic 的规范,实现了我们在 proto 文件中定义的 set/get/delete/exists 方法。细节比较简单,就不赘述了。
接着来启动 gRPC Server。
#![allow(unused)] fn main() { pub async fn start_grpc_server(stop_sx: broadcast::Sender<bool>) { let config = placement_center_conf(); let server = GrpcServer::new(config.grpc_port); server.start(stop_sx).await; } pub struct GrpcServer { port: usize, } impl GrpcServer { pub fn new(port: usize) -> Self { return Self { port }; } pub async fn start(&self, stop_sx: broadcast::Sender<bool>) { let addr = format!("0.0.0.0:{}", self.port).parse().unwrap(); info!("Broker Grpc Server start. port:{}", self.port); let service_handler = GrpcBrokerServices::new(); let mut stop_rx = stop_sx.subscribe(); select! { val = stop_rx.recv() =>{ match val{ Ok(flag) => { if flag { info!("HTTP Server stopped successfully"); } } Err(_) => {} } }, val = Server::builder().add_service(KvServiceServer::new(service_handler)).serve(addr)=>{ match val{ Ok(()) => { }, Err(e) => { panic!("{}",e); } } } } } } }
启动 Server 和上面启动 HTTP Server 差不多,核心是这行代码:
Server::builder().add_service(KvServiceServer::new(service_handler)).serve(addr)
即通过 Tonic 启动 gRPC Server,并增加 GrpcBrokerServices 处理逻辑。最后我们可以来写一个测试用例来测试 KV Server 是否运行正常。
#![allow(unused)] fn main() { #[tokio::test] async fn kv_test() { let mut client = KvServiceClient::connect("http://127.0.0.1:8871") .await .unwrap(); let key = "mq".to_string(); let value = "robustmq".to_string(); let request = tonic::Request::new(SetRequest { key: key.clone(), value: value.clone(), }); let _ = client.set(request).await.unwrap(); let request = tonic::Request::new(ExistsRequest { key: key.clone() }); let exist_reply = client.exists(request).await.unwrap().into_inner(); assert!(exist_reply.flag); let request = tonic::Request::new(GetRequest { key: key.clone() }); let get_reply = client.get(request).await.unwrap().into_inner(); assert_eq!(get_reply.value, value); let request = tonic::Request::new(DeleteRequest { key: key.clone() }); let _ = client.delete(request).await.unwrap().into_inner(); let request = tonic::Request::new(ExistsRequest { key: key.clone() }); let exist_reply = client.exists(request).await.unwrap().into_inner(); assert!(!exist_reply.flag); } }
至此,我们的 gRPC Server 的框架就基本搭建完成了。接下来就是按照上面的流程去添加自己的服务就可以了。
需要注意的是,上面的代码只是最基本的 gRPC Server 的实现,在Rust gRPC Server 中,还有比如 负载均衡、TLS、鉴权、拦截器、压缩 等高级功能。这块就不展开讲了,直接看官网文档 《Tonic 库》 即可。
细心的同学可能会关注到上面的代码有变量 stop_sx: broadcast::Sender,那它是起什么作用的呢?
broadcast::Sender 是 Tokio 提供的 Channel,用于在多个Task之间通信,详细资料可以看 《Tokio Channel》。可以看到 stop_sx 是 Tokio 中的 broadcast 类型,broadcast 是一种广播通道,可以有多个Sender端以及多个Receiver端,任何一个Sender发送的每一条数据都能被所有的Receiver端看到。所以我们通过 broadcast Channel 来接收进程停止信号,并分发给所有的broadcast Receiver,从而达到优雅停止所有线程的目的。
Tokio 并行运行多个服务
先来看一段代码,你能从下面这段代码中看出什么问题吗?
#![allow(unused)] fn main() { pub async fn start_server(stop_sx: broadcast::Sender<bool>) { let state = HttpServerState::new(); start_http_server(state, stop_sx.clone()).await; start_grpc_server(stop_sx.clone()).await; } }
上面代码的问题是: 运行到 start_http_server 函数会卡 住, start_grpc_server 是运行不到的。因为启动 HTTP Server 的代码和启动 gRPC Server 的代码都是卡住的。
那怎么处理呢? 来看下面的代码。
#![allow(unused)] fn main() { pub async fn start_server(stop_sx: broadcast::Sender<bool>) { // 将 grpc server 运行在一个独立的 tokio task 中。 let raw_stop_sx = stop_sx.clone(); tokio::spawn(async move { start_grpc_server(raw_stop_sx).await; }); // 将 http server 运行在一个独立的 tokio task 中。 let raw_stop_sx = stop_sx.clone(); tokio::spawn(async move { let state = HttpServerState::new(); start_http_server(state, raw_stop_sx).await; }); // 等待进程信号 awaiting_stop(stop_sx.clone()).await; } pub async fn awaiting_stop(stop_send: broadcast::Sender<bool>) { // 等待接收 ctrl c 停止线程的信号。 signal::ctrl_c().await.expect("failed to listen for event"); // 当接手到 ctrl c 信号时,给http server 和 grpc server 线程发送停止信号 match stop_send.send(true) { Ok(_) => { info!( "{}", "When ctrl + c is received, the service starts to stop" ); // 在这里允许执行相关回收逻辑。 } Err(e) => { panic!("{}", e); } } } }
这里有两个重点:
-
将 HTTP Server 和 gRPC Server 通过 tokio::spawn 异步运行在一个独立的 tokio task 中,让它不阻塞主进程。
-
依赖 signal::ctrl_c() 来阻塞主进程,让主进程不退出,并且等待接收 ctrl + c 信号,当接收到信号时,就执行相关回收逻辑。
服务成功启动后,当我们按 ctrl+c,服务接收到信号,发送停止信号给多个运行线程,停止HTTP 和 gRPC 服务。效果如下:

总结
tips:每节课的代码都能在项目 https://github.com/robustmq/robustmq-geek 中找到源码,有兴趣的同学可以下载源码来看。
这节课我们首先讲了我们的元数据服务需要什么类型的 Server,这一步是很重要的, 要根据我们的需求和场景选择合适的 Server。可以参考我们前面的选择思考逻辑。
接下来我们讲了HTTP Server 和 gRPC Server 的实现要点以及主体框架的开发。这里总结下主要依赖的库:
-
Tokio:Rust 异步运行的标准库。
-
Axum:Rust 语言的 HTTP Web 框架。
-
Tonic:Rust 语言的 gRPC 框架的实现。
-
Prost:Protocol Buffers 的 Rust 语言的实现,Tonic 及其相关库(tonic_build)关于 Proto 部分都是用这个库。
最后我们讲了基于 tokio spawn、tokio signal、tokioc broadcast channel 来实现 并行运行多个服务 和 程序平滑退出 的能力。
另外,这节课我们只是讲了上面几个库的基本主体功能,课下还需要你深入去研究这几个库的文档,才能在实战中更好地使用它们。
思考题
这里是本节课推荐的相关 issue 的任务列表,请点击查看 《Good First Issue》,任务列表会不间断地更新。欢迎给我的项目 https://github.com/robustmq/robustmq 点个 Star 啊!
数据存储:如何实现单机持久化的存储服务?
本课程为精品小课,不标配音频
你好,我是文强。
上节课我们完成了 Server 模块的开发,接下来我们来实现元数据存储服务中的单机存储层。首先,我们需要来看一下单机存储层的技术方案如何选型。
存储层实现设计考量
如下图所示,我们知道了元数据存储服务的核心是 KV 模型数据的存储。
那如何来实现这个存储层呢?从技术上来看,一般有三个思路:
-
基于文件系统从头实现数据存储。
-
基于现有成熟的分布式存储引擎完成数据的存储,比如 ZooKeeper、etcd等。
-
基于现有成熟的嵌入式键值数据库实现,比如 RocksDB、LevelDB 等。
第一种方案很直观,可能也是我们在选型时首先想到的思路,但是 这种方案是最不推荐的。因为从零开始写一个生产级别的存储层是非常困难的,周期很长,稳定性差。比如需要处理硬件和操作系统随时都有可能丢失或损坏数据的情况,另外写入性能优化需要大量时间投入,还得处理代码 Bug 等情况。
第二种方案是常用的方案,依赖成熟的分布式存储引擎存储数据,是比较快速且稳定的方案。但是这种方案的缺点是需要依赖外部系统,会导致架构复杂,长期运维成本高,另外外部依赖组件的稳定性也会影响主系统的稳定。因为我们要实现的消息队列其中一个设计目标就是: 高内聚和弱外部依赖。如果选择这种方案,就破坏了这个目标,长期来看,不太合理。
第三种方案从某种角度看和第一种是同一个思路。区别是存储层不是自己实现的,而是依赖现有的成熟、可靠、高性能的嵌入式键值存储来实现存储层。这种方案的开发成本低,性能和可靠性也有保证。目前业界主要的嵌入式键值存储有 RocksDB、LevelDB 等。目前使用较多的是 RocksDB,业界很多知名公司和开源项目都在使用它。比如 TiKV、CRDB都是基于 RocksDB 来实现的。
所以,从实现难度、稳定性、性能等三个方面考虑,我们选择了第三种方案。从元数据存储服务(Placement Center) 的功能需求和业界嵌入式键值数据库的功能、稳定性、项目成熟度、社区活跃度来看,我认为 RocksDB 非常适合来当存储层。
接下来我们从功能和架构上简单介绍一下 RocksDB。
RocksDB 简介
从功能层面来看,RocksDB 它是一个嵌入式的键值存储引擎,它提供了下面几个主要的功能函数调用:
-
Put(Key, Value):插入新的Key-Value对或更新现有 Key 的值。
-
Get(Key):获取特定 Key 的值。
-
Delete(Key):删除特定 Key 的值。
-
Merge(Key, Value):将新值与给定 Key 的现有值合并。
-
Seek(key_prefix):匹配指定 Key 的前缀或大于 Key 的前缀。
从这几个函数来看,它是标准 KV 模型的存储,即 set/get/delete/search 类型的方法。
从代码层面来看, RocksDB 就一个 Lib,不是一个 Server,是一个被项目引用的库。也就是说它没有独立的进程运行,是和主进程共享内存空间。比如在 Java 中它是 Maven 的 Package,在 Rust 中,它是一个 crate 上的 Lib,在 Go 中它是一个 Module。
从底层存储的角度来看,RocksDB 的数据是 存储在单机本地硬盘的文件中的,也就是说它是本地存储的。即通过 Put 函数写入的数据,都是存储在本机的文件中的。RocksDB 的本地文件存储结构如下,会包含 sst、log 等等信息。
从底层原理来看,它是基于 LSM-Tree(Log-Structured Merge Tree) 实现的一种本地存储引擎。如果对存储系统有了解的人,对 LSM 应该不会陌生。如果你希望对存储系统了解更多,建议你去研究一下 LSM,它是一种基于日志结构的数据结构,能够高效地存储和更新键值数据。LSM 这块的资料特别多,就不展开细讲了。
因为接下来我们会用到 RocksDB 中的列簇(ColumnFamily) 的概念,所以我们先来了解一下它是什么。
ColumnFamily 是 RocksDB 中的一个逻辑概念,它的功能是 用于 Key 的组织。 比如一部分的 key 存储在 A ColumnFamily,另外一部分 key 存储在 B ColumnFamily。ColumnFamily 和 key 的关系,有点像 MySQL 中 Database 和 table 的关系。Database 用于 table 的逻辑组织,table 一定要属于某个 Database。默认情况下,RocksDB 中所有的 key 都在一个默认的 ColumnFamily 中。
了解了 RocksDB,接下来我们来看一下在元数据存储服务中,如何基于 RocksDB 实现存储层。
Rust Rocksdb 入门
在 Rust 中,需要通过 Rust 库 《rocksdb》 来使用 RocksDB。从代码实现的层面看,主要包含下面七个部分:
-
构建 RocksDB 配置
-
初始化 RocksDB 实例
-
写数据(Write)
-
根据 Key 读取数据(Get)
-
根据 Key 删除数据(Delete)
-
判断 Key 是否存在(Exists)
-
根据前缀读取数据(read_prefix)
接下来我们主要跟随代码实现来一个一个讲解。
- 构建 RocksDB 配置
构建配置的主要工作是设置 RocksDB 实例的配置选项(Options)。代码实现很简单,难点在于: 要理解 RocksDB 的运行原理 , 每个配置项的意义,然后根据自己的场景和要求进行配置优化,这个是和语言无关的。
配置初始化代码如下:
#![allow(unused)] fn main() { fn open_db_opts(config: &PlacementCenterConfig) -> Options { let mut opts = Options::default(); opts.create_if_missing(true); opts.create_missing_column_families(true); opts.set_max_open_files(1000); opts.set_use_fsync(false); opts.set_bytes_per_sync(8388608); opts.optimize_for_point_lookup(1024); opts.set_table_cache_num_shard_bits(6); opts.set_max_write_buffer_number(32); opts.set_write_buffer_size(536870912); opts.set_target_file_size_base(1073741824); opts.set_min_write_buffer_number_to_merge(4); opts.set_level_zero_stop_writes_trigger(2000); opts.set_level_zero_slowdown_writes_trigger(0); opts.set_compaction_style(DBCompactionStyle::Universal); opts.set_disable_auto_compactions(true); let transform = SliceTransform::create_fixed_prefix(10); opts.set_prefix_extractor(transform); opts.set_memtable_prefix_bloom_ratio(0.2); return opts; } }
这段代码很简单,直接看这个 《Rust RocksDB Options》 文档即可。默认情况下,使用 Options::default() 可得到默认配置,这些配置可以满足大部分场景。
因为 RocksDB 的配置优化是一个很大和很复杂的话题,如果要进行针对性的配置调优,你就需要去看一下这个文档 《RocksDB 官方 wiki》,去对 RocksDB 的底层运行原理(主要是LSM-Tree)、配置项所表达的意义有更多的了解,才能找到最适合自己场景的配置项。
- 初始化 RocksDB 实例
这一步的目的是 初始化一个可以操作 RocksDB 的对象实例。主要流程是构建配置,判断是否已经初始化过 RocksDB,如果没有就初始化 DB,然后打开需要操作的列簇(ColumnFamily)即可。
#![allow(unused)] fn main() { // 初始化RocksDB 配置 let opts: Options = Self::open_db_opts(config); // 配置 RocksDB 的数据目录 let db_path = format!("{}/{}", config.data_path, "_storage_rocksdb"); // 判断 RocksDB 是否初始化成功,否则进行初始化。 if !Path::new(&db_path).exists() { DB::open(&opts, db_path.clone()).unwrap(); } // 初始化 RocksDB 中的列簇。 let cf_list = rocksdb::DB::list_cf(&opts, &db_path).unwrap(); let mut instance = DB::open_cf(&opts, db_path.clone(), &cf_list).unwrap(); }
上面这段代码需要关注的点是: 初始化后的 instance 全局只能有一个。即一个 RocksDB 目录只能同时被一个实例持有,不能多次 Open 一个 RocksDB 目录,否则就会报下面的错误。

所以在实际使用中,需要 通过 Arc 在多线程之间共享 RocksDB instance,即 Arc,代码如下:
#![allow(unused)] fn main() { let rocksdb_engine_handler: Arc<RocksDBEngine> = Arc::new(RocksDBEngine::new(&config)); }
在这里,你就会用到智能指针的 Arc ,通过它可以让同一个 RocksDBEngine 在多个线程中共享。
- 写数据(Write)
写数据代码实现比较简单。流程是先选择ColumnFamily,通过 serde_json 序列化数据,最后通过 put_cf 方法将数据写入到 RocksDB 中。
#![allow(unused)] fn main() { pub fn write<T: Serialize + std::fmt::Debug>( &self, cf: &ColumnFamily, key: &str, value: &T, ) -> Result<(), String> { match serde_json::to_string(&value) { Ok(serialized) => self .db .put_cf(cf, key, serialized.into_bytes()) .map_err(|err| format!("Failed to put to ColumnFamily:{:?}", err)), Err(err) => Err(format!( "Failed to serialize to String. T: {:?}, err: {:?}", value, err )), } } }
上面这段代码需要注意的是,写入数据必须选择ColumnFamily,原因是 作为元数据服务,它需要存储不同类型的数据,并且长期可能有较大的数据量。为了长期扩容、拆分、隔离的方便,就需要将数据进行逻辑拆分。
- 读(Get)/ 删除(Delete)数据,并判断数据是否存在(Exists)
读数据是通过RocksDB 的 get_cf 方法来获取到数据,Decord 后返回即可。
删除和判断数据是否存在是通过 delete、key_may_exist_cf 函数来完成功能。
#![allow(unused)] fn main() { // Read data from the RocksDB pub fn read<T: DeserializeOwned>( &self, cf: &ColumnFamily, key: &str, ) -> Result<Option<T>, String> { match self.db.get_cf(cf, key) { Ok(opt) => match opt { Some(found) => match String::from_utf8(found) { Ok(s) => match serde_json::from_str::<T>(&s) { Ok(t) => Ok(Some(t)), Err(err) => Err(format!("Failed to deserialize: {:?}", err)), }, Err(err) => Err(format!("Failed to deserialize: {:?}", err)), }, None => Ok(None), }, Err(err) => Err(format!("Failed to get from ColumnFamily: {:?}", err)), } } // 根据 key 删除数据 pub fn delete(&self, cf: &ColumnFamily, key: &str) -> Result<(), RobustMQError> { return Ok(self.db.delete_cf(cf, key)?); } // 判断 key 是否存在 pub fn exist(&self, cf: &ColumnFamily, key: &str) -> bool { self.db.key_may_exist_cf(cf, key) } }
- 根据前缀读取数据(read_prefix)
在实际项目中,除了 Set 和 Get 的需求,还有一个需求你经常会用到,就是 前缀搜索。即根据某个 Key 的前缀来获取这个 Key 对应的所有数据。
比如我们需要存储集群中的 User,每个 User 的 key 如下:
#![allow(unused)] fn main() { pub fn storage_key_mqtt_user(cluster_name: &String, user_name: &String) -> String { return format!("/mqtt/user/{}/{}", cluster_name, user_name); } }
如果要获取集群中所有的用户列表,肯定不能找一个地方存储所有的客户信息,然后 foreach 循环一个一个去获取。此时就可以用前缀搜索,前缀搜索的 key 如下:
#![allow(unused)] fn main() { pub fn storage_key_mqtt_user_cluster_prefix(cluster_name: &String) -> String { return format!("/mqtt/user/{}", cluster_name); } }
接下来,我们来看一下如何实现前缀搜索。
RocksDB 中提供了前缀搜索的功能。因为 RocksDB 底层存储数据时是根据 Key 排序存储的,所以前缀搜索的底层逻辑是: 先通过 seek 方法找到该前缀对应的第一个 Key,再通过next 方法一个一个往后获取数据,从而得到该前缀对应的所有Key。
#![allow(unused)] fn main() { // Search data by prefix pub fn read_prefix( &self, cf: &ColumnFamily, search_key: &str, ) -> Vec<HashMap<String, Vec<u8>>> { // 获取 ColumnFamily 的迭代器 let mut iter = self.db.raw_iterator_cf(cf); // 搜索到第一个匹配这个前缀的 key iter.seek(search_key); let mut result = Vec::new(); // 获取下一个 key 的值 while iter.valid() { let key = iter.key(); let value = iter.value(); let mut raw = HashMap::new(); // 如果 key 和 value 都为空,则退出循环 if key == None || value == None { break; } let result_key = match String::from_utf8(key.unwrap().to_vec()) { Ok(s) => s, Err(_) => continue, }; // 如果key 不匹配前缀,说明已经获取到所有这个前缀的 key,则退出循环。 if !result_key.starts_with(search_key) { break; } raw.insert(result_key, value.unwrap().to_vec()); result.push(raw); iter.next(); } return result; } }
这里,不知道你是否注意到下面这几行代码,代码的语意是: 判断获取到的数据的Key 是否是搜索的前缀,否则,退出循环。
#![allow(unused)] fn main() { if !result_key.starts_with(search_key) { break; } }
这段代码非常重要,也是前缀搜索的核心。前面说到 RocksDB 的底层数据是根据 Key 顺序存储的,所以先通过 seek 定位到匹配前缀的第一个 key,然后往后逐个获取。
但是需要注意的是: next 方法不会判断数据的 Key 是否匹配这个前缀。如果不加这个判断,则会从 seek 到的 key 开始一直往后获取到整个 RocksDB 的所有数据。
所以每一次拿到数据后,就需要判断 Key 是否匹配我们需要的前缀,如果不匹配,就说明已经获取到同一个前缀的所有数据了,就可以退出循环。
到这里,我们就完成了 RocksDB 基础库的集成使用。从某种意义上来说,我们也就完成了单机存储层的开发。
比想象中简单非常多是吧, 这就是使用现成的嵌入式键值库的好处,也是开源项目 RocksDB、LevelDB 设计的初衷,大大地简化高性能高可靠单机存储层的开发。
接下来我们来完成我们需要的功能: KV 型的数据存储。
使用 RocksDB 存储 KV 数据
我先来问一个问题,我们要存储一个 KV 数据,即 name= “mq”,此时底层应该怎么存储数据呢?
直观来讲,以 name 为 Key,mq 为 Value 存储就可以了。但是扩展一下: 我们是不是需要知道数据的写入时间 、 数据来源(即来源 IP)等等信息。因此我们在底层存储数据时,就需要对数据进行包装,存储一些通用的数据,比如创建时间。
所以我们在底层存储数据的时候,是通过数据结构 StorageDataWrap 来包装保存数据的。
#![allow(unused)] fn main() { #[derive(Serialize, Deserialize, Debug)] pub struct StorageDataWrap { pub data: Vec<u8>, pub create_time: u64, } impl StorageDataWrap { pub fn new(data: Vec<u8>) -> Self { return StorageDataWrap { data, create_time: now_second(), }; } } }
接下来我们以保存数据为例,来看一下我们是如何完成 KV 模型数据存储的。来看下面的代码:
#![allow(unused)] fn main() { fn engine_save<T>( rocksdb_engine_handler: Arc<RocksDBEngine>, rocksdb_cluster: &str, key_name: String, value: T, ) -> Result<(), RobustMQError> where T: Serialize, { let cf = if rocksdb_cluster.to_string() == DB_COLUMN_FAMILY_CLUSTER.to_string() { rocksdb_engine_handler.cf_cluster() } else { return Err(RobustMQError::ClusterNoAvailableNode); }; let content = match serde_json::to_vec(&value) { Ok(data) => data, Err(e) => return Err(RobustMQError::CommmonError(e.to_string())), }; let data = StorageDataWrap::new(content); match rocksdb_engine_handler.write(cf, &key_name, &data) { Ok(_) => { return Ok(()); } Err(e) => { return Err(RobustMQError::CommmonError(e)); } } } }
这里有 4 个关注点:
-
RocksDBEngine 是封装了 RocksDB 读写的一个Struct,里面封装了对RocksDB的打开、读、写等操作。
-
rocksdb_engine_handler: Arc:你会发现这是通过智能指针 Arc 在多线程之间共享 RocksDBEngine。原因就是我们上面提到的,一个 RocksDB 只能由一个RocksDB对象持有,故需要在进程启动时,通过RocksDB 提供的DB::open_cf打开 RocksDB,然后通过智能指针 Arc 在多个线程中共享使用 RocksDBEngine。
-
为了后续的拆分隔离方便,数据默认是写入到名为 cluster 的 ColumnFamily。
-
数据值 Value 是一个泛型,它可以接收任何类型的数据,然后持久化存储。泛型 T 需要通过 Where 关键字限制 Value 必须实现 Serialize Trait。因为只有实现 Trait,它才能进行序列化。
tips:在这部分,你就需要去复习泛型、Arc、Where 的语法,从实际编码角度来看,这三种语法的应用非常广泛。
这里留一个思考题: 我们在 engine_save 和 write 方法中都有使用 serde_json 执行序列化,是不是重复了?是不是可以简化代码 ?
接下来我们可以封装一个 Struct 来根据 Key 保存数据。来看下面的代码:
#![allow(unused)] fn main() { pub struct KvStorage { rocksdb_engine_handler: Arc<RocksDBEngine>, } impl KvStorage { pub fn new(rocksdb_engine_handler: Arc<RocksDBEngine>) -> Self { KvStorage { rocksdb_engine_handler, } } pub fn set(&self, key: String, value: String) -> Result<(), RobustMQError> { return engine_save_by_cluster(self.rocksdb_engine_handler.clone(), key, value); } } }
这段代码比较简单,Key 和 Value 都是 String 类型,直接调用engine_save_by_cluster保存即可。
在业务逻辑上,保存数据直接用 KvStorage 即可,如下所示:
#![allow(unused)] fn main() { pub fn set(&self, value: Vec<u8>) -> Result<(), CommonError> { let req: SetRequest = SetRequest::decode(value.as_ref())?; let kv_storage = KvStorage::new(rocksdb_engine_handler.clone()); return kv_storage.set(req.key, req.value); } }
其他 Get、Delete、List、Exists 方法,思路都是类似的,就不展开了,你可以查看 Demo 中的代码,了解更多。
总结
tips:每节课的代码都能在项目 https://github.com/robustmq/robustmq-geek 中找到源码,有兴趣的同学可以下载源码来看。
这节课我们从选型考量开始讲起,讨论了为什么要选择 RocksDB,Rust RocksDB 的使用细节,以及如何使用 RocksDB 来存储 KV 型数据,进而实现了元数据存储服务的单机存储层。
从技术上来看,我们需要去重点理解为什么要用 RocksDB,有没有其他的选项。因为这个思路是通用的,我们实现其他存储系统的时候都可以借鉴。
在业界,使用 RocksDB 来实现单机存储层,是一个应用非常广泛的方案,如果你有类似的需求,建议优先考虑 RocksDB。
从 Rust 语法方面,泛型、序列化、智能指针等语法都会用到,需要你继续加深对这些语法的理解。
思考题
这里是本节课推荐的相关 issue 的任务列表,请点击查看 《Good First Issue》,任务列表会不间断地更新。欢迎给我的项目 https://github.com/robustmq/robustmq 点个 Star 啊!
基于Raft协议构建分布式集群(一)
本课程为精品小课,不标配音频
你好,我是文强。
前面我们写完了单机存储层,为了提升数据的可靠性,现在我们需要将单点存储升级为分布式存储。从技术上看,实现分布式存储需要两步:
-
构建基于某个一致性协议的分布式集群。
-
在构建完成的分布式集群上存储数据。
所以接下来,我会在 7、8、9 三节课讲如何基于 Raft 协议构建多节点组成的分布式集群,在第 10 节课会讲如何基于构建完成的分布式集群完成数据的分布式多副本存储。
Tips:接下来我们主要从代码实现的角度讲解如何基于 Raft 协议构建集群。由于篇幅和 Raft 协议本身的复杂性,无法讲得特别细致,因此建议你去复习一下 Raft 协议的内容。如有更多问题,欢迎在留言区或者进交流群与我讨论。
如何选择合适的分布式一致性协议,这个理论基础我在之前的课程《深入拆解消息队列 47 讲》的 《17|可靠性:分布式集群的数据一致性都有哪些实现方案?》 中已经系统讲过了,这里不再重复。
从技术上来看,业界有 Raft、Paxos、Zab、ISR 等一致性协议的实现。虽然各种协议的理论和具体实现都不一样,但是从原理上看它们都具备在生产环境中使用的条件。那么我们为什么选择 Raft 协议,不选择其他的协议呢?
为什么选择 Raft 协议
我们最终选择 Raft 协议主要有三点考虑:
-
如果有现成的合适的一致性协议,我们就不考虑从头实现一个一致性协议。
-
从功能上看,Raft 协议和其他一致性协议都满足 Placement Center 功能定义上的需求。
-
Rust 中有比较成熟的 Raft 协议库,并且这些库已经在成熟项目中使用,其他协议不满足这个条件。
这个思考过程还可以展开一下,希望能给你带来一些参考价值。
首先考虑的一个因素是, 选择的协议必须满足我们的业务需求。从 Placement Center 所提供的功能、数据量、QPS 来看,它的业务特点主要是存储元数据,不会有非常大的数据量,但是需要数据的高可靠,不能丢数据。所以从功能上来看,基本所有的一致性协议都可以满足我们的需求。
另外因为一致性协议本身的复杂性,从工程实现角度来看,从头写一个一致性协议非常难,工作量大,周期也长,所以大多数情况下是没必要的。因此选择的一个重要标准就是, 使用的语言有没有现成的一致性协议的实现。
从 crates.io 上看有几个成熟的 Raft 库实现,比如 openraft、raft-rs 等,但其他一致性协议,比如 Paxos,却没有比较成熟的实现。这个现象从技术上看也符合预期,因为 Paxos 的工程化落地就非常难。Raft 本身就是为了简化 Paxos 的工程实现而设计出来的。
然后考虑的第三个因素是 项目库的成熟度如何,是否具备工业化使用基础。Rust 中的 Raft 实现主要有 openraft 和 raft-rs 两个库,最后我们选择了 raft-rs 库,主要是因为:
-
raft-rs 是 TIDB 开源的库,已经经过了 TiKV 这个成熟项目的验证。
-
它只实现了 Raft 协议中的共识算法部分,其余部分自己实现,比如网络、存储层。从长期的性能、调优的角度来看,自主实现得越多,可控性越高,那么优化也就越好做。
接下来我们来简单了解一下 raft-rs 这个库。了解它主要有什么,如果要使用它来实现基于 Raft 协议的分布式集群总共要做哪些事情。
raft-rs 库的使用概述
在此之前,我建议你先复习一下 Raft 协议。这里给你推荐一个 Raft 协议的动图原理展示,如果你能够理解这个动图所表达的意思,说明你已经基本掌握了 Raft 协议。
下面来看 Raft 论文中的一张经典架构图。
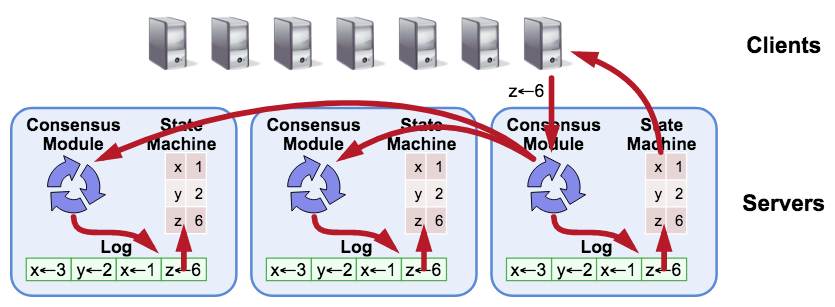
结合 Raft 原理可以知道: Raft 是通过日志来复制状态机,也就是说如果我们能保证所有机器上的日志顺序是一致的,那么按顺序执行所有日志后,则每个节点上的状态机就能达到一致的状态。
所以从代码实现来看,一个完整的Raft模型包含 共识模块、 Log、 状态机、 传输层 四个部分。
-
共识模块: 是指 Raft 核心共识算法部分。它负责完成发起选举、选举过程、心跳保持、检测心跳超时、重新发起选举等工作,也就是我们最熟悉的 Raft 算法部分。raft-rs 库就是完成这部分工作的,但也只是完成了这部分工作。
-
状态机: 是指驱动 Raft 共识模块工作的线程。它会不断检测共识模块是否需要执行某些操作,比如选举、心跳。如果需要就根据共识模块的运行结果执行对应的操作,比如给其他 Raft Node 发送消息,持久化保存数据等等。
-
Log(存储层): 是指存储 Raft 状态机运行过程中产生的 Log(也叫做 Entry)的模块,比如选举出一个新的 Leader,就会生成一个新的 Entry 需要持久化存储。
-
传输层:是指用于多个 Raft 节点之间通信的网络层。比如 Follower 节点向其他节点发起选举、Leader 向 Follower 发送心跳等等行为,都需要通过传输层将 Raft Message 发送给其他节点。
你现在可能对这四个部分有点模糊,不太理解。没关系,这很正常,你只要先记住有这四个部分,以及它们大致的作用即可。接下来我们还会详细讲解。
因此从开发的角度,基于 raft-rs 库来构建集群就有四个主要工作:
-
构建存储层: 即实现用于持久化存储 Raft Log 数据的存储层。在本次实现中,我们是基于 RocksDB 来实现的。
-
构建网络层:即实现用于在多个 Raft 节点之间进行通信的模块。在本次实现中,我们是基于 gRPC 来实现的。
-
构建单节点 Raft 状态机:比如分发数据、检测心跳、切换Leader等等。
-
整合状态机、存储层、网络层 : 构建成一个完整的 Raft 集群。
首先我们来看存储层的实现。
Tips:建议你把第 7、8、9 节课当作一个整体来看,如果在前两讲遇到不理解的地方可以先跳过,等看完三节课的全部内容再回头来看,就比较好理解了。
Raft Log 和 Storage Trait
我们已知,存储层的作用是用来持久化存储 Raft 运行过程中产生的 Log 数据。那什么是 Raft Log 呢?来看下面这张图:
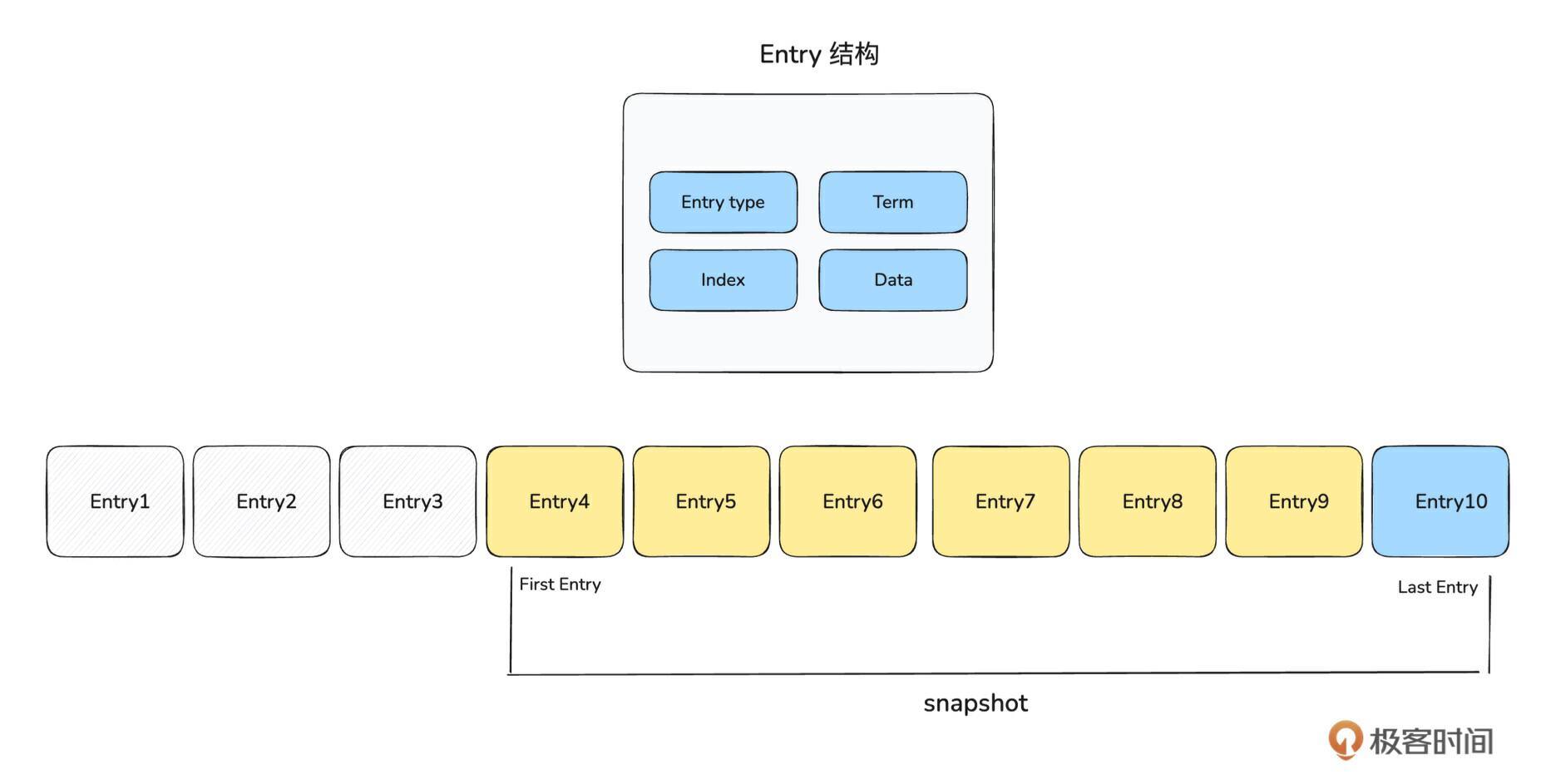
结合上图内容和 Raft 协议算法,我们可以知道, Raft Log 本质上是一系列 Entry 组成的顺序存储的日志。Entry 表示一个 Raft Log,为了节省存储空间和加快快照的生成速度,一些没用的 Raft Log 需要清理删除。所以 First Entry 是指至今还保存的最早的那条 Entry,Last Entry 是指最新的那条 Entry。快照一般指当前所有有效的 Entry 的集合。
因此,Raft Log 的核心其实是 Entry。 每一个 Entry 由 Entry Type、 Index、 Term、 Data 四部分组成。
- Entry Type:表示该 Entry 包含什么类型的数据,如下枚举类所示,有普通数据和配置变更数据两种类型。
#![allow(unused)] fn main() { pub enum EntryType { EntryNormal = 0, EntryConfChange = 1, EntryConfChangeV2 = 2, } }
-
Index:指这个 Entry 在顺序存储的日志中的偏移量。
-
Term:是 Raft 协议中的概念,用于保证 Raft Log 的一致性和顺序性。Term 从 0 开始,如果 Leader 切换一次,Term 就会 +1, 每一个 Entry 都有属于自己的 Term。
-
Data:是 Raft Log 的具体内容,不同 Entry Type 的内容是不一样。
讲到这里,我们大概知道了 Raft Log 的存储结构。接下来我们来理解一下 raft-rs 库中提供的一个名为 Storage 的 Trait。
它定义了 Raft 状态机在运行过程中会读写哪些数据。因此只要了解这个 Trait,也就理解了 Raft 运行过程中会操作哪些数据了。先来看 Storage Trait 的定义:
#![allow(unused)] fn main() { pub trait Storage { fn initial_state(&self) -> Result<RaftState>; fn entries( &self, low: u64, high: u64, max_size: impl Into<Option<u64>>, context: GetEntriesContext, ) -> Result<Vec<Entry>>; fn term(&self, idx: u64) -> Result<u64>; fn first_index(&self) -> Result<u64>; fn last_index(&self) -> Result<u64>; fn snapshot(&self, request_index: u64, to: u64) -> Result<Snapshot>; } }
从上面代码可以知道 Storage Trait 提供了 initial_state、 entries、 term、 first_index、 last_index、 snapshot 等 6 个方法来读写 Raft 的运行数据。接下来我们结合前面这张图来理解一下每个方法的作用。
1. initial_state
读取节点,本地持久化存储 Raft 集群运行状态信息,状态信息由 HardState 和 ConfState 两部分组成。如下代码所示,状态信息主要包含 Raft 集群的 term、投票者、观察者、Leader、最新 commit index 等信息。
#![allow(unused)] fn main() { pub struct HardState { // 当前 Raft 最新的 term pub term: u64, // 选举出来的 Leader pub vote: u64, // 最新提交的索引 pub commit: u64, } pub struct ConfState { // 投票者列表 pub voters: ::std::vec::Vec<u64>, // 观察者列表 pub learners: ::std::vec::Vec<u64>, ...... } }
这个方法是一个读取操作,也就说这些状态信息是在另外一个流程持久化存储的。这个流程在后面讲 Raft 状态机的时候会讲到。
2. entries
给定 Index 一个范围,比如 low ~ high,从而获取这个范围内的所有 Entry。同样的,这也是一个读取操作,也就是说 Entry 会在另外一个流程写入。同样的,Entry 存储也是在 Raft 状态机部分会讲到。
3. term
给定一个日志的 Index,查看这个 Index 对应的 Entry 所对应的 term。
4. first_index
前面提到,没用的 Entry 会被清理。因此这个方法会返回最早未被清理掉的 Entry 对应的 Index。
5. last_index
获取最新的一条 Entry 所对应的 Index。
6. snapshot
返回当前 Raft Log 的快照数据。快照数据主要包含 当前还保留的所有 Entry 信息。快照是用于当 Follower 数据落后 Leader 太多时,帮助 Follower 恢复到最新数据状态的工具。
这里在实现上需要注意的是:因为快照数据一般很大,所以一般需要异步生成,如果同步生成,会卡住主线程的运行。
讲完了 Raft 的存储层要存储什么数据,接下来我们基于 RocksDB 来实现我们的 Storage:RaftRocksDBStorage。
基于 RocksDB 的 RaftRocksDBStorage
接下来,直接来看我们实现的 RaftRocksDBStorage 的主体代码。
#![allow(unused)] fn main() { impl Storage for RaftRocksDBStorage { fn initial_state(&self) -> RaftResult<RaftState> { let core = self.read_lock(); // 数据是通过 RocksDB 持久化存储 // 通过RaftMachineStorage 的raft_state方法从 RocksDB 中取出 return Ok(core.raft_state()); } fn entries( &self, low: u64, high: u64, _: impl Into<Option<u64>>, _: raft::GetEntriesContext, ) -> RaftResult<Vec<Entry>> { let core = self.read_lock(); // 判断 low index 是否在可用范围内 if low < core.first_index() { return Err(Error::Store(StorageError::Compacted)); } // 判断 high index 是否在可用范围内 if high > core.last_index() + 1 { panic!( "index out of bound (last: {}, high: {})", core.last_index() + 1, high ) } // 从 RocksDB 中依次取出这个范围内的 Index 对应的 Entry let mut entry_list: Vec<Entry> = Vec::new(); for idx in low..=high { let sret = core.entry_by_idx(idx); if sret == None { continue; } entry_list.push(sret.unwrap()); } return Ok(entry_list); } fn term(&self, idx: u64) -> RaftResult<u64> { let core = self.read_lock(); // 判断索引是否在内存中,是的话,直接返回即可。 if idx == core.snapshot_metadata.index { return Ok(core.snapshot_metadata.index); } // 判断 index 是否在可用范围内 if idx < core.first_index() { return Err(Error::Store(StorageError::Compacted)); } // 判断 index 是否在可用范围内 if idx > core.last_index() { return Err(Error::Store(StorageError::Unavailable)); } // 从 RocksDB 中获取 Index 对应的 Entry 的 Term if let Some(value) = core.entry_by_idx(idx) { return Ok(value.term); } // 默认返回当前快照的 Term return Ok(core.snapshot_metadata.term); } fn first_index(&self) -> RaftResult<u64> { let core = self.read_lock(); // 从RocksDB 中获取持久化存储的最早的 index let fi = core.first_index(); Ok(fi) } fn last_index(&self) -> RaftResult<u64> { let core = self.read_lock(); // 从RocksDB 中获取持久化存储的最新的 index let li = core.last_index(); Ok(li) } fn snapshot(&self, request_index: u64, to: u64) -> RaftResult<Snapshot> { info!("Node {} requests snapshot data", to); let mut core = self.write_lock(); // 如果当前快照没准备,就直接返回快照还在准备中的错误。同时触发异步执行构建快照 if core.trigger_snap_unavailable { return Err(Error::Store(StorageError::SnapshotTemporarilyUnavailable)); } else { // 如果快照已经存在,则直接返回快照信息。 let mut snap = core.snapshot(); if snap.get_metadata().index < request_index { snap.mut_metadata().index = request_index; } Ok(snap) } } } }
这段代码比较长,不过框架代码不复杂。主要逻辑都加了注释,这里只总结一下核心逻辑。
-
Raft 运行数据存储在 RocksDB 是通过 RaftMachineStorage 这个对象来完成的。RaftMachineStorage 的实现在下节课我们会详细讲。
-
impl Storage for RaftRocksDBStorage,这是一个 Trait 的语法,表示RaftRocksDBStorage 实现了 raft-rs 定义的 Storage Trait。 -
RaftRocksDBStorage 分别实现了 initial_state、 entries、 term、 first_index、 last_index、 snapshot 等 6 个方法。在这 6 个方法中基于 RaftMachineStorage 对象来完成数据的读写。
当我们完成了 RaftRocksDBStorage 后,怎么用呢?答案是 在创建 Raft Node 时会用到。在 raft-rs 库中,每一个 Raft Node 启动,就需要初始化为 RawNode 对象,此时就需要配置对应的存储层实现,代码如下:
#![allow(unused)] fn main() { // 初始化一个基于 RocksDB 的 Storage Trait 实现 let storage = RaftRocksDBStorage::new(self.raft_storage.clone()); // 初始化 Raft Node let node = RawNode::new(&conf, storage, &logger).unwrap(); }
完成了 RaftRocksDBStorage 开发,我们也就完成了存储层的主体框架的开发。下节课我们还会具体讲一下在 RaftMachineStorage 中如何基于 RocksDB 完成 Raft 运行数据的读写。
总结
tips:每节课的代码都能在项目 https://github.com/robustmq/robustmq-geek 中找到源码,有兴趣的同学可以下载源码来看。
构建分布式集群,关键是选择合适的一致性协议。主要有三点考虑:
-
选择的协议需要能满足我们业务上的需求。
-
使用的语言有没有适合的一致性协议的实现
-
项目库的成熟度如何,是否具备工业化使用基础。
只有当没有符合这些要求的基础库时,才考虑自行实现一致性协议。自行实现一致性协议有很多缺点,比如周期长,开发成本高,稳定性需要经过验证等等。
raft-rs 库只完成共识算法这部分的工作,其他包括 Log 存储、状态机、传输层都得我们自己来实现,所以它不是一个拿来即用的库。基于 raft-rs 库构建集群有一个好处是, 会让你对 Raft 的原理及实现有更深的理解。
raft-rs 中 Log 存储的核心是实现 Storage 的 Trait。Storage 提供了 initial_state、 entries、 term、 first_index、 last_index、 snapshot 等 6 个方法。只要实现这个 Trait,就算完成了存储层的开发。
思考题
这里是本节课推荐的相关 issue 的任务列表,请点击查看 《Good First Issue》。 另外欢迎给我的项目 https://github.com/robustmq/robustmq 点个 Star 啊!
基于Raft协议构建分布式集群(二)
本课程为精品小课,不标配音频
你好,我是文强。
这节课我们继续完善基于 Raft 协议开发的分布式集群,我们会完成存储层和网络层这两部分的开发。接上节课的内容,我们首先来看一下 RaftMachineStorage 的实现逻辑。
Raft 存储层:RaftMachineStorage
从代码上看,RaftMachineStorage 的作用是 使用 RocksDB 来持久化存储 Raft 运行数据。由于 RaftMachineStorage 的代码较多,这里我就不把全部代码贴出来了,建议你先去看一下文件 《RaftMachineStorage》 中的代码。
下面这张图是 RaftMachineStorage 的功能列表。
从函数名称中可以知道,RaftMachineStorage 的功能就是对 Entry、HardState、ConfState、First Index、Last Idnex、Uncommit Index、Snapshot 等数据进行读写。
因为 RocksDB 是 KV 存储模型,因此我们需要先定义保存数据的 Key。来看下面这段代码:
#![allow(unused)] fn main() { // 存储未过期的第一个Entry的Index pub fn key_name_by_first_index() -> String { return "/raft/first_index".to_string(); } // 存储最新的一个 Entry 的Index pub fn key_name_by_last_index() -> String { return "/raft/last_index".to_string(); } // 保存 Raft 元数据 HardState pub fn key_name_by_hard_state() -> String { return "/raft/hard_state".to_string(); } // 保存 Raft 元数据 ConfState pub fn key_name_by_conf_state() -> String { return "/raft/conf_state".to_string(); } // 根据Entry的 Index 保存Entry 信息 pub fn key_name_by_entry(idx: u64) -> String { return format!("/raft/entry/{}", idx); } // 保存未正常 commit 的index列表 pub fn key_name_uncommit() -> String { return "/raft/uncommit_index".to_string(); } // 保存快照信息 pub fn key_name_snapshot() -> String { return "/raft/snapshot".to_string(); } }
在这段代码中,我们分别为保存 First Index、Last Index、HardState、ConfState、Entry、Uncommit、Snapshot 设计了保存的 Key。 因此你也就需要了解 Raft 运行过程中需要保存的这些数据。
从逻辑上来看,这些数据可以分为 Entry、 Raft 运行状态、 快照 三个类型。接下来我们来看这些数据的写入实现,因为读取类操作比较简单,就不展开了。先来看Entry。
#![allow(unused)] fn main() { pub fn append(&mut self, entrys: &Vec<Entry>) -> RaftResult<()> { // 如果 Entry 为空,则不保存 if entrys.len() == 0 { return Ok(()); } // 判断 Entry 列表中的 index 是否符合规范 let entry_first_index = entrys[0].index; let first_index = self.first_index(); if first_index > entry_first_index { panic!( "overwrite compacted raft logs, compacted: {}, append: {}", first_index - 1, entry_first_index, ); } let last_index = self.last_index(); if last_index + 1 < entry_first_index { panic!( "raft logs should be continuous, last index: {}, new appended: {}", last_index, entry_first_index, ); } // 循环保存 Entry for entry in entrys { debug!(">> save entry index:{}, value:{:?}", entry.index, entry); // 将 Entry 转化为 Vec 类型 let data: Vec<u8> = Entry::encode_to_vec(&entry); // 将 Entry 保存在名为 /raft/entry/{index} 的 key 中 let key = key_name_by_entry(entry.index); self.rocksdb_engine_handler .write(self.rocksdb_engine_handler.cf_cluster(), &key, &data) .unwrap(); // 更新未 commit 的 index信息 self.uncommit_index.insert(entry.index, 1); // 更新 last index self.save_last_index(entry.index).unwrap(); } // 持久化存储未 commit 的 index self.save_uncommit_index(); return Ok(()); } }
上面这段代码的功能是: 接收 Entry 列表并保存。主要代码都加了注释,我们总结下核心逻辑:
-
首先进行数据校验,判断 Entry 列表是否为空,以及 Entry 对应的 index 是否可用。
-
循环以 /raft/entry/{index} 为 Key,在 RocksDB 中持久化保存 Entry,同时更新 last index 信息。
-
因为 Entry 保存后,属于 uncommit 的数据,所以需要将 Entry 对应的 index 暂存到 uncomit 列表。
完成了这三步就完成了 Entry 和 Uncommit Index 的存储,同时也更新了最新的 Last Index。因为 Entry 是会过期的,所以当 Entry 过期时,First Index 也会被更新。
再来看 Raft 运行状态的写入实现。在上节课我们知道,Raft 运行状态主要是 HardfState 和 ConfState 两个数据,来看它的代码实现。
#![allow(unused)] fn main() { pub fn save_hard_state(&self, hs: HardState) -> Result<(), String> { let key = key_name_by_hard_state(); let val = HardState::encode_to_vec(&hs); self.rocksdb_engine_handler .write(self.rocksdb_engine_handler.cf_cluster(), &key, &val) } pub fn save_conf_state(&self, cs: ConfState) -> Result<(), String> { let key = key_name_by_conf_state(); let value = ConfState::encode_to_vec(&cs); self.rocksdb_engine_handler .write(self.rocksdb_engine_handler.cf_cluster(), &key, &value) } }
从上面代码可以看到,它的逻辑很简单,就是拿到数据写入到对应的 Key。但是关键问题是: HardState 和 ConfState 是哪里来的(哪里生成的)?
从技术上看,这两个数据的来源是 Raft 状态机,也就是 raft-rs 这个库的内部。raft-rs 实现了 Raft 的共识算法,在内部完成了发起选举、选举过程、心跳保持、用户数据保存等主要逻辑。也就说当 Raft 状态机向前驱动时,就会产生这两个数据,我们拿到这两个数据持久化存储即可。
最后来看 snapshot(快照)数据的写入。
当前快照数据的实现逻辑是:将所有未过期的 Entry 读取出来,整理成一份数据,再保存到 RocksDB 中,以便 Follower 拉取快照时更快。代码实现如下:
#![allow(unused)] fn main() { pub fn create_snapshot(&mut self) { let mut sns = Snapshot::default(); // 获取快照的元数据 let meta = self.create_snapshot_metadata(); sns.set_metadata(meta.clone()); // 获取所有的 Entry,整理成一份数据 let all_data = self.rocksdb_engine_handler.read_all(); sns.set_data(serialize(&all_data).unwrap()); // 将快照数据再持久化保存的一个固定的快照 Key 中。 self.save_snapshot_data(sns); self.snapshot_metadata = meta.clone(); } // 读取 HardState 和ConfState,构建快照的元数据 pub fn create_snapshot_metadata(&self) -> SnapshotMetadata { let hard_state = self.hard_state(); let conf_state = self.conf_state(); let mut meta: SnapshotMetadata = SnapshotMetadata::default(); meta.set_conf_state(conf_state); meta.set_index(hard_state.commit); meta.set_term(hard_state.term); return meta; } }
代码注释比较清晰,这里就不展开了。需要注意的是,上面的实现会把快照数据再存储到 RocksDB,会导致重复存储两份数据。因此从实现来看是有优化空间的。
到这里,存储层的实现逻辑基本就讲完了。接下来我们看看网络层的实现。
为了帮助你更好地理解网络层的作用,我们需要先来理解一下 Raft 节点之间是如何通信的。
Raft 节点间的通信流程
在我看到 raft-rs 这个库时,就有一个很大的疑问: 它既然只实现了共识算法,那么多个 Raft 节点之间的投票和选举、心跳保持、心跳超时 / Leader 宕机触发重新选举等等这些流程是怎么实现的呢?
这里核心的是:多个节点间要如何交换信息?
回答这个问题之前,我们先来看下面这张 Raft 节点间交互的原理图。
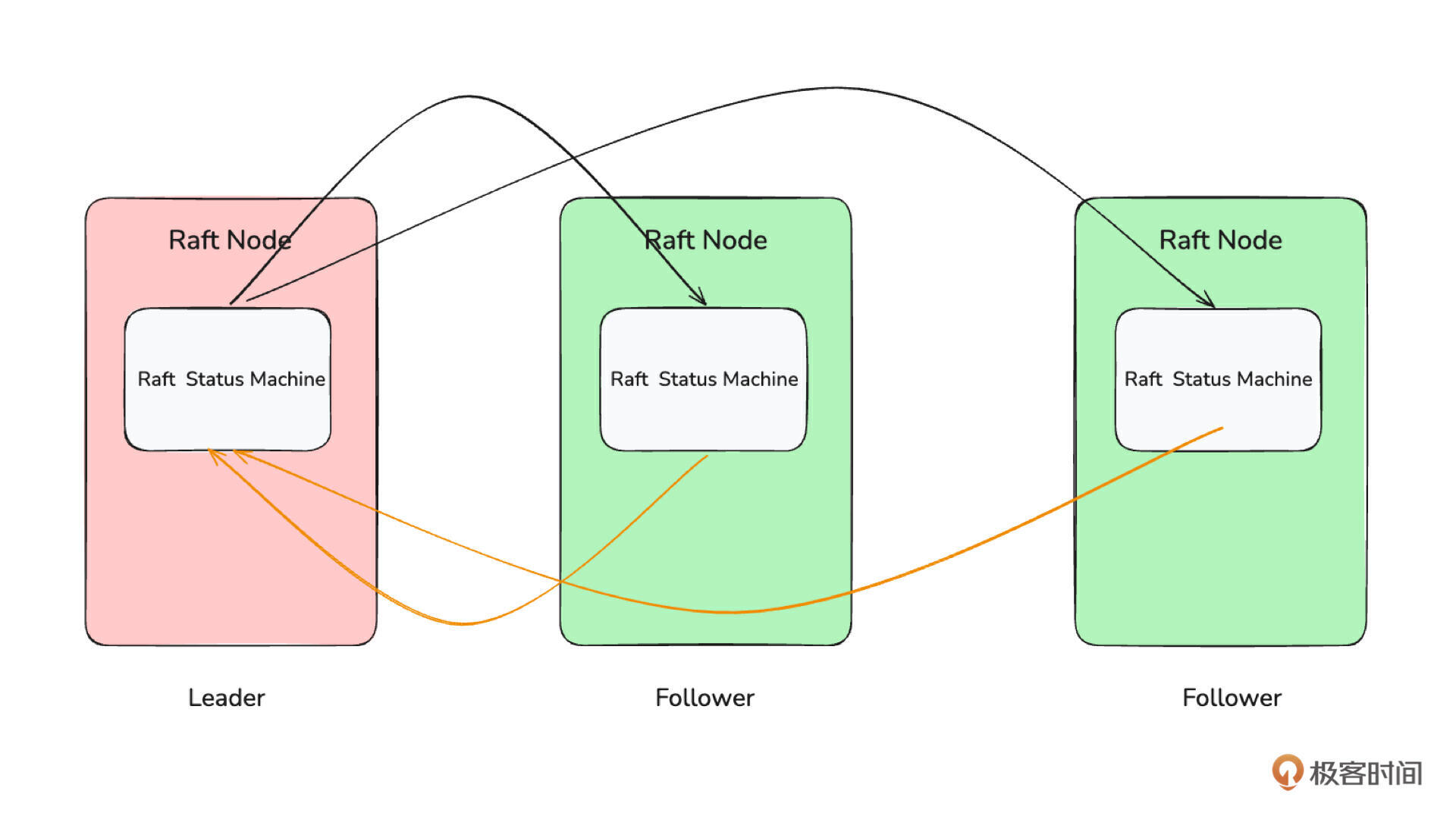
如上图所示,每个 Raft 节点上都会运行一个 Raft Machine(状态机)。每个状态机内部有定时驱动机制,用于定时驱动 Raft 状态向前运行。比如定时检测心跳是否过期,是否需要发起选举等等。
从代码实现的角度,也就是说,节点会根据自身的角色(比如 Leader 和 Follower)触发不同的行为,从而产生不同的 Message(消息),再将这些 Message 发送给其他 Raft 节点。那生成的都是哪些消息呢? raft-rs 库定义了多种 MessageType 来标识不同类型的消息,代码如下所示:
#![allow(unused)] fn main() { #[derive(Clone,PartialEq,Eq,Debug,Hash)] pub enum MessageType { MsgHup = 0, MsgBeat = 1, MsgPropose = 2, MsgAppend = 3, MsgAppendResponse = 4, MsgRequestVote = 5, MsgRequestVoteResponse = 6, MsgSnapshot = 7, MsgHeartbeat = 8, MsgHeartbeatResponse = 9, MsgUnreachable = 10, MsgSnapStatus = 11, MsgCheckQuorum = 12, MsgTransferLeader = 13, MsgTimeoutNow = 14, MsgReadIndex = 15, MsgReadIndexResp = 16, MsgRequestPreVote = 17, MsgRequestPreVoteResponse = 18, } }
从上面的消息类型可以看到,有投票、心跳、快照、Leader 切换等等不同类型的消息。举个例子,当用户往 Leader 节点写入数据,这条数据就需要发送给 Follwer 节点。因此 Leader 节点上的状态机就会生成一条类型为 MsgPropose 的Message,然后通过网络层将这个 Message 发送给 Follower 节点。Follower 节点遇到心跳超时时,本节点上的 Raft 状态机也会生成 MsgRequestVote 类型的消息,并将这条消息发送给其他节点。
了解完了 Raft 节点间的通信流程,接下来我们来看一下 Raft Node 网络层的代码实现。
基于 gRPC 的网络层实现
在上节课我们讲到,在网络层我们选择了 gRPC 来做通信协议。所以从代码实现的角度,整体就分为两步:
- 定义 gRPC proto 文件
- 实现 gRPC Service
先来看 gRPC proto 文件的定义。
#![allow(unused)] fn main() { // 定义名为SendRaftMessage的 rpc 方法,用于在两个Raft节点间的传递消息 rpc SendRaftMessage(SendRaftMessageRequest) returns(SendRaftMessageReply) {} message SendRaftMessageRequest{ // 需要传递的消息内容,是一个 bytes 类型 bytes message = 1; } // 返回参数为空即可,即成功不需要返回值 message SendRaftMessageReply{ } }
在上面的 proto 中,定义了一个名为 SendRaftMessage 的 RPC 方法,以及方法对应的请求和返回参数。
参数很简单,需要重点关注是 message 字段,它是 bytes 类型的数据,是由 raft-rs 中名为 Message 的结构体 encode 得到的。 raft-rs 中的 Message 结构体,就是前面提到的 Raft 状态机驱动时生成的需要发给其他 Raft Node 的消息。它的定义如下:
#![allow(unused)] fn main() { message Message { MessageType msg_type = 1; uint64 to = 2; uint64 from = 3; uint64 term = 4; uint64 log_term = 5; uint64 index = 6; repeated Entry entries = 7; uint64 commit = 8; uint64 commit_term = 15; Snapshot snapshot = 9; uint64 request_snapshot = 13; bool reject = 10; uint64 reject_hint = 11; bytes context = 12; uint64 deprecated_priority = 14; int64 priority = 16; } }
可以看到 Message 中有一个前面提到的 MessageType 字段,Message 用这个字段来区分不同类型的消息。结构体内容就不细讲了,大部分比较好理解,想了解更多可以去看这个 《raft-rs eraftpb.proto》 文件。
所以在网络层,我们只要将 Message encode 成 Vec,传递给其他节点即可,代码如下:
#![allow(unused)] fn main() { // 将 Message 转化为Vec<u8>类型 let data: Vec<u8> = Message::encode_to_vec(&msg); // 初始化请求结构 let request = SendRaftMessageRequest { message: data }; // 将消息发送给其他节点 match send_raft_message(self.client_poll.clone(), vec![addr.clone()], request).await { Ok(_) => debug!("Send Raft message to node {} Successful.", addr), Err(e) => error!( "Failed to send data to {}, error message: {}", addr, e.to_string() ), } }
接着来看 gRPC Service 的实现,代码如下:
#![allow(unused)] fn main() { async fn send_raft_message( &self, request: Request<SendRaftMessageRequest>, ) -> Result<Response<SendRaftMessageReply>, Status> { // 将 SendRaftMessageRequest 中的 message 字段 decode 为 Message 结构体 let message = raftPreludeMessage::decode(request.into_inner().message.as_ref()) .map_err(|e| Status::invalid_argument(e.to_string()))?; // 将Message 传递给 Raft 状态机去执行 Raft 协议算法的逻辑 // 这部分在第十章会细讲,可以暂时忽略 match self .placement_center_storage .apply_raft_message(message, "send_raft_message".to_string()) .await { Ok(_) => return Ok(Response::new(SendRaftMessageReply::default())), Err(e) => { return Err(Status::cancelled( PlacementCenterError::RaftLogCommitTimeout(e.to_string()).to_string(), )); } } } }
上面这段代码的核心逻辑是:接收参数、decode Message、将得到的 Message 传递给 Raft 状态机执行,完成比如投票、选举、保存用户数据等等行为。所以说,网络层本身是不做业务逻辑处理的,当 Raft Node 拿到消息后,需要将数据传递给 Raft 状态机进行处理。
至于 Raft 状态机的实现,我们下节课会完整讲解,敬请期待!
总结
tips:每节课的代码都能在项目 https://github.com/robustmq/robustmq-geek 中找到源码,有兴趣的同学可以下载源码来看。
这两节课我们基于 RocksDB 完成了存储层的开发,基于 gRPC 完成了网络层的开发。
从存储层的视角,我们主要是对 First Index、Last Index、HardState、ConfState、Entry、Uncommit、Snapshot 这 7 个数据进行读写。
从网络层的视角,核心是在多个 RaftNode 之间传递 Raft 状态机生成的消息,从而完成比如投票、选举等核心流程。
Raft Node 是指一个唯一的 Raft 投票者,需要通过唯一的 ID 来标识,不能重复。
思考题
这里是本节课推荐的相关 issue 的任务列表,请点击查看 《Good First Issue》。 另外欢迎给我的项目 https://github.com/robustmq/robustmq 点个 Star 啊!
基于Raft协议构建分布式集群(三)
本课程为精品小课,不标配音频
你好,我是文强。这节课我们继续完善基于 Raft 协议开发的分布式集群。我们会讲解如何开发 Raft Node 上的 Raft 状态机,并最终构建包括 发起选举、 选举 Leader、 心跳发送 、 心跳过期 等等 Raft 协议定义的核心步骤的集群。
首先我们需要再回顾一下 Raft 协议的原理,以便接下来更好地理解 Raft 状态机的构建。建议你主要回顾前面推荐的 《Raft 协议的动图原理展示》。从功能上看,Raft 算法由下面六个核心流程组成:
-
节点发现
-
发起选举
-
选举 Leader
-
心跳检测
-
心跳超时
-
重新发起选举
所以我们构建状态机也是围绕这六点展开的。最开始先来记住一个定义,就是: Raft 状态机本质上是一个 Tokio 的任务(也就是 Tokio Task)。接下来我们简单聊一下 Raft 状态机的运行原理。
状态机运行原理
先来看下面这张图:
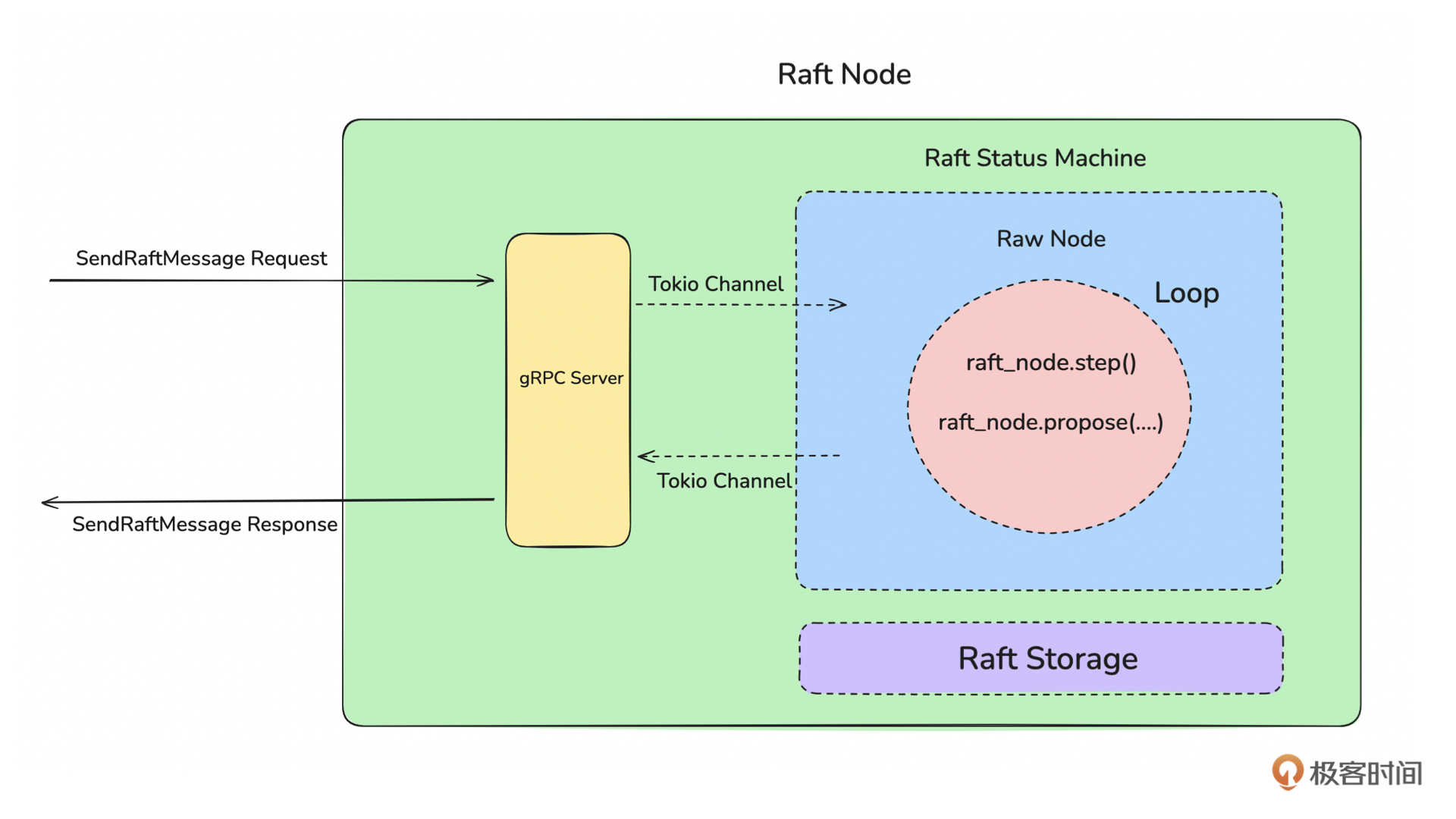
如上图所示,Raft Node 主要由 gRPC Server、Raft 状态机、Raft Storage 三部分组成。其中最关键的是 Raft 状态机,它驱动了 Raft Node 向前运行。从启动流程的角度看,服务启动后,会先启动 gRPC Server、初始化 RawNode,然后启动 Raft 状态机。Raft 状态机本质上是一个 Loop 线程,它会不间断地运行去驱动 RawNode 向前运行。
那什么叫做 RawNode 向前运行呢?
是指每个 RawNode 初始化后,需要根据自己的角色不断地做一些事情。比如,如果是 Leader 节点,那么就需要检测是否有新的用户数据写入,并将用户数据分发给多个 Follower,同时需要定时给 Follower 节点发送心跳信息。如果是 Follower 节点,则需要定时查看是否有心跳,如果有心跳则继续等待下一次心跳,如果心跳过期则发起新的选举。而这些操作都是由 Raft 状态机来驱动的。
不管是 Leader 还是 Follower 的信息,当 Raft 状态机生成消息后,都会通过 Tokio Channel 将消息从网络层发送给其他节点。从而完成发起选举、投票选举 Leader、心跳发送等行为。所以,从集群的角度来看,整体架构图如下:
基于上面集群的架构图,我们来讲一下上面的 Raft 算法中的六个核心流程。
- 节点发现:如下代码所示,Raft Node 之间相互发现是在启动时通过 ConfState 中的voters变量来配置的。
#![allow(unused)] fn main() { // 初始化 Raft 的投票者列表 let mut cs = storage.read_lock().conf_state(); cs.voters = cluster.node_ids(); }
-
选举(发起选举和选举 Leader):RaftNode 启动时,Raft 状态机会根据配置的voters节点信息,从其他节点获取当前是否有 Leader,有的话就将自己转变为 Follower 角色,然后根据 Follower 的角色视角去驱动 Raft 状态机的运行。如果当前集群没有 Leader,则 Raft 状态机会发起选举,也就是生成 MsgType 为 MsgRequestVote 的消息,将消息通过 Tokio Channel 发送给网络层,再通过网络层发送给其他 Raft Node。
-
心跳检测:Raft Leader 运行时,Raft 状态机会不间断生成 MsgType 为 MsgHeartbeat 的消息,并将消息发送给 Follower。当 Follower 收到 MsgType 为 MsgHeartbeat 的消息时,会给 Leader 返回 MsgType 为 MsgHeartbeatResponse 的消息。
-
心跳过期 & 重新发起选举:当 Follower 状态机向前驱动时,如果检测到心跳过期,那么则生成 MsgType 为MsgRequestVote的消息,发起一次新的选举。
接下来看一段单机 RaftNode 运行,并将自己选举为 Leader 的日志信息,这段日志展示了RaftNode 从运行到选举为 Leader 的过程(日志就不展开讲了,每一行还是比较容易看懂的)。
讲到这里你就会发现: Raft 集群的运行是依靠 Raft 状态机不断地向前驱动去生成不同类型的消息,从而完成不同的操作。
那接下来我们就来实现 Raft 状态机。开发 Raft 状态机的第一步是初始化 raft-rs 中的 RawNode 对象。
初始化 RawNode
在前面我们频繁提到 Raft Node 和 Raft 状态机这两个概念,现在又出现了 RawNode,我们先来看一下这三者的区别。
-
Raft Node:指 Raft 中的投票者节点,一般一个物理节点(或服务进程)就是一个 Raft Node。
-
RawNode:是 raft-rs 库的一个结构体,用于初始化一个投票者。
-
Raft 状态机:指服务进程中驱动 RawNode 状态运行的线程。一般情况下,一个 RawNode 对应一个 Raft 状态机,也就是一个线程。用于避免多个 RawNode 运行在同一个线程中相互影响。
了解完这几个概念,接下来就初始化 RawNode 对象。从实现上主要包含两步:
-
构建配置
-
创建 RawNode 对象
先来看构建配置,代码如下:
#![allow(unused)] fn main() { fn build_config(&self, apply_index: u64) -> Config { let conf = placement_center_conf(); Config { id: conf.node_id, election_tick: 10, heartbeat_tick: 3, max_size_per_msg: 1024 * 1024 * 1024, max_inflight_msgs: 256, applied: apply_index, ..Default::default() } } }
构建配置代码实现很简单,你需要重点关注 id 和 applied 这两个配置项。
-
id:指 RawNode 的唯一标识,用来区分不同的投票者。多个 RawNode 之间的 id 不能重复。
-
applied:表示当前 Raft Node 上持久化存储的最新的 commit index。因为进程会重启,所以当进程重启时,就需要从本地持久化的存储中,恢复当前 RawNode 的 commit index。(在这一步,你就看到前面持久化存储层的作用了)
接下来看一下如何创建 RawNode。
#![allow(unused)] fn main() { pub async fn new_node(&self) -> RawNode<RaftMachineStorage> { let cluster = self.placement_cluster.read().unwrap(); // 创建RawNode 的存储层,也就是 Raw 的Stroage Trait 的实现。 // 这里用了我们实现上一章实现的存储层 RaftMachineStorage let storage = RaftMachineStorage::new(self.raft_storage.clone()); // 构建 RawNode 的配置 let hs = storage.read_lock().hard_state(); let conf = self.build_config(hs.commit); // 初始化 Raft 的投票者列表 let mut cs = storage.read_lock().conf_state(); cs.voters = cluster.node_ids(); let _ = storage.write_lock().save_conf_state(cs); // raft-rs 库有自己的日志实现,也就是会打印 raft 运行日志到一个独立的文件 let logger = self.build_slog(); // 初始化一个 RawNode 实例 let node = RawNode::new(&conf, storage, &logger).unwrap(); return node; } }
上面这段代码的核心逻辑是,初始化存储层实现、初始化配置、初始化投票者列表、初始化日志、创建RawNode 实例。整体流程比较简单直观。需要注意的是,上面的代码中有这样一行:
#![allow(unused)] fn main() { cs.voters = cluster.node_ids() }
如果你对 Raft 协议理解得较多的话,就知道 Raft Node 之间需要知道对方的存在,才能进行投票选举,并将得票超过半数的 Raft Node 选举为 Leader。这行代码就是初始化配置当前总共有几个 Raft Node,让Node之间能够相互发现,从而选举出 Leader。
node_ids 方法的代码如下所示,返回的是所有投票者的节点 id 列表。
#![allow(unused)] fn main() { pub fn node_ids(&self) -> Vec<u64> { let mut voters = Vec::new(); for (id, _) in self.peers.iter() { voters.push(*id); } return voters; } }
当然如果只有一个 RawNode,那么它会被自动选举为 Leader,运行日志如下:
初始化后 RawNode后,接下来我们来看状态机的具体逻辑实现。
从实现来看,状态机的代码由 驱动代码 和 逻辑代码 两部分组成。由于篇幅原因,我们这里只讲代码的主要实现逻辑,完整代码请看 Demo 示例中的 《machine.rs》。接下来先来看状态机驱动代码。
状态机驱动代码
状态机驱动代码是指驱动 Raft 状态机向前运行的主流程代码。先来看代码:
#![allow(unused)] fn main() { pub async fn run(&mut self) { // 初始化 RawNode 实例 let mut raft_node: RawNode<RaftRocksDBStorage> = self.new_node().await; // 定义每隔 100ms 向前驱动一次状态机 let heartbeat = Duration::from_millis(100); let mut now = Instant::now(); // 使用 loop 循环一直向后驱动 Raft 状态机 loop { // 接收进程停止的信号,优雅退出进程 match self.stop_recv.try_recv() { Ok(val) => { if val { info!("{}", "Raft Node Process services stop."); break; } } Err(_) => {} } // 通过 timeout 配合 receiver 实现每 100ms 向前驱动状态机 match timeout(heartbeat, self.receiver.recv()).await { // 接收其它Raft Node 上的 Raft 状态机生成的Message,进行处理 // 比如发起投票、心跳、心跳返回等等 Ok(Some(RaftMessage::Raft { message, chan })) => { match raft_node.step(message) { Ok(_) => match chan.send(RaftResponseMesage::Success) { Ok(_) => {} Err(_) => { error!("{}","commit entry Fails to return data to chan. chan may have been closed"); } }, Err(e) => { error!("{}", e); } } } // 接收写入到 Raft 状态机的用户消息,并进行处理 Ok(Some(RaftMessage::Propose { data, chan })) => { let seq = self .seqnum .fetch_add(1, std::sync::atomic::Ordering::Relaxed); match raft_node.propose(serialize(&seq).unwrap(), data) { Ok(_) => { self.resp_channel.insert(seq, chan); } Err(e) => { error!("{}", e); } } } Ok(None) => continue, Err(_) => {} } let elapsed = now.elapsed(); // 每隔一段时间(称为一个 tick),调用 RawNode::tick 方法使 Raft 的逻辑时钟前进一步。 if elapsed >= heartbeat { raft_node.tick(); now = Instant::now(); } // 在每个驱动周期(收到业务消息或者每 100ms),尝试去处理 Raft Message self.on_ready(&mut raft_node).await; } } }
上面这段代码主要逻辑已经写在注释里面了。我们总结一下核心流程。
-
通过 loop + timeout + self.receiver.recv 来驱动 Raft 状态机向前运行。即如果收到需要 Raft 状态机处理的消息,就向前驱动一步,处理这部分消息。如果没有需要 Raft 状态机处理的消息,则每 100ms 向前驱动一步。
-
Raft 状态机会接收 其他 Raft Node 运行状态消息 和 用户消息 进行处理,这两个消息是网络层 gRPC Server 通过 Tokio Channel 传递过来的。当状态机接收到消息数据后,即刻进行处理。
-
通过 self.stop_recv.try_recv() 来优雅停止状态机。
-
每 100ms 将 Raft 状态机的逻辑时钟向前驱动一步。
-
Raft 每驱动一次,则会调用 self.on_ready 尝试处理本次驱动是否有需要处理的消息。
可以看到,上面的 run 方法是一个 loop 的循环,为了不阻塞主线程,需要将它放在一个独立的子任务中运行。从代码实现上来看,如下所示直接通过 tokio::spawn 启动一个 tokio task 运行即可。
#![allow(unused)] fn main() { let mut raft: RaftMachine = RaftMachine::new( self.placement_cache.clone(), data_route, peer_message_send, raft_message_recv, stop_recv, self.raft_machine_storage.clone(), ); tokio::spawn(async move { raft.run().await; }); }
讲到这里,其实 Raft 状态机主体框架已经开发完成了。我们根据前面状态机运行原理的两张图来总结一下整体的运行流程: 进程启动,启动 gRPC Server,启动状态机,状态机会自己运行,找到 Leader 或发起 Leaer 选举。根据自身的角色生成不同的消息,通过Tokio Channel 发送给网络层,并通过网络层发送给其他节点,从而和其他 Raft 节点互动,进而完成集群的组建。
你应该会注意到,run 方法中我们通过一个 on_ready 方法来处理每一批次的 Raft 消息,也就是说在 on_ready 方法里面会完成每一批次 Raft 消息的逻辑处理。所以可以将它称为状态机逻辑代码。接下来来看一下它的实现。
状态机逻辑代码
直接来看代码:
#![allow(unused)] fn main() { async fn on_ready(&mut self, raft_node: &mut RawNode<RaftRocksDBStorage>) { // 检查 raft 状态机是否已经准备好 // 是的话,向下运行 // 否的话,表示这批次没有需要处理的消息 if !raft_node.has_ready() { return; } // 获取到这一批次需要处理的数据 let mut ready = raft_node.ready(); // 判断消息是否为空 // 如果不为空,表示 有Raft Message需要发给其他Raft Node, // 则需要把 Raft 消息通过我们构建的网络层发送给其他的 Raft Node if !ready.messages().is_empty() { // mark 1 self.send_message(ready.take_messages()).await; } // 判断这次向前驱动,是否有快照数据需要恢复 // 如果有快照数据,则需要恢复快照数据,即将快照数据持久化存储到存储层 if *ready.snapshot() != Snapshot::default() { // mark 2 let s = ready.snapshot().clone(); info!( "save snapshot,term:{},index:{}", s.get_metadata().get_term(), s.get_metadata().get_index() ); raft_node.mut_store().apply_snapshot(s).unwrap(); } // 持久化存储 Raft 日志 // 即判断是否有 Entry 需要保存 // 如果有 Entry 需要保存,则需要将 Entry 持久化保存 if !ready.entries().is_empty() { // // mark 3 let entries = ready.entries(); raft_node.mut_store().append(entries).unwrap(); } // 处理已经能够被 Apply 的消息 // 因为 Raft 存储是两阶段的,Leader 接收到数据后,需要被多个节点都处理成功后才能算处理成功 // 所以 这一步是 apply 已经被多个节点处理成功的数据 // mark 4 self.handle_committed_entries(raft_node, ready.take_committed_entries()); // 如果有 HardState 数据更新,则更新本地持久化存储的 HardState 数据 if let Some(hs) = ready.hs() { // mark 5 debug!("save hardState!!!,len:{:?}", hs); raft_node.mut_store().set_hard_state(hs.clone()).unwrap(); } // 判断是否有persisted messages 消息 // 有的话就发送给其他 Raft 节点 if !ready.persisted_messages().is_empty() { // mark 6 self.send_message(ready.take_persisted_messages()).await; } // 在确保一个 Ready 中的所有进度被正确处理完成之后,调用 RawNode::advance 接口。 let mut light_rd = raft_node.advance(ready); // 更新 HardState 中的 commit inde 信息 if let Some(commit) = light_rd.commit_index() { // mark 7 raft_node.mut_store().set_hard_state_comit(commit).unwrap(); } // mark 8 同上 self.send_message(light_rd.take_messages()).await; // mark 9 同上 self.handle_committed_entries(raft_node, light_rd.take_committed_entries()); raft_node.advance_apply(); } }
上面代码的主要逻辑已经加在注释中了,就不再重复。我们还是来总结下核心逻辑。
-
on_ready 代码把我们之前实现的网络层和存储层的逻辑都集成进来了。也就是代码中标记了 mark 1~9 位置的代码。比如当状态机生成需要发送给其他节点的消息,就调用send_message 方法将消息发给其他节点。如果需要持久化存储消息,就调用RaftMachineStorage 中对应的方法完成存储。
-
你可以认为 on_ready 代码逻辑步骤是固定的,假设你要实现自己的 Raft 状态机,那么直接把这段代码复制下来,把代码中标记了 mark 1~9 位置的代码变为自己的实现即可。
-
总结一下标记了 mark 的代码块的作用:
-
mark 1/6/8:如果有需要发送给其他 Raft Node 的消息,则通过 send_message 方法,调用 gRPC 模块,将消息发送给其他节点。
-
mark 2:恢复快照,将快照中的数据持久化到本地的 RocksDB 中。
-
mark 3:持久化存储 Raft 日志,将数据持久化存储到 RocksDB 中。
-
mark 4/9:处理业务数据,这一点我们在下节课会细讲。
-
mark 5:持久化保存 HardState 数据到 RocksDB 中。
-
mark 7:持久化保存最新的 commit index 到 RocksDB 中。
-
当完成上面的工作后,Raft 状态机也全部完成了。 同时基于 Raft 协议的分布式集群也构建完成了。讲到这里,虽然我们已经完成了每个部分的开发,但是你是不是对整个集群的运行流程还是点模糊,没有一个整体的概念?
是的,这很正常,所以接下来我们从宏观的角度来总结一下我们基于 Raft 协议构建的集群的运行逻辑和代码关系。
集群运行宏观总结
回顾一下,我们总共完成了三个事情:
-
基于 RocksDB 的 Raft Log 存储层的开发。
-
基于 gRPC 的 Raft Node 网络层的开发。
-
基于 Tokio 的 Raft 状态机的开发。
这三个工作都是指单个Raft Node 维度的实现。而从集群的角度看,就是多个Raft Node 就可以组成集群。因此只要我们启动多个 Raft Node,它就会自动组建成集群。那它是怎么组建集群的呢? 来看下图:
组建集群的代码运行逻辑如下:
-
单个 Raft Node 启动,会尝试从本地 RocksDB 的数据目录恢复数据,如果 RocksDB 目录不存在,则会创建一个新的数据目录,否则就恢复Raft Node 的状态数据。主要是通过 Storate Trait 的 initial_state 方法读取 HardState 和 ConfState 数据。
-
同时 Raft Node 会启动网络层 gRPC Server 和 Raft 状态机。
-
Raft 状态机启动后,会判断是否有 Leader,有的话就获取 Leader 信息,没有的话重新发起选举。这些动作是由 raft-rs 库的 RawNode 实现的。
-
不管是获取 Leader 还是发起选举,都是由 RawNode 发起的。由 RawNode 生成消息,然后通过网络层跟其他 Raft Node 交互。
-
选举出 Leader 后,Leader 会向 Follower 发送心跳信息,如果 Follower 没及时收到心跳,则会重新发起选举。
每个节点启动都会执行上面这些逻辑。比如单节点启动,就会将自己选为 Leader,如果有新节点启动,则会获取当前集群的 Leader 或者发起选举。以此类推,多个 Raft Node 就会组建成集群了。
在集群构建完成后,你可能有个疑问: 如果你写一条数据,这个数据最终是如何完成分布式存储的?这个问题我们留到下节课,我们会基于当前构建的 Raft 集群来完成数据的分布式多副本可靠存储。
总结
tips:每节课的代码都能在项目 https://github.com/robustmq/robustmq-geek 中找到源码,有兴趣的同学可以下载源码来看。
到了这节课,基于 Raft 协议构建分布式集群就完成了。可以看到,基于 raft-rs 库来构建集群,整个流程还是很繁杂的,要自己实现很多细节。
在这里我想说明的是,不论我们基于哪个库来实现集群,甚至自己实现一个一致性协议来构建集群,它的底层原理都是一样的,是通用的。因此在我看来,从学习的角度,选择哪个库来实现的区别不大,重要的是你能深刻理解一致性协议的细节。
客观来讲,至今为止我们也只是实现了最简单的集群。里面还有很多细节需要优化,比如异步快照构建、高性能的快照同步和恢复、Raft 日志存 RocksDB 写放大问题、Raft 节点之间高性能的消息同步等等。所以欢迎你参与我的项目 https://github.com/robustmq/robustmq,来了解更多的细节。
在实际的实现中,也会建议你可以考虑基于 openraft 库来实现自己的集群,因为 openraft 库是一个完整的实现,对于使用者来说开发理解成本会更低一些。选型的考虑过程在 第 7 课 讲完了,你可以根据自己的实际需要来选择合适的类库。
不过基于 raft-rs 库实现构建集群有一个好处是, 会让你对 Raft 的原理及实现有更深的理解。当你把这三节课的内容理解透,想必你对 Raft 协议的理解会深入很多,后续不管使用哪个 Raft 库,应该都更得心应手。
思考题
这里是本节课推荐的相关 issue 的任务列表,请点击查看 《Good First Issue》。另外欢迎给我的项目 https://github.com/robustmq/robustmq 点个 Star 啊!
分布式:实现集群化、多副本KV存储引擎
本课程为精品小课,不标配音频
你好,我是文强。
这节课我们将在前三节课基于 Raft 协议构建的集群的基础上,将 第 6 课 实现的单机 KV 存储扩展为集群化、多副本的 KV 存储引擎。
从技术上看,分布式系统都是基于多副本来实现数据的高可靠存储。因此接下来,我们先来看一下副本和我们前面构建的 Raft 集群的关系。
集群和副本
先来看下图:
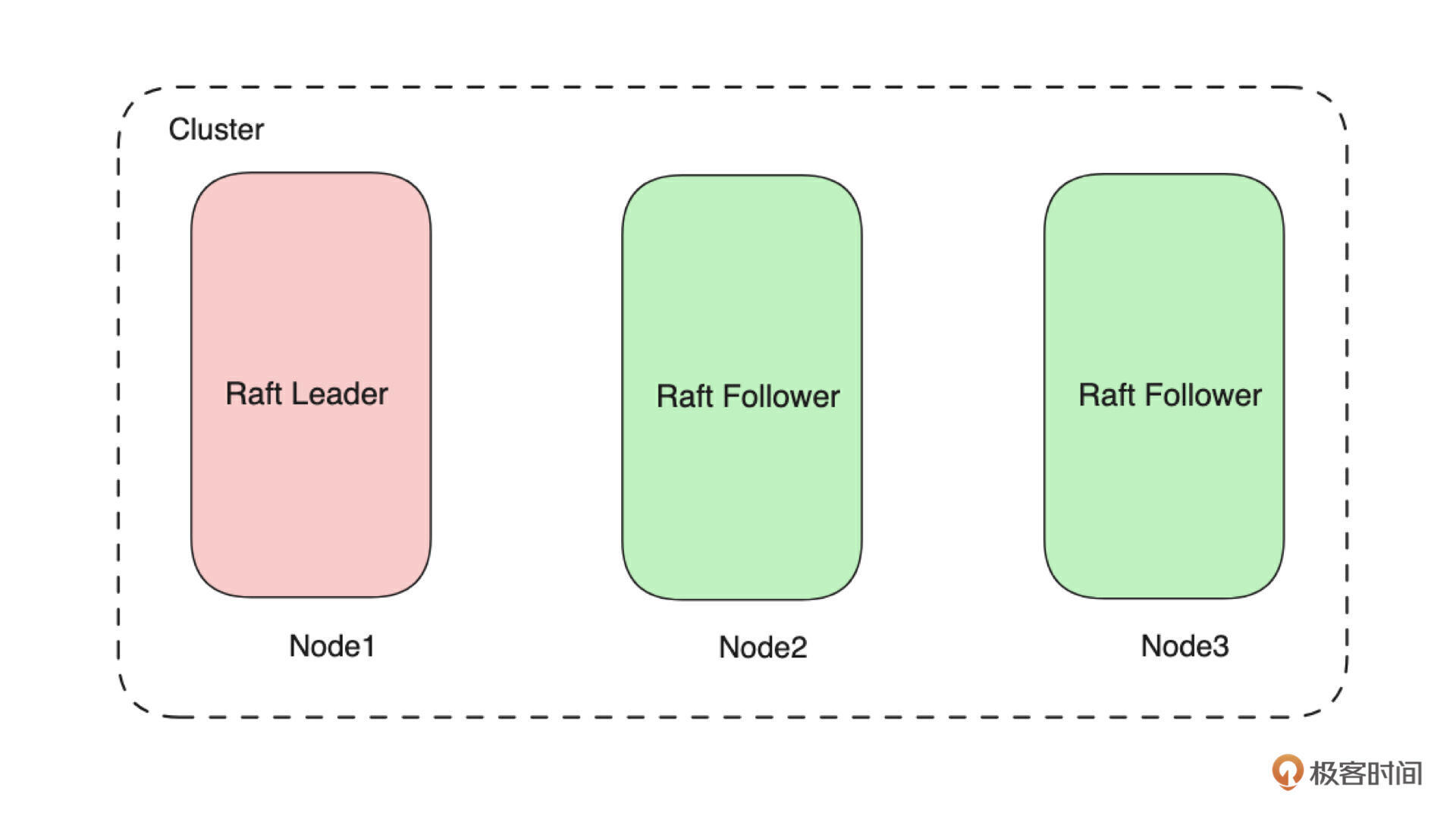
可以看到,这是一个由 3 个节点组成的、基于 Raft 协议构建的集群,它包含 1 个 Leader 节点和 2 个 Follower 节点。因此写入数据时,数据会先写入 Leader 节点,Leader 节点再将数据分发到两个 Follower 节点。
从技术上看这个集群只有一个 Raft 状态机,这个状态机由 3 个 Voter(Node)组成。所以整个集群只能有一个Leader,也就是在上图中 一个节点就是一个副本。如下图所示,如果需要需要新增一个副本,就需要再增加一个节点。
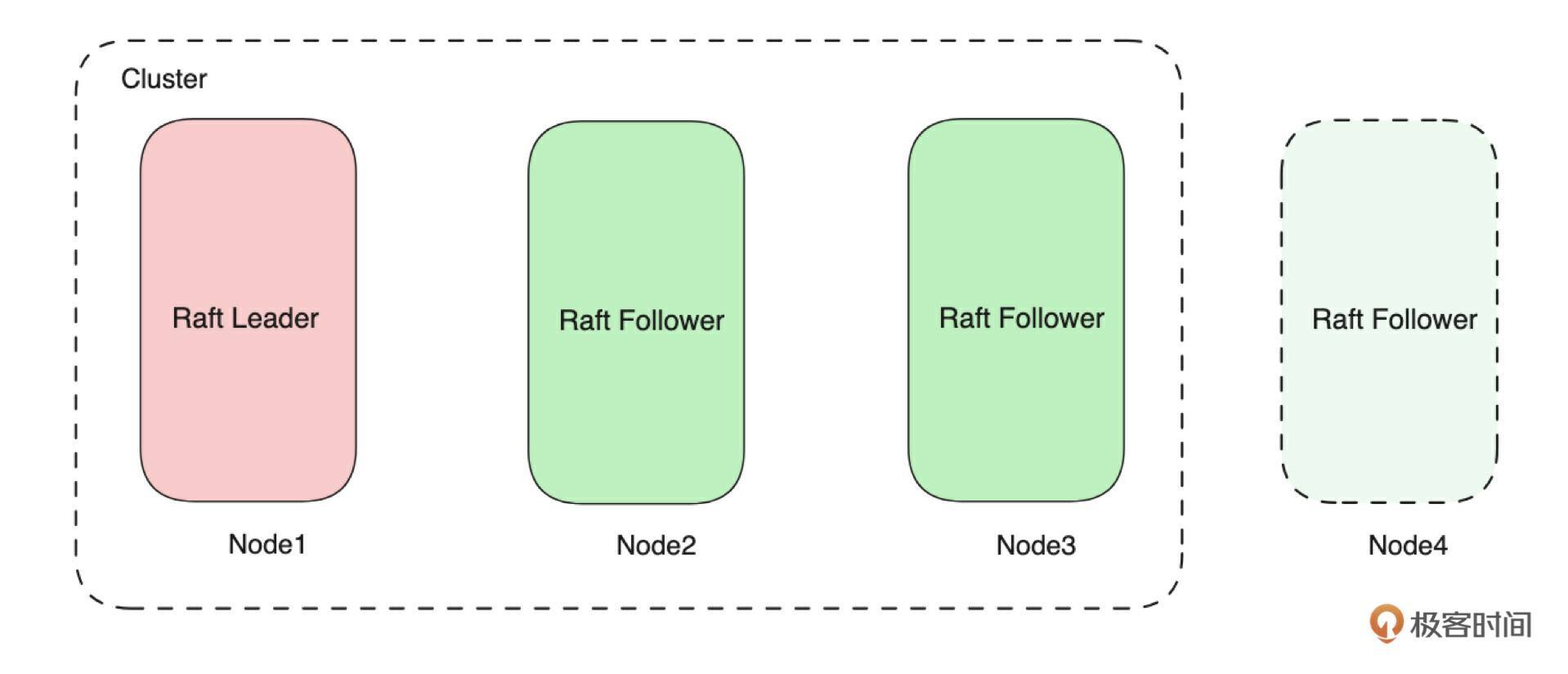
那么就会有一个问题: 一个节点上能运行多个副本吗? 答案肯定是可以的。来看下图:
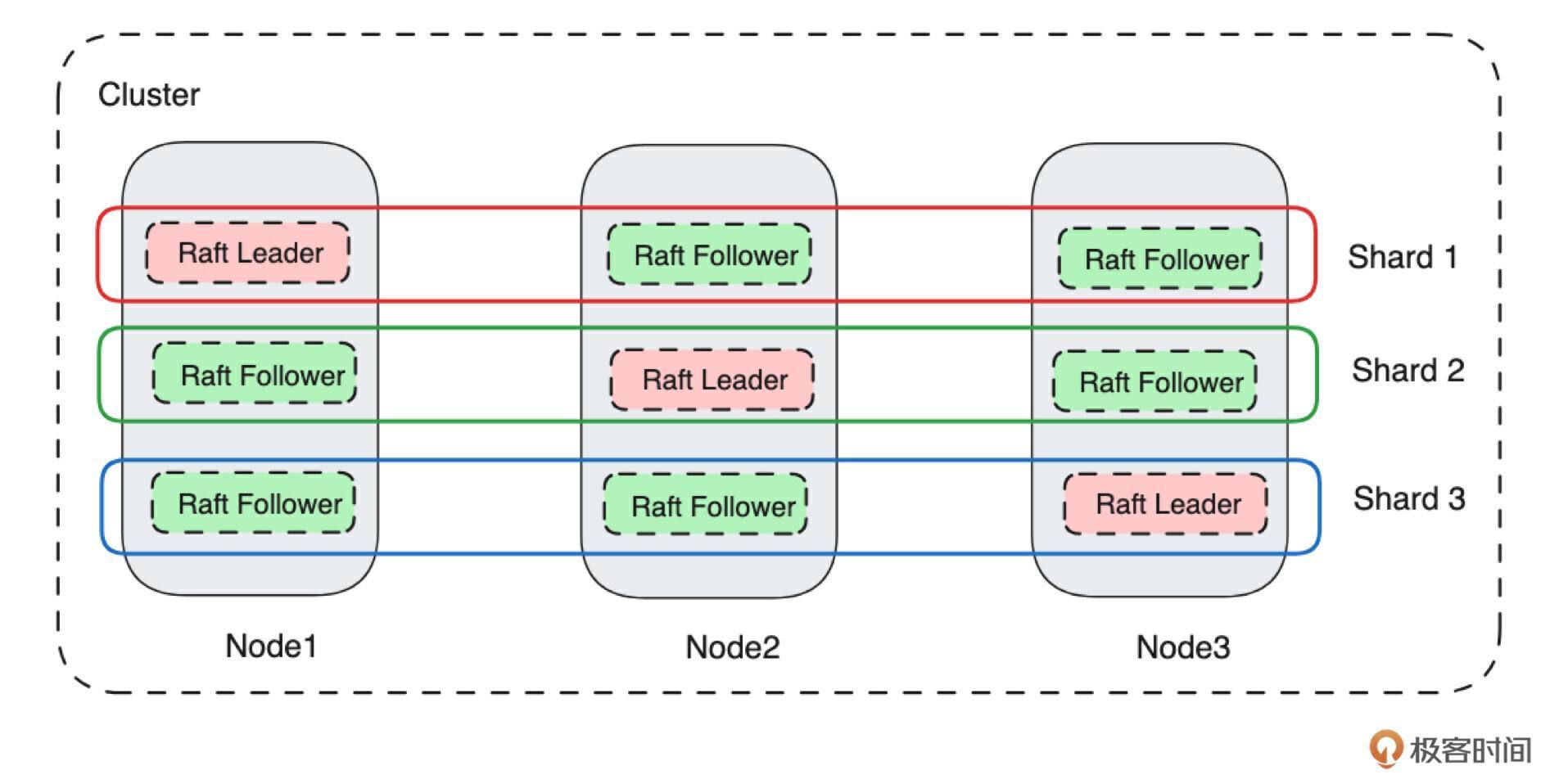
为了在一个节点上运行多个副本,我们首先抽象了 Shard(分片)的概念。从技术上看,一个 Shard 对应一个 Raft 状态机,也就是说每个 Shard 都有自己的 Leader 和 Follower。上图中有 3 个 Shard,每个 Shard 有 1 个 Leader、2个 Follower。因此总共有 3 个Leader及其对应的 6 个 Follower。同一个 Shard 对应的 Leader 和 Follower 都分布在不同的节点上。这是 因为副本是为了容灾而存在的,因此同一个 Shard 的不同副本在同一个物理节点上是没有意义的。
所以说,如果要在一个节点上运行多个副本,那么就需要集群中有多组副本,也就是说一个集群需要运行多个状态机,也就是我们前面提到的状态机组(比如Raft Group)。
tips: 在本次课程中,我们只会实现一个集群只有一个状态机的模式,如果你需要了解状态机组的实现,我们可以在交流群中讨论。
了解了副本和集群的关系后,接下来我们来看一下,如何将单机的 KV 存储扩展为集群化、多副本的 KV 存储,在开发上需要做哪些事情。
从技术上看,主要有下面三部分的工作:
-
网络层:即客户端通过该网络层往集群读写 KV 数据。
-
一致性协议:集群会通过一致性协议(Raft)在 Leader、Follower 节点之间同步数据。从实现上看,这部分是指网络层、状态机、存储层三部分的交互。
-
存储层:单机维度基于 RocksDB 实现数据的持久化存储。
在第 6 课我们其实已经完成了基于 RocksDB 的存储层的开发。接下来我们来实现 网络层 和 一致性协议 这两个部分的开发。
先来看网络层的实现。
网络层的实现
我们依旧基于 gRPC 来构建我们的网络层,先来看 proto 的定义。
#![allow(unused)] fn main() { syntax = "proto3"; package kv; service KvService { rpc set(SetRequest) returns(CommonReply){} rpc delete(DeleteRequest) returns(CommonReply){} rpc get(GetRequest) returns(GetReply){} rpc exists(ExistsRequest) returns(ExistsReply){} } message SetRequest{ string key = 1; string value = 2; } message GetRequest{ string key = 1; } message GetReply{ string value = 1; } message DeleteRequest{ string key = 1; } message ExistsRequest{ string key = 1; } message ExistsReply{ bool flag = 1; } message CommonReply{ } }
在上面的 proto 中,可以看到,我们定义了 set/get/delete/exists 四个方法及其对应的请求和返回参数,分别对应存储层 KvStorage 里面的 set/get/delete/exists 四个操作。
接下来以 Set 方法举例,看一下 gRPC Service 部分代码的实现。
#![allow(unused)] fn main() { async fn set(&self, request: Request<SetRequest>) -> Result<Response<CommonReply>, Status> { let req = request.into_inner(); // 参数校验 if req.key.is_empty() || req.value.is_empty() { return Err(Status::cancelled( CommonError::ParameterCannotBeNull("key or value".to_string()).to_string(), )); } // 构建StorageData类型的数据 let data = StorageData::new(StorageDataType::KvSet, SetRequest::encode_to_vec(&req)); // 将数据交给 Raft 状态机处理 match self .placement_center_storage .apply_propose_message(data, "set".to_string()) .await { Ok(_) => return Ok(Response::new(CommonReply::default())), Err(e) => { return Err(Status::cancelled(e.to_string())); } } } }
这段代码很简单,获取请求参数,判断参数是否为空,构建StorageData类型的数据。然后通过apply_propose_message 方法将 KV 数据传给 Raft 状态机处理,并等待 Raft 状态机的处理结果。
如下所示,StorageData 是一个自定义的数据结构,用来在网络层和状态机之间交互。data_type 表示这是一个什么类型的操作,比如 Kv 的 Set 或 Delete 操作,value 表示具体的数据内容。
#![allow(unused)] fn main() { pub struct StorageData { pub data_type: StorageDataType, pub value: Vec<u8>, } }
在上面的代码中,你可以看到,当网络层收到请求后,是通过调用 apply_propose_message 方法来将消息传递给 Raft 状态机,通过状态机内部的一致性协议来实现数据持久化存储的。
所以接下来,我们来看 apply_propose_message 方法内部的实现,也就是网络层和状态机的交互过程。
网络层和状态机的交互
先来看一张图,这张图是我们在上节课讲到的网络层通过 Tokio Channel 和状态机进行交互的示意图。
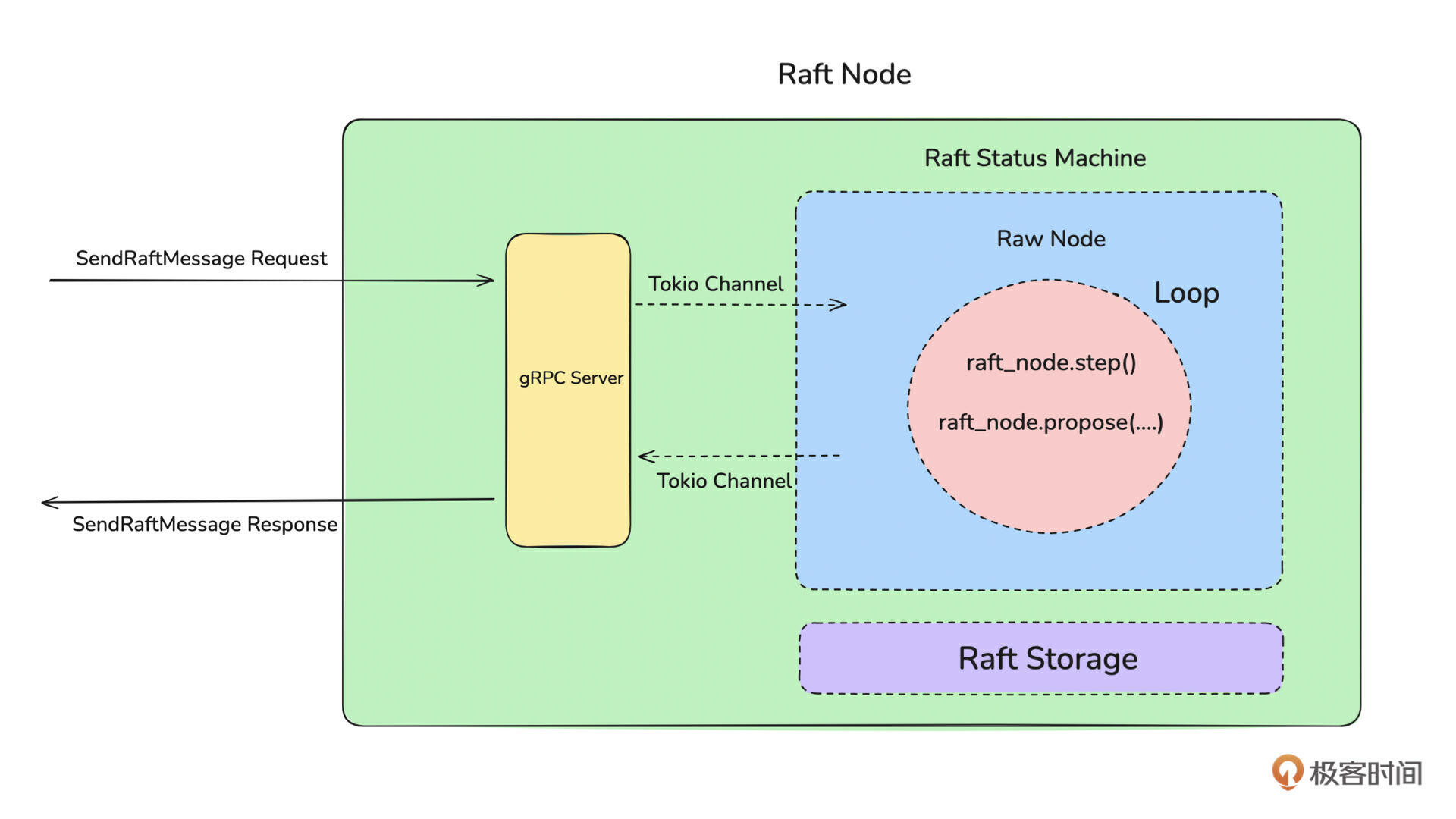
整个交互过程可以分为 请求 和 返回 两步,先来看请求。
请求 是指网络层将 KV 数据传递给 Raft 状态机处理的过程。从技术上看,它是通过 tokio 的 mpsc 类型的 channel 来完成的。
具体流程是:首先初始化一个 mpsc 类型的 channel。
#![allow(unused)] fn main() { let (raft_message_send, raft_message_recv) = mpsc::channel::<RaftMessage>(1000); }
网络层使用 send(tokio::sync::mpsc::Sender)方法将数据传递给 channel。RawNode 使用 recv(tokio::sync::mpsc::Receiver)接收从网络层传递过来的数据(比如用户写入的数据),并驱动 Raft 运行。
再来看返回。
返回 是指 Raft 状态机处理数据成功或失败后,通知网络层处理结果的过程。从技术上看,这个过程是通过一个 oneshot 类型的 channel 来实现的。如下所示:
#![allow(unused)] fn main() { let (sx, rx) = oneshot::channel::<RaftResponseMesage>(); }
网络层会调用 oneshot 的 recv 方法接收状态机的运行结果,状态机会将处理结果写入到 sender 中,从而完成交互。
接下来来看整个过程的核心代码段的实现,完整代码请参考 《apply.rs》。
#![allow(unused)] fn main() { pub async fn apply_propose_message( &self, data: StorageData, action: String, ) -> Result<(), CommonError> { // 定义oneshot channel,用于接收 raft 状态机的返回 let (sx, rx) = oneshot::channel::<RaftResponseMesage>(); // 将数据传给 Raft 状态机处理,比等待 raft 状态机的处理结果 return Ok(self .apply_raft_status_machine_message( RaftMessage::Propose { data: serialize(&data).unwrap(), chan: sx, }, action, rx, ) .await?); } async fn apply_raft_status_machine_message( &self, message: RaftMessage, action: String, rx: Receiver<RaftResponseMesage>, ) -> Result<(), RobustMQError> { // 将消息发送给状态机,状态机向前驱动时会处理该消息 let _ = self.raft_status_machine_sender.send(message).await; // 等待状态机对该消息的处理结果,比如成功或者失败 if !self.wait_recv_chan_resp(rx).await { return Err(RobustMQError::RaftLogCommitTimeout(action)); } return Ok(()); } async fn wait_recv_chan_resp(&self, rx: Receiver<RaftResponseMesage>) -> bool { // 定义状态机处理消息的最长时间,如果超过 30s 消息没处理成功,就表示写入失败 let res = timeout(Duration::from_secs(30), async { match rx.await { Ok(val) => { return val; } Err(_) => { return RaftResponseMesage::Fail; } } }); // 等待状态机的处理结果 match res.await { Ok(_) => return true, Err(_) => { return false; } } } }
可以看到,上面代码有apply_propose_message、apply_raft_status_machine_message、wait_recv_chan_resp 三个方法,它们的主要功能是:
-
apply_propose_message:在网络层存储数据时调用,用于保存用户从客户端写入的数据。
-
apply_raft_status_machine_message:给 apply_propose_message 方法调用,主要完成将数据发送给 Raft 状态机处理,并等待 Raft 状态机的处理结果,这两个事情。
-
wait_recv_chan_resp:给 apply_raft_status_machine_message 调用,通过 timeout 和 oneshot 等待 Raft 状态机的处理结果。
那状态机是如何处理数据的呢?这个答案你去回顾 第 9 课 就知道了,这里不再重复讲了。
不知道你注意到没有,我们在第 9 课中是没有讲状态机是如何处理业务数据的。比如我们写了一个 KV 数据到集群,此时状态机是如何持久化存储这条KV数据的呢?
tips:这里说的 KV 数据是指客户端写入的数据,不是 Raft 自身运行产生的 Raft Log。这两类数据的区别你可以去回顾一下第7、8、9 这三节课。
接下来,我们就来看一下状态机是如何存储这些业务数据的。
状态机和存储层的交互
直接来看代码,完整代码在 《machine.rs》 中,状态机和存储层的交互我们只要关注 handle_committed_entries 方法就可以了,来看下面这段代码:
#![allow(unused)] fn main() { fn handle_committed_entries( &mut self, raft_node: &mut RawNode<RaftRocksDBStorage>, entrys: Vec<Entry>, ) { let data_route = self.data_route.write().unwrap(); // 循环处理 Entry for entry in entrys { // 如果 Entry 的 data 为空,就不需要处理 if !entry.data.is_empty() { info!("ready entrys entry type:{:?}", entry.get_entry_type()); // 根据不同raft-rs 库定义的不同的消息类型,进行不同的逻辑处理 // 在 raft-rs 库中,主要分为分为EntryNormal和EntryConfChange两种类型的消息。 // EntryNormal 表示客户业务消息 // EntryConfChange 表示 Raft 集群内的消息,比如节点的上线下线 match entry.get_entry_type() { EntryType::EntryNormal => { // 用户的消息数据直接通过 DataRoute 方法进行分发处理 match data_route.route(entry.get_data().to_vec()) { Ok(_) => {} Err(err) => { error!("{}", err); } } } EntryType::EntryConfChange => { let change = ConfChange::decode(entry.get_data()) .map_err(|e| tonic::Status::invalid_argument(e.to_string())) .unwrap(); let id = change.get_node_id(); let change_type = change.get_change_type(); match change_type { // 处理增加节点的消息 ConfChangeType::AddNode => { match deserialize::<BrokerNode>(change.get_context()) { Ok(node) => { let mut cls = self.placement_cluster.write().unwrap(); cls.add_peer(id, node); } Err(e) => { error!("Failed to parse Node data from context with error message {:?}", e); } } } // 处理节点移除的消息 ConfChangeType::RemoveNode => { let mut cls = self.placement_cluster.write().unwrap(); cls.remove_peer(id); } _ => unimplemented!(), } if let Ok(cs) = raft_node.apply_conf_change(&change) { let _ = raft_node.mut_store().set_conf_state(cs); } } EntryType::EntryConfChangeV2 => {} } } // 消息处理成功后提交更新最新的 commit index let idx: u64 = entry.get_index(); let _ = raft_node.mut_store().commmit_index(idx); // 通过上面提到的 oneshot channel 通知网络层消息处理成功 match deserialize(entry.get_context()) { Ok(seq) => match self.resp_channel.remove(&seq) { Some(chan) => match chan.send(RaftResponseMesage::Success) { Ok(_) => {} Err(_) => { error!("commit entry Fails to return data to chan. chan may have been closed"); } }, None => {} }, Err(_) => {} } } } }
参考代码的注释,我们可以知道,handle_committed_entries 中是状态机和存储层交互的入口方法,它的核心逻辑是: 处理状态机中已经可以被 commit 的 Entry。
从 Raft 协议可以知道,当业务数据提交给 Raft Leader 节点处理时,此时这个消息还没分发给 Follower,因此这个消息是 uncommit 的消息,也就是 uncommit 的 Entry。只有当集群中超过半数的节点处理成功后,这个消息才会变为 commit 的 Entry。
handle_committed_entries 会拿到可以被 commit 的 Entry。拿到消息后,就需要遍历处理这些消息,这些消息分为 客户端写入的消息 和 Raft 本身产生的消息 两种类型,这两种消息有不同的处理逻辑。
这里我们只讲如何处理客户端写入的消息,Raft 本身产生的消息的处理你可以直接看一下代码,比较简单,有需要的话我们交流群中讨论。
在上面代码中,可以看到客户端写入的消息是由 data_route.route(entry.get_data().to_vec()) 来处理的。DataRoute 的代码如下:
#![allow(unused)] fn main() { pub struct DataRoute { rocksdb_engine_handler: Arc<RocksDBEngine>, } impl DataRoute { pub fn new(rocksdb_engine_handler: Arc<RocksDBEngine>) -> DataRoute { return DataRoute { rocksdb_engine_handler, }; } pub fn route(&self, data: Vec<u8>) -> Result<(), RobustMQError> { let storage_data: StorageData = deserialize(data.as_ref()).unwrap(); match storage_data.data_type { StorageDataType::KvSet => { // 调用KvStorage的 set 方法持久化存储数据 let kv_storage = KvStorage::new(self.rocksdb_engine_handler.clone()); let req: SetRequest = SetRequest::decode(data.as_ref()).unwrap(); return kv_storage.set(req.key, req.value); } StorageDataType::KvDelete => { // 调用KvStorage的 delete 方法删除持久化的数据 let kv_storage = KvStorage::new(self.rocksdb_engine_handler.clone()); let req: DeleteRequest = DeleteRequest::decode(data.as_ref()).unwrap(); return kv_storage.delete(req.key); } } } } }
这段代码很简单,就是根据前面提到的结构体 StorageData 中的 data_type 来区分不同的数据类型,然后调用在第 6 课创建的 KvStorage 对象中的对应的方法来持久化存储数据。
讲到这里,我们就完成了集群化、多副本 KV 存储引擎的开发,接下来我们来总结并展示一下效果。
效果展示
先来看一张全流程示意图:
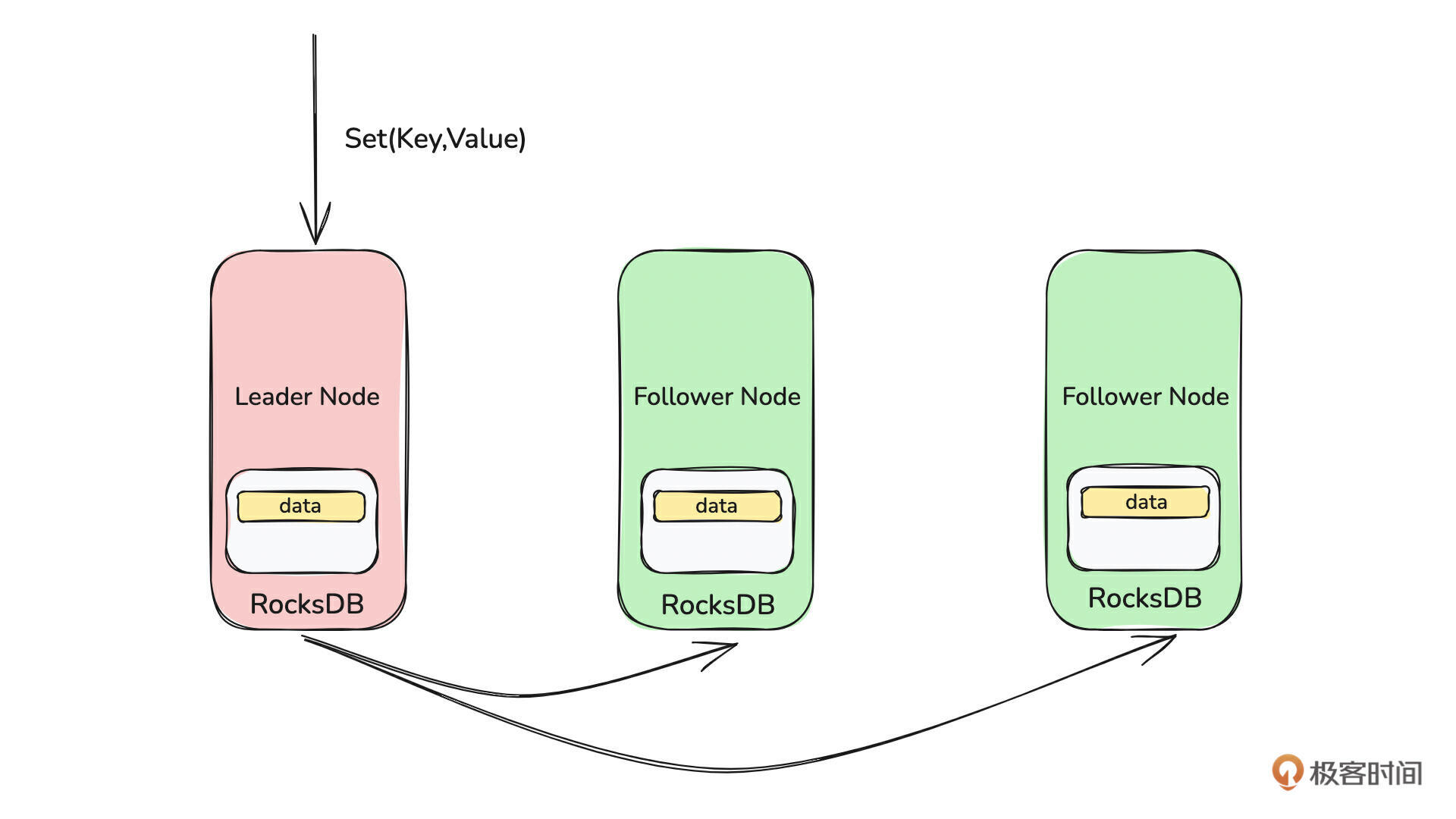
如上图所示:
-
使用 gRPC 客户端调用名为 Set 的 RPC 方法,往集群的 Leader 节点写入 KV 数据。
-
Leader 节点收到数据后,通过 apply_propose_message 方法将消息传递给 Raft 状态机进行处理。
-
Raft 状态机根据 Raft 协议的规范将消息分发到多台 Follower 节点。
-
当超过半数的 Raft Node 收到消息后,就可以 commit 这个 Entry。
-
当有可以 commit 的 Entry 后,Raft 状态机会调用 handle_committed_entries 方法,handle_committed_entries 再调用 DataRoute 的 route 方法来完成数据的持久化存储。
最后来写个Set 方法的测试用例,演示一下如何将数据存储到集群中。
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use std::net::TcpStream; use axum::http::request; use protocol::kv::{ kv_service_client::KvServiceClient, DeleteRequest, ExistsReply, ExistsRequest, GetRequest, SetRequest, }; #[tokio::test] async fn kv_test() { let mut client = KvServiceClient::connect("http://127.0.0.1:8871") .await .unwrap(); let key = "mq".to_string(); let value = "robustmq".to_string(); let request = tonic::Request::new(SetRequest { key: key.clone(), value: value.clone(), }); let _ = client.set(request).await.unwrap(); } } }
总结
tips:每节课的代码都能在项目 https://github.com/robustmq/robustmq-geek 中找到源码,有兴趣的同学可以下载源码来看。
这节课,我们把第 3~9 课的内容全部串起来了,主要把第 5 课基于 gRPC 的网络层、第 6 课基于 RocksDB 的存储层,第 7、8、9 课基于 Raft 协议的集群串联起来,完成了单机 KV 存储到分布式、集群化、多副本的KV 存储的演进。
从技术上来看,演进的核心就是我们在 7、8、9 课中基于 Raft 构建的分布式集群。从这一点也可以知道,为什么我们总会看到一个论点: 分布式的核心是一致性协议。这是因为一致性协议决定了数据在集群中的流动、同步的方式。
这节课我们没有把所有的代码都贴上来,所以建议你多去看看 《robustmq-geek》 中的代码,多揣摩一下每段代码的实现,只要你能完整理解这节课的内容,那你就完成了这个课程的学习任务了。
思考题
这里是本节课推荐的相关 issue 的任务列表,请点击查看 《Good First Issue》。另外欢迎给我的项目 https://github.com/robustmq/robustmq 点个 Star 啊!
性能提升:优化客户端访问和服务端读写性能
本课程为精品小课,不标配音频
你好,我是文强。
到了第 10 课我们其实就完成了本次课程主体部分的开发。这节课我们主要来看一下如何提升集群的性能和可用性。
集群的性能提升可以分为客户端和服务端两部分,先来看下图:
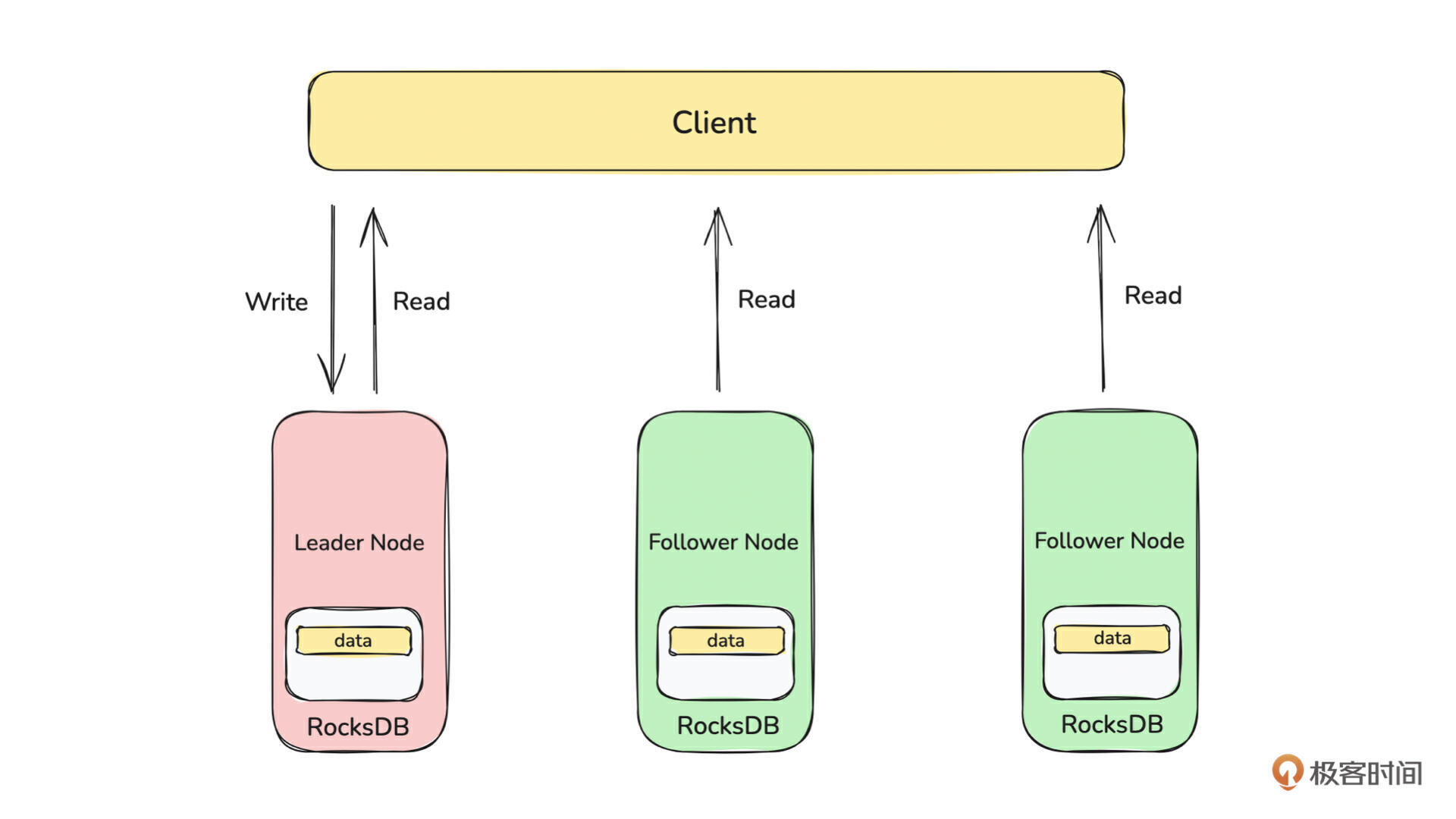
这是 Placement Center 的读写示意图。从技术上分析,重点可以关注以下三个方面来提升性能和可用性。
-
客户端基于连接池复用连接,避免连接频繁地创建、删除,从而提升性能。
-
实现自动化重试机制,以解决当出现可恢复的异常时(比如网络抖动),可以自动进行重试,从而提升请求的成功率。
-
均摊服务端多个节点之间的压力,由 Leader 节点负责写请求,所有节点负责读请求,避免 Leader 节点的单点瓶颈。
在 第 5 课 我们基于 gRPC 框架实现的网络层的基础上,我们来看一下在 Rust 中如何实现 gPRC 的连接池。
基于 mobc 库实现连接池
如上图所示,连接池的原理本质上就是通过预先创建一批连接,并将可用连接保持在一定数量范围内。当客户端发起访问时,从连接池取出可用连接,从而避免每次创建/销毁连接产生的时间和资源开销。
从代码实现角度看,连接池的实现并不复杂,就是细节比较多,比如连接被动关闭时如何自动创建连接,如何保证连接不超过最大可用连接,空闲连接回收,连接心跳保持等等。
为了节省工作量,我们直接选择Rust 的连接池库 mobc 来实现我们 gRPC 的连接池。mobc 库本身就不展开细讲了,你可以直接参考 《官方文档》。建议你先看完官方文档,再来看接下来的实现,会更容易理解。
从代码实现角度来看,基于 mobc 库来实现连接池主要包含下面两步:
-
实现 mobc 中名为 Manager 的 trait。
-
创建连接池,并将连接池变为一个全局可访问的变量。
先来看第 1 点,我们通过 KvServiceManager 来实现 Manager trait。完整代码在 《kv/mod.rs》 文件中,有兴趣可以去查看。
#![allow(unused)] fn main() { #[derive(Clone)] pub struct KvServiceManager { pub addr: String, } impl KvServiceManager { pub fn new(addr: String) -> Self { Self { addr } } } #[tonic::async_trait] impl Manager for KvServiceManager { // 使用 Rust 类型别名的语法,将类型 KvServiceClient<Channel> 重命名为Connection // 使用别名的好处是,你可以自定义connect方法的返回值,因为connect的返回值是 Self::Connection // 在这里我们将KvServiceClient<Channel>重命名为Connection,因此connect方法的返回值就是KvServiceClient<Channel> type Connection = KvServiceClient<Channel>; // 如上 type Error = CommonError; // 实现 Manager trait 中的 connect 方法 // 该方法用来返回 GRPC KvService 可用连接 async fn connect(&self) -> Result<Self::Connection, Self::Error> { // 创建一个 GRPC KvService 的连接 match KvServiceClient::connect(format!("http://{}", self.addr.clone())).await { Ok(client) => { // 返回一个可用的 GRPC KvService 连接 return Ok(client); } Err(err) => return Err(CommonError::CommmonError(format!( "{},{}", err.to_string(), self.addr.clone() ))), }; } // 实现 Manager trait 中的 check 方法 // 该方法用来检查 GRPC KvService 连接是否可用 async fn check(&self, conn: Self::Connection) -> Result<Self::Connection, Self::Error> { Ok(conn) } } }
在上面的代码中,我们创建了 KvServiceManager 来实现 mobc 库中的 Manager trait,实现了 trait 中的 connect 和 check 方法,功能分别是创建一个可用的连接、检查连接是否可用。
再来看第 2 点,如何在多个线程中都可以使用这个连接池。从 Rust 代码来看,核心思路就是有一个全局的变量,并且在不同的线程中使用该变量。
因为我们肯定会有多个服务端节点和多个 gRPC Service,因此我们 需要管理多个服务端节点及其对应的gRPC Service 的连接池。这里我们是通过一个名为 ClientPool 的结构体来管理这些连接池。
来看一下 ClientPool 的代码。
#![allow(unused)] fn main() { #[derive(Clone)] pub struct ClientPool { // 定义每个连接池的最大连接数 max_open_connection: u64, // 使用 DashMap 来存储每个服务端IP 和GRPC Service对应的连接池 placement_center_kv_service_pools: DashMap<String, Pool<KvServiceManager>>, } impl ClientPool { pub fn new(max_open_connection: u64) -> Self { Self { max_open_connection, placement_center_kv_service_pools: DashMap::with_capacity(2), } } pub async fn placement_center_kv_services_client( &self, addr: String, ) -> Result<Connection<KvServiceManager>, CommonError> { let module = "KvServices".to_string(); // 根据模块和地址构建一个 key,唯一标识服务器和GRPC Service let key = format!("{}_{}_{}", "PlacementCenter", module, addr); // 判断连接池是否存在 if !self.placement_center_kv_service_pools.contains_key(&key) { // 创建一个连接池 let manager = KvServiceManager::new(addr.clone()); let pool = Pool::builder() .max_open(self.max_open_connection) .build(manager); // 将连接池存储在 map 中 self.placement_center_kv_service_pools .insert(key.clone(), pool); } // 从 map 中取出目标 IP 对应的连接池 if let Some(poll) = self.placement_center_kv_service_pools.get(&key) { // 从连接池获取可用的连接 match poll.get().await { Ok(conn) => { return Ok(conn); } Err(e) => { return Err(CommonError::NoAvailableGrpcConnection( module, e.to_string(), )); } }; } return Err(CommonError::NoAvailableGrpcConnection( module, "connection pool is not initialized".to_string(), )); } } }
这段代码并不复杂,核心逻辑是通过 DashMap 缓存每个 IP 和 gRPC Service 组成的二元组对应的连接池。当需要访问某个服务器的 Service 时,就从 DashMap 中取出对应的连接池,获取可用连接,并访问服务。
接下来看一下连接池如何使用。
#![allow(unused)] fn main() { // 初始化ClientPoll let client_poll: Arc<ClientPool> = Arc::new(ClientPool::new(5)); // 从连接池获取可用连接 match client_poll.placement_center_kv_services_client(addr).await { Ok(client) => { let key = "mq".to_string(); let value = "robustmq".to_string(); let request = tonic::Request::new(SetRequest { key: key.clone(), value: value.clone(), }); let _ = client.set(request).await.unwrap(); } Err(e) => { } } }
上面这段代码比较简单,就不展开讲了。不过这里有个细节问题,就是它执行一次就会返回。如果出现网络抖动错误,就会直接失败。从使用者的角度,我们会希望它能够自动进行重试 。
所以接下来我们来实现统一的自动重试机制。
客户端实现统一的自动重试机制
从原理上看,自动重试的思路不复杂,核心逻辑就是将上面的代码装到一个 loop { } 中,当请求成功时退出循环,如果失败则根据重试策略进行重试。伪代码如下所示:
#![allow(unused)] fn main() { let mut times = 1; loop{ // 初始化ClientPoll let client_poll: Arc<ClientPool> = Arc::new(ClientPool::new(5)); // 从连接池获取可用连接 match client_poll.placement_center_kv_services_client(addr).await { Ok(client) => { let key = "mq".to_string(); let value = "robustmq".to_string(); let request = tonic::Request::new(SetRequest { key: key.clone(), value: value.clone(), }); match client.set(request).await{ Ok(_) => break; Err(e) => { // 达到最大次数时,退出循环 if times > retry_times() { break } // 重试次数 + 1 times = times + 1; } } } Err(e) => { } } } }
这段代码也很好理解,但是有一个问题,就是因为 上面只是client.set 的调用,我们还会有client.get/delete/exists的调用,那每一个都是像上面这样加一个 loop 循环和重试次数的判断吗? 有没有更简单的方法呢?
答案肯定是不能每个方法都有loop + 重试策略,这样代码就太不优雅了,并且后续如果要改重试策略,那么就特别繁琐。
接下来我们以 Set 方法举例,来介绍一下我们的实现。
tips:我们这种写法不是唯一的写法,可能也不是最好的写法。你可以按照需求写一个自己的实现,和我们的实现对比,看思路有哪些差异。
从实现来看,会涉及到下面四个方法:
-
placement_set:封装了连接池和重试机制的 Kv Service 的 Set 方法。它接受连接池 client_poll、服务端地址列表、请求参数来完成 Set 请求的调用。
-
retry_call:重试策略的核心代码,统一封装了重试策略。
-
kv_interface_call:因为 gRPC 的特性是,每一个 Service 都有一个独立的 Client,比如 KVService 就有一个 KVClient,因此就需要对每个 Service 的调用做一个分流。
-
inner_set:封装 KVService Set 调用的统一逻辑。
下面我们来看一下这四个方法的主要逻辑,完整代码你可以看 《placement/kv》。
- placement_set
#![allow(unused)] fn main() { pub async fn placement_set( client_poll: Arc<ClientPool>, addrs: Vec<String>, request: SetRequest, ) -> Result<CommonReply, CommonError> { // 将SetRequest 转化为 vec 类型,递交给 retry_call 处理 let request_data = SetRequest::encode_to_vec(&request); match retry_call( // 定义这次调用是 KvClient PlacementCenterService::Kv, // 定义这次调用的是KvClient 的 set 方法 PlacementCenterInterface::Set, // client poll、addrs、request_data 请求方法 client_poll, addrs, request_data, ) .await { // 将返回结果 decode 为CommonReply类型,并返回 Ok(data) => match CommonReply::decode(data.as_ref()) { Ok(da) => return Ok(da), Err(e) => return Err(CommonError::CommmonError(e.to_string())), }, Err(e) => { return Err(e); } } } }
- retry_call
#![allow(unused)] fn main() { async fn retry_call( service: PlacementCenterService, interface: PlacementCenterInterface, client_poll: Arc<ClientPool>, addrs: Vec<String>, request: Vec<u8>, ) -> Result<Vec<u8>, CommonError> { let mut times = 1; loop { let index = times % addrs.len(); let addr = addrs.get(index).unwrap().clone(); let result = match service { // 执行 Kv Service 的方法 PlacementCenterService::Kv => { kv_interface_call( interface.clone(), client_poll.clone(), addr.clone(), request.clone(), ) .await } }; match result { Ok(data) => { return Ok(data); } Err(e) => { error!( "{:?}@{:?}@{},{},", service.clone(), interface.clone(), addr.clone(), e ); // 定义最大重试次数 if times > retry_times() { return Err(e); } times = times + 1; } } // 定义重试的退避策略 sleep(Duration::from_secs(retry_sleep_time(times) as u64)).await; } } }
- kv_interface_call
#![allow(unused)] fn main() { pub(crate) async fn kv_interface_call( interface: PlacementCenterInterface, client_poll: Arc<ClientPool>, addr: String, request: Vec<u8>, ) -> Result<Vec<u8>, CommonError> { // 获取 Kv Client match kv_client(client_poll.clone(), addr.clone()).await { Ok(client) => { // 执行对应的 set、delete、get、exists 方法 let result = match interface { PlacementCenterInterface::Set => inner_set(client, request.clone()).await, PlacementCenterInterface::Delete => inner_delete(client, request.clone()).await, PlacementCenterInterface::Get => inner_get(client, request.clone()).await, PlacementCenterInterface::Exists => inner_exists(client, request.clone()).await, _ => return Err(CommonError::CommmonError(format!( "kv service does not support service interfaces [{:?}]", interface ))), }; // 返回结果 match result { Ok(data) => return Ok(data), Err(e) => { return Err(e); } } } Err(e) => { return Err(e); } } } }
- inner_set
#![allow(unused)] fn main() { pub(crate) async fn inner_set( mut client: Connection<KvServiceManager>, request: Vec<u8>, ) -> Result<Vec<u8>, CommonError> { // 将请求 decode 为SetRequest match SetRequest::decode(request.as_ref()) { // 调用 kvCleint 的 set 方法 Ok(request) => match client.set(request).await { Ok(result) => { // 将返回值encode 为 vec,返回 return Ok(CommonReply::encode_to_vec(&result.into_inner())); } Err(e) => return Err(CommonError::GrpcServerStatus(e)), }, Err(e) => { return Err(CommonError::CommmonError(e.to_string())); } } } }
可以看到,上面我们 为了统一封装多个gRPC Service 的重试策略,流程分为了四步。从代码上看,核心思路是通过 match 来区分不同的 Client 和不同的方法,并进行调用。
当前这个实现的好处就是流程清晰,代码可读性比较强,不过代码看起来是比较繁琐的。所以我们在主项目 RobustMQ 中有一个更优雅的实现,但是这个优雅实现的代码可读性较差,使用了大量的泛型和 trait,有兴趣的话你也可以去参考一下。
聊完了客户端,我们来聊聊服务端的性能优化。
Leader 写和所有节点可读
从原理上看,集群中 Leader 节点同时负责写入和读取是为了解决数据一致性的问题。这种方式的好处是不管如何读写,数据都是准确的、最新的。缺点是 Leader 节点会成为集群的性能瓶颈,无法横向扩容。
在服务端性能优化中,一个核心思考点是: 服务端的性能是可以随着节点的横向扩容而增强的。为了解决横向扩容的问题,就需要把 Leader 的压力分摊到所有节点上。
从技术上看,元数据服务的业务特点是读写比例较低,也就是 写少读多。因此我们可以先把读请求的压力从 Leader 分摊到所有节点上。
那代码上看要怎么实现呢? 先来看架构图。
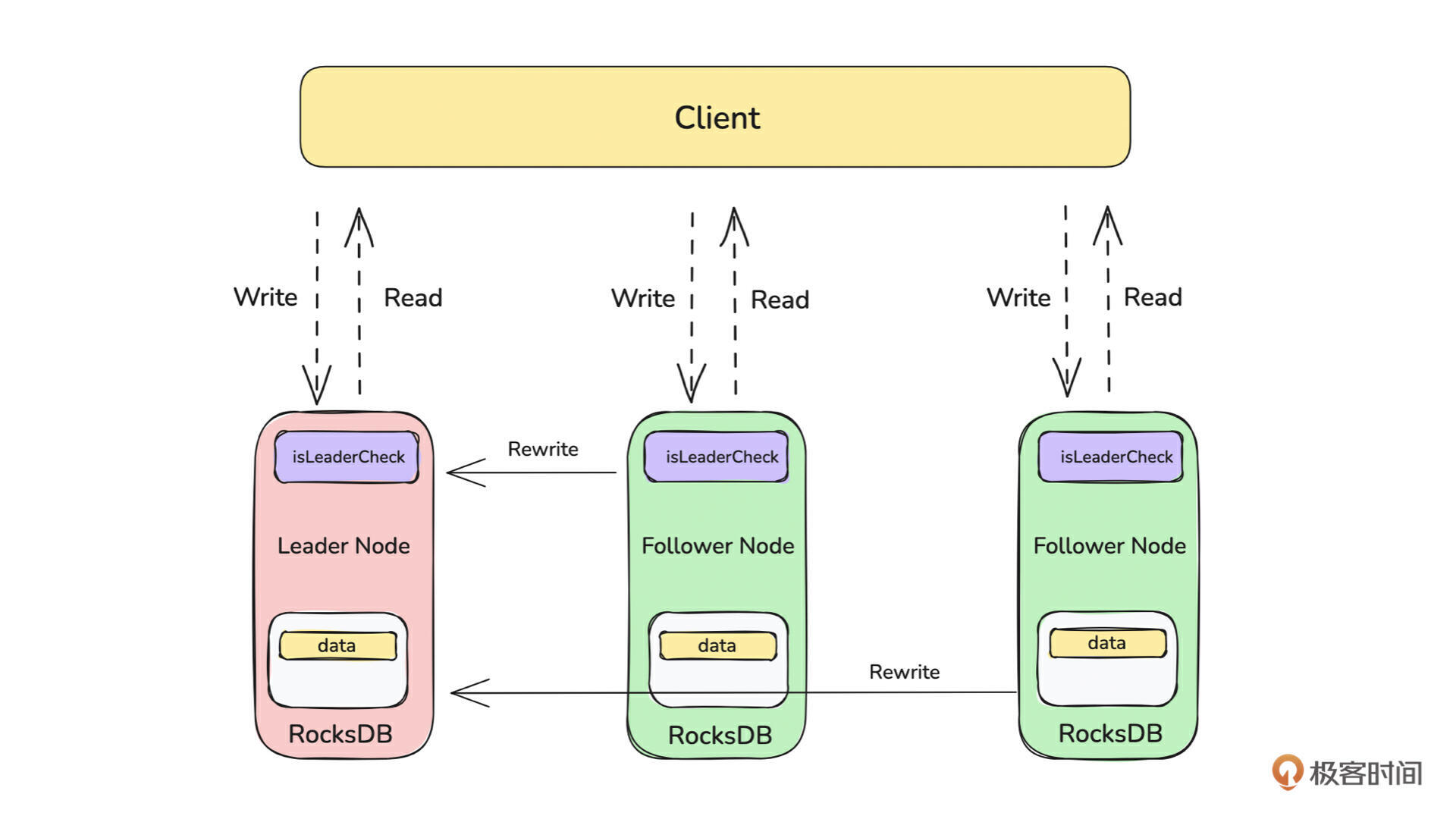
上面的核心思路是:
-
客户端允许配置服务端地址列表,客户端会轮询挑选一台服务器进行访问。
-
服务端判断标记每一个接口是读请求还是写请求。比如 KV 存储模型中 Set/Delete 是写请求,Get/Exists 是读请求。
-
服务器会根据请求的类型进行处理。
-
如果是写请求,会先判断自己是否是 Leader,如果是则直接处理请求,如果自己是 Follwer,则将该请求转发到 Leader 进行处理;
-
如果是读请求,则可以直接处理请求。
-
第 1 点在前面的客户端代码已经实现了。在上面举例的 Set 操作的placement_set和retry_call中。placement_set 接受的服务器地址 addrs 是一个 Vec 列表,即允许配置多个服务器地址。在retry_call中,当请求处理失败后,会更换一个新的服务器进行访问,以避免某个节点无法提供服务。主要起作用的代码是:
#![allow(unused)] fn main() { loop{ let index = times % addrs.len(); let addr = addrs.get(index).unwrap().clone(); ...... times = times + 1; } }
第 2 点标记接口是读还是写请求需要人工判断。比如 KvService 中有 Set/Get/Delete/Exists 四个请求。从接口功能来看,Set 和 Delete 会改变数据的内容,所以它属于写请求。而 Get 和 Exists 只是会读取数据,因此它属于读请求。
第 3 点的实现主要是代码逻辑的处理,完整代码在 《services_kv.rs》 中,我们以 Set 和 Get 来分别讲一下写/读请求的处理。
先来看 Set 的代码:
#![allow(unused)] fn main() { async fn set(&self, request: Request<SetRequest>) -> Result<Response<CommonReply>, Status> { let req = request.into_inner(); // if req.key.is_empty() || req.value.is_empty() { return Err(Status::cancelled( RobustMQError::ParameterCannotBeNull("key or value".to_string()).to_string(), )); } if !self.is_leader() { let leader_addr = self.leader_addr(); match placement_set(self.client_poll.clone(), vec![leader_addr], req).await { Ok(reply) => { return Ok(Response::new(reply)); } Err(e) => { return Err(Status::cancelled(e.to_string())); } } } // Raft state machine is used to store Node data let data = StorageData::new(StorageDataType::KvSet, SetRequest::encode_to_vec(&req)); match self .placement_center_storage .apply_propose_message(data, "set".to_string()) .await { Ok(_) => return Ok(Response::new(CommonReply::default())), Err(e) => { return Err(Status::cancelled(e.to_string())); } } } }
上面这段代码在上节课已经讲过,只是添加了下面这段代码:
#![allow(unused)] fn main() { if !self.is_leader() { let leader_addr = self.leader_addr(); match placement_set(self.client_poll.clone(), vec![leader_addr], req).await { Ok(reply) => { return Ok(Response::new(reply)); } Err(e) => { return Err(Status::cancelled(e.to_string())); } } } }
即判断当前节点是否是 Leader,如果不是Leader,则获取 Leader 的地址,并将请求转发到 Leader 节点进行处理。is_leader 和 leader_addr 的逻辑如下:
#![allow(unused)] fn main() { pub fn is_leader(&self) -> bool { return self.placement_cluster.read().unwrap().is_leader(); } pub fn leader_addr(&self) -> String { return self.placement_cluster.read().unwrap().leader_addr(); } }
结合 第 9 课 可以知道,Leader 信息是由 Raft 状态机来维护的。当 Leader 发生切换时,Raft 状态机就会触发 Leader 信息的变更。
也就是说如果是写请求,就通过is_leader判断本节点是否是 Leader,是的话就正常处理,否的话就通过leader_addr方法获取 Leader 地址,并通过我们在这节课前半部分开发的客户端将请求转发给 Leader 进行处理。
再来看一下 Get 的代码:
#![allow(unused)] fn main() { async fn get(&self, request: Request<GetRequest>) -> Result<Response<GetReply>, Status> { let req = request.into_inner(); if req.key.is_empty() { return Err(Status::cancelled( RobustMQError::ParameterCannotBeNull("key".to_string()).to_string(), )); } // 实例化KvStorage let kv_storage = KvStorage::new(self.rocksdb_engine_handler.clone()); let mut reply = GetReply::default(); // 从 RocksDB 中获取对应 Key 的数据 match kv_storage.get(req.key) { Ok(Some(data)) => { reply.value = data; return Ok(Response::new(reply)); } Ok(None) => {} Err(e) => return Err(Status::cancelled(e.to_string())), } return Ok(Response::new(reply)); } }
上面的代码比较简单,就是直接通过 KvStorage 从 RocksDB 中获取对应的 Key 数据。因为 Get 是读请求,则不需要进行判断转发的逻辑,直接进行逻辑处理即可。
到了这里,如下图所示,我们就完成了 Leader 负责写入、所有节点可读的特性了。
总结
tips:每节课的代码都能在项目 https://github.com/robustmq/robustmq-geek 中找到源码,有兴趣的同学可以下载源码来看。
这节课我们讲了通过连接池来提高客户端访问服务端的性能,并通过合适的代码实现统一封装多个 RPC Service 的重试机制,从而实现所有客户端调用都有统一的重试策略。然后通过在区分读写请求,并针对写请求做判断,从而实现了 Leader 写和所有节点可读的特性。
我们在 《深入拆解消息队列47 讲》 中讲到过,集群性能的提升包括单节点性能的提升和集群能力的提升。单节点性能的提升主要是网络层、存储层、计算层的性能的提升,在元数据服务中就是我们第 5 课(网络层)和第 6 课(存储层)的部分。
而集群能力的提升核心就是允许水平扩展,Leader 写和所有节点可读只是第一步,因为集群的写入压力都集中在 Leader 上,如果写入请求太大,那么依旧会出问题。所以下一步就是实现 Raft Group 的能力,即第 9 课说的允许集群中有多个 Leader 的存在。Raft Group 的特性,课程中我们没有展开,欢迎在交流群中讨论。
思考题
这里是本节课推荐的相关 issue 的任务列表,请点击查看 《Good First Issue》,任务列表会不间断地更新。另外欢迎给我的项目 https://github.com/robustmq/robustmq 点个 Star 啊!
结束语|第一阶段课程结尾展望
本课程为精品小课,不标配音频
你好,我是文强。
到今天我们就正式结束这次课程了,在这门课程中我们基于 gRPC + RocksDB + Raft 构建了一个元数据服务集群。
从内容来看,每节课涉及的内容很多,包括但不限于 Rust 语言本身的知识点,还有比如分布式系统、网络、存储相关的内容。所以学习这个课程的过程可能会让你觉得有点吃力。不过,吃力也是合理的,内容知识点确实很多。
因此,这里我想再分享一下我对这门课程的期待和定位。在做课程设计的时候,我就明确了,我不想教你那种很基础的官方知识点的“翻译”,而是想教给你一些在平时很难获得的东西,在我看来可以叫做“经验”。
因此《Rust 实战 · 手写下一代云原生消息队列》这个课程 不只是想教你 Rust,而是以 Rust 为抓手,带你去做一个真正具有工业化水准的基础软件。希望在这个课程中你可以获得:
-
学好、学会 Rust 这个语言本身。
-
知道如何开发实现一个分布式存储系统。
-
参与写一个具有工业化水准的开源基础软件的经验。
-
学会思考,技术上为什么会这么做,为什么不那么做。
当然,一分耕耘、一份收获,想从这个课程中获得更多的“经验”,就需要你更加投入,去理解课程、去理解代码、去旁征博引地学习更多内容,去交流群讨论和学习等等。编码、学习本身是一件很辛苦的过程。 当你获得某个技能的过程越艰难,从某种程度来说你的竞争力就越强。
另外,在本次课程中,你会发现我们有两个项目 《robustmq-geek》 和 《robustmq》。robustmq-geek 是课程配套的可运行的 Demo 示例,robustmq 是我们在社区推进的消息队列领域的开源项目。你可以理解 robustmq-geek 是开源项目 robustmq 的教学简化版,你也可以理解 robustmq 是 robustmq-geek 的工业化版本。
从课程设计的角度,我的初衷是希望你学会了本次课程后,能够去参与 robustmq 的开发。从而给你提供一个梯度,从简单到复杂,从示例项目到开源的工业化的基础软件项目,带你更好地去获得“经验”。
以终为始,为了告诉你我的系列课程最终会带你做成一个什么样子的基础软件。下面我来简单介绍一下 RobustMQ。
RobustMQ 的定位是 基于 Rust 构建兼容多种主流消息队列协议、架构上具备完整 Serveless 能力的下一代高性能云原生融合型消息队列。我希望把 RobustMQ 打造成下一个消息队列领域的 Apache 顶级项目。
它的整体架构图如下:
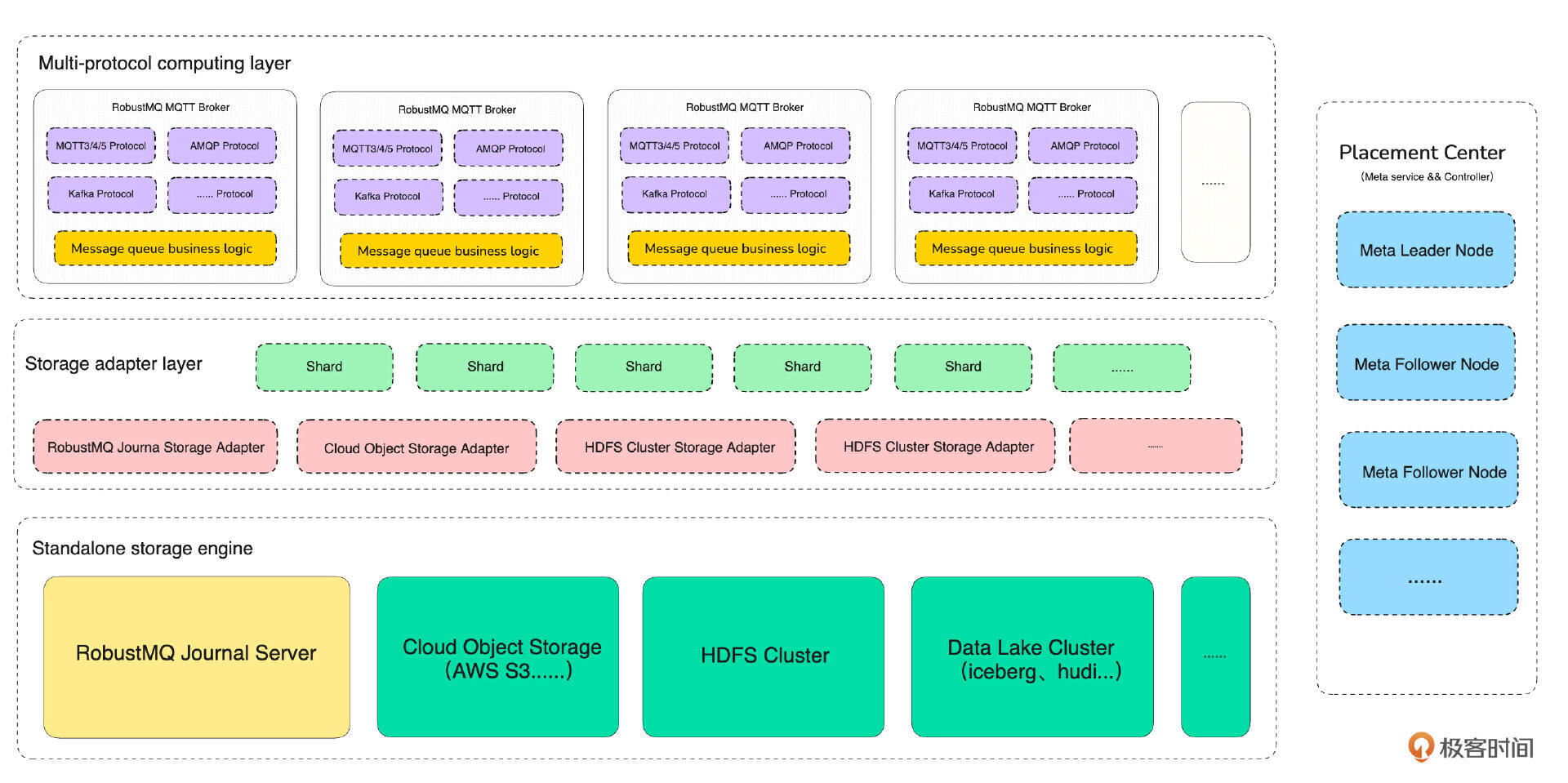
从设计的角度看,RobustMQ 是一个典型的分布式分层架构,包含计算层、存储层、调度层分离等。具体由 控制层(Placement Center)、计算层(Multi-protocol computing layer)、 存储适配层(Storage Adapter Layer)、 独立的远端存储层(Standalone storage engine) 四个部分组成。每一层都具备快速扩缩容能力,从而达到整个系统具备完整的 Serverless 能力。
因此它具备以下特点:
-
100% Rust: 完全基于 Rust 语言实现的消息队列引擎。
-
多协议: 支持 MQTT 3.1/3.1.1/5.0、AMQP、Kafka Protocol、RocketMQ Remoting/gRPC、OpenMessing、JNS、SQS 等主流消息协议。
-
分层架构: 计算、存储、调度独立的三层架构,每层均具备集群化部署、快速水平扩缩容的能力。
-
插件式存储: 独立插件式的存储层实现,可根据需要选择合适的存储层。兼容传统和云原生架构,支持云、IDC 多种部署形态。
-
高内聚架构:提供内置的元数据存储组件(Placement Center)和分布式存储服务(RobustMQ Journal Server),具备快速、简单、内聚的部署能力。
-
功能丰富: 支持顺序消息、死信消息、事务消息、幂等消息、延时消息等丰富的消息队列功能。
从项目愿景和技术架构来看,RobustMQ 是一个非常大的工程,非常有技术含量。如果你用心参与和学习,在我看来这个工程肯定可以给你带来成长,甚至是无与伦比的竞争力。
这里给你分享几个 RobustMQ 的资料,以便让你更好地了解RobustMQ。
-
Rust Conf 2024 分享 PPT: 《RobustMQ - 下一代高性能云原生融合型消息队列》
-
Rust Conf 2024 分享视频: 《RobustMQ - 下一代高性能云原生融合型消息队列》
课程的最后,祝愿你和我一样能在学习的过程中获得更多的踏实感,希望我们一起在这个内卷的环境中愈发从容!