数据存储:如何实现单机持久化的存储服务?
本课程为精品小课,不标配音频
你好,我是文强。
上节课我们完成了 Server 模块的开发,接下来我们来实现元数据存储服务中的单机存储层。首先,我们需要来看一下单机存储层的技术方案如何选型。
存储层实现设计考量
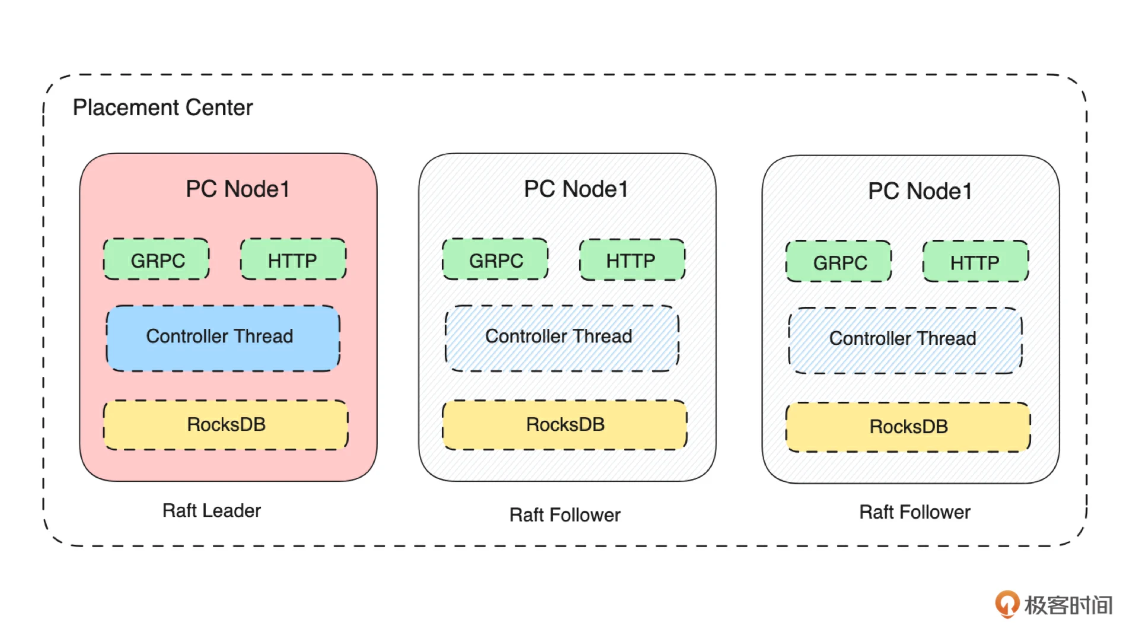
如下图所示,我们知道了元数据存储服务的核心是 KV 模型数据的存储。
那如何来实现这个存储层呢?从技术上来看,一般有三个思路:
-
基于文件系统从头实现数据存储。
-
基于现有成熟的分布式存储引擎完成数据的存储,比如 ZooKeeper、etcd等。
-
基于现有成熟的嵌入式键值数据库实现,比如 RocksDB、LevelDB 等。
第一种方案很直观,可能也是我们在选型时首先想到的思路,但是 这种方案是最不推荐的。因为从零开始写一个生产级别的存储层是非常困难的,周期很长,稳定性差。比如需要处理硬件和操作系统随时都有可能丢失或损坏数据的情况,另外写入性能优化需要大量时间投入,还得处理代码 Bug 等情况。
第二种方案是常用的方案,依赖成熟的分布式存储引擎存储数据,是比较快速且稳定的方案。但是这种方案的缺点是需要依赖外部系统,会导致架构复杂,长期运维成本高,另外外部依赖组件的稳定性也会影响主系统的稳定。因为我们要实现的消息队列其中一个设计目标就是: 高内聚和弱外部依赖。如果选择这种方案,就破坏了这个目标,长期来看,不太合理。
第三种方案从某种角度看和第一种是同一个思路。区别是存储层不是自己实现的,而是依赖现有的成熟、可靠、高性能的嵌入式键值存储来实现存储层。这种方案的开发成本低,性能和可靠性也有保证。目前业界主要的嵌入式键值存储有 RocksDB、LevelDB 等。目前使用较多的是 RocksDB,业界很多知名公司和开源项目都在使用它。比如 TiKV、CRDB都是基于 RocksDB 来实现的。
所以,从实现难度、稳定性、性能等三个方面考虑,我们选择了第三种方案。从元数据存储服务(Placement Center) 的功能需求和业界嵌入式键值数据库的功能、稳定性、项目成熟度、社区活跃度来看,我认为 RocksDB 非常适合来当存储层。
接下来我们从功能和架构上简单介绍一下 RocksDB。
RocksDB 简介
从功能层面来看,RocksDB 它是一个嵌入式的键值存储引擎,它提供了下面几个主要的功能函数调用:
-
Put(Key, Value):插入新的Key-Value对或更新现有 Key 的值。
-
Get(Key):获取特定 Key 的值。
-
Delete(Key):删除特定 Key 的值。
-
Merge(Key, Value):将新值与给定 Key 的现有值合并。
-
Seek(key_prefix):匹配指定 Key 的前缀或大于 Key 的前缀。
从这几个函数来看,它是标准 KV 模型的存储,即 set/get/delete/search 类型的方法。
从代码层面来看, RocksDB 就一个 Lib,不是一个 Server,是一个被项目引用的库。也就是说它没有独立的进程运行,是和主进程共享内存空间。比如在 Java 中它是 Maven 的 Package,在 Rust 中,它是一个 crate 上的 Lib,在 Go 中它是一个 Module。
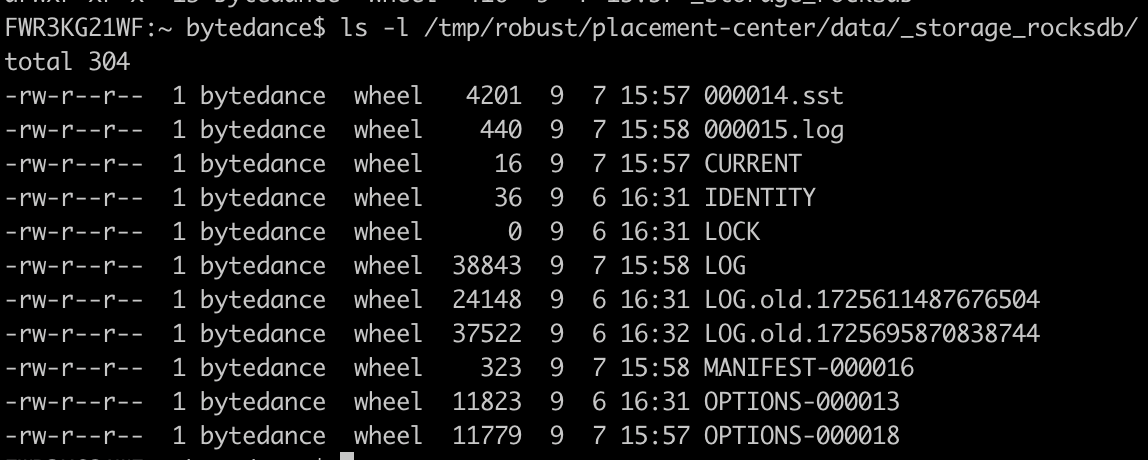
从底层存储的角度来看,RocksDB 的数据是 存储在单机本地硬盘的文件中的,也就是说它是本地存储的。即通过 Put 函数写入的数据,都是存储在本机的文件中的。RocksDB 的本地文件存储结构如下,会包含 sst、log 等等信息。
从底层原理来看,它是基于 LSM-Tree(Log-Structured Merge Tree) 实现的一种本地存储引擎。如果对存储系统有了解的人,对 LSM 应该不会陌生。如果你希望对存储系统了解更多,建议你去研究一下 LSM,它是一种基于日志结构的数据结构,能够高效地存储和更新键值数据。LSM 这块的资料特别多,就不展开细讲了。
因为接下来我们会用到 RocksDB 中的列簇(ColumnFamily) 的概念,所以我们先来了解一下它是什么。
ColumnFamily 是 RocksDB 中的一个逻辑概念,它的功能是 用于 Key 的组织。 比如一部分的 key 存储在 A ColumnFamily,另外一部分 key 存储在 B ColumnFamily。ColumnFamily 和 key 的关系,有点像 MySQL 中 Database 和 table 的关系。Database 用于 table 的逻辑组织,table 一定要属于某个 Database。默认情况下,RocksDB 中所有的 key 都在一个默认的 ColumnFamily 中。
了解了 RocksDB,接下来我们来看一下在元数据存储服务中,如何基于 RocksDB 实现存储层。
Rust Rocksdb 入门
在 Rust 中,需要通过 Rust 库 《rocksdb》 来使用 RocksDB。从代码实现的层面看,主要包含下面七个部分:
-
构建 RocksDB 配置
-
初始化 RocksDB 实例
-
写数据(Write)
-
根据 Key 读取数据(Get)
-
根据 Key 删除数据(Delete)
-
判断 Key 是否存在(Exists)
-
根据前缀读取数据(read_prefix)
接下来我们主要跟随代码实现来一个一个讲解。
- 构建 RocksDB 配置
构建配置的主要工作是设置 RocksDB 实例的配置选项(Options)。代码实现很简单,难点在于: 要理解 RocksDB 的运行原理 , 每个配置项的意义,然后根据自己的场景和要求进行配置优化,这个是和语言无关的。
配置初始化代码如下:
#![allow(unused)] fn main() { fn open_db_opts(config: &PlacementCenterConfig) -> Options { let mut opts = Options::default(); opts.create_if_missing(true); opts.create_missing_column_families(true); opts.set_max_open_files(1000); opts.set_use_fsync(false); opts.set_bytes_per_sync(8388608); opts.optimize_for_point_lookup(1024); opts.set_table_cache_num_shard_bits(6); opts.set_max_write_buffer_number(32); opts.set_write_buffer_size(536870912); opts.set_target_file_size_base(1073741824); opts.set_min_write_buffer_number_to_merge(4); opts.set_level_zero_stop_writes_trigger(2000); opts.set_level_zero_slowdown_writes_trigger(0); opts.set_compaction_style(DBCompactionStyle::Universal); opts.set_disable_auto_compactions(true); let transform = SliceTransform::create_fixed_prefix(10); opts.set_prefix_extractor(transform); opts.set_memtable_prefix_bloom_ratio(0.2); return opts; } }
这段代码很简单,直接看这个 《Rust RocksDB Options》 文档即可。默认情况下,使用 Options::default() 可得到默认配置,这些配置可以满足大部分场景。
因为 RocksDB 的配置优化是一个很大和很复杂的话题,如果要进行针对性的配置调优,你就需要去看一下这个文档 《RocksDB 官方 wiki》,去对 RocksDB 的底层运行原理(主要是LSM-Tree)、配置项所表达的意义有更多的了解,才能找到最适合自己场景的配置项。
- 初始化 RocksDB 实例
这一步的目的是 初始化一个可以操作 RocksDB 的对象实例。主要流程是构建配置,判断是否已经初始化过 RocksDB,如果没有就初始化 DB,然后打开需要操作的列簇(ColumnFamily)即可。
#![allow(unused)] fn main() { // 初始化RocksDB 配置 let opts: Options = Self::open_db_opts(config); // 配置 RocksDB 的数据目录 let db_path = format!("{}/{}", config.data_path, "_storage_rocksdb"); // 判断 RocksDB 是否初始化成功,否则进行初始化。 if !Path::new(&db_path).exists() { DB::open(&opts, db_path.clone()).unwrap(); } // 初始化 RocksDB 中的列簇。 let cf_list = rocksdb::DB::list_cf(&opts, &db_path).unwrap(); let mut instance = DB::open_cf(&opts, db_path.clone(), &cf_list).unwrap(); }
上面这段代码需要关注的点是: 初始化后的 instance 全局只能有一个。即一个 RocksDB 目录只能同时被一个实例持有,不能多次 Open 一个 RocksDB 目录,否则就会报下面的错误。

所以在实际使用中,需要 通过 Arc 在多线程之间共享 RocksDB instance,即 Arc,代码如下:
#![allow(unused)] fn main() { let rocksdb_engine_handler: Arc<RocksDBEngine> = Arc::new(RocksDBEngine::new(&config)); }
在这里,你就会用到智能指针的 Arc ,通过它可以让同一个 RocksDBEngine 在多个线程中共享。
- 写数据(Write)
写数据代码实现比较简单。流程是先选择ColumnFamily,通过 serde_json 序列化数据,最后通过 put_cf 方法将数据写入到 RocksDB 中。
#![allow(unused)] fn main() { pub fn write<T: Serialize + std::fmt::Debug>( &self, cf: &ColumnFamily, key: &str, value: &T, ) -> Result<(), String> { match serde_json::to_string(&value) { Ok(serialized) => self .db .put_cf(cf, key, serialized.into_bytes()) .map_err(|err| format!("Failed to put to ColumnFamily:{:?}", err)), Err(err) => Err(format!( "Failed to serialize to String. T: {:?}, err: {:?}", value, err )), } } }
上面这段代码需要注意的是,写入数据必须选择ColumnFamily,原因是 作为元数据服务,它需要存储不同类型的数据,并且长期可能有较大的数据量。为了长期扩容、拆分、隔离的方便,就需要将数据进行逻辑拆分。
- 读(Get)/ 删除(Delete)数据,并判断数据是否存在(Exists)
读数据是通过RocksDB 的 get_cf 方法来获取到数据,Decord 后返回即可。
删除和判断数据是否存在是通过 delete、key_may_exist_cf 函数来完成功能。
#![allow(unused)] fn main() { // Read data from the RocksDB pub fn read<T: DeserializeOwned>( &self, cf: &ColumnFamily, key: &str, ) -> Result<Option<T>, String> { match self.db.get_cf(cf, key) { Ok(opt) => match opt { Some(found) => match String::from_utf8(found) { Ok(s) => match serde_json::from_str::<T>(&s) { Ok(t) => Ok(Some(t)), Err(err) => Err(format!("Failed to deserialize: {:?}", err)), }, Err(err) => Err(format!("Failed to deserialize: {:?}", err)), }, None => Ok(None), }, Err(err) => Err(format!("Failed to get from ColumnFamily: {:?}", err)), } } // 根据 key 删除数据 pub fn delete(&self, cf: &ColumnFamily, key: &str) -> Result<(), RobustMQError> { return Ok(self.db.delete_cf(cf, key)?); } // 判断 key 是否存在 pub fn exist(&self, cf: &ColumnFamily, key: &str) -> bool { self.db.key_may_exist_cf(cf, key) } }
- 根据前缀读取数据(read_prefix)
在实际项目中,除了 Set 和 Get 的需求,还有一个需求你经常会用到,就是 前缀搜索。即根据某个 Key 的前缀来获取这个 Key 对应的所有数据。
比如我们需要存储集群中的 User,每个 User 的 key 如下:
#![allow(unused)] fn main() { pub fn storage_key_mqtt_user(cluster_name: &String, user_name: &String) -> String { return format!("/mqtt/user/{}/{}", cluster_name, user_name); } }
如果要获取集群中所有的用户列表,肯定不能找一个地方存储所有的客户信息,然后 foreach 循环一个一个去获取。此时就可以用前缀搜索,前缀搜索的 key 如下:
#![allow(unused)] fn main() { pub fn storage_key_mqtt_user_cluster_prefix(cluster_name: &String) -> String { return format!("/mqtt/user/{}", cluster_name); } }
接下来,我们来看一下如何实现前缀搜索。
RocksDB 中提供了前缀搜索的功能。因为 RocksDB 底层存储数据时是根据 Key 排序存储的,所以前缀搜索的底层逻辑是: 先通过 seek 方法找到该前缀对应的第一个 Key,再通过next 方法一个一个往后获取数据,从而得到该前缀对应的所有Key。
#![allow(unused)] fn main() { // Search data by prefix pub fn read_prefix( &self, cf: &ColumnFamily, search_key: &str, ) -> Vec<HashMap<String, Vec<u8>>> { // 获取 ColumnFamily 的迭代器 let mut iter = self.db.raw_iterator_cf(cf); // 搜索到第一个匹配这个前缀的 key iter.seek(search_key); let mut result = Vec::new(); // 获取下一个 key 的值 while iter.valid() { let key = iter.key(); let value = iter.value(); let mut raw = HashMap::new(); // 如果 key 和 value 都为空,则退出循环 if key == None || value == None { break; } let result_key = match String::from_utf8(key.unwrap().to_vec()) { Ok(s) => s, Err(_) => continue, }; // 如果key 不匹配前缀,说明已经获取到所有这个前缀的 key,则退出循环。 if !result_key.starts_with(search_key) { break; } raw.insert(result_key, value.unwrap().to_vec()); result.push(raw); iter.next(); } return result; } }
这里,不知道你是否注意到下面这几行代码,代码的语意是: 判断获取到的数据的Key 是否是搜索的前缀,否则,退出循环。
#![allow(unused)] fn main() { if !result_key.starts_with(search_key) { break; } }
这段代码非常重要,也是前缀搜索的核心。前面说到 RocksDB 的底层数据是根据 Key 顺序存储的,所以先通过 seek 定位到匹配前缀的第一个 key,然后往后逐个获取。
但是需要注意的是: next 方法不会判断数据的 Key 是否匹配这个前缀。如果不加这个判断,则会从 seek 到的 key 开始一直往后获取到整个 RocksDB 的所有数据。
所以每一次拿到数据后,就需要判断 Key 是否匹配我们需要的前缀,如果不匹配,就说明已经获取到同一个前缀的所有数据了,就可以退出循环。
到这里,我们就完成了 RocksDB 基础库的集成使用。从某种意义上来说,我们也就完成了单机存储层的开发。
比想象中简单非常多是吧, 这就是使用现成的嵌入式键值库的好处,也是开源项目 RocksDB、LevelDB 设计的初衷,大大地简化高性能高可靠单机存储层的开发。
接下来我们来完成我们需要的功能: KV 型的数据存储。
使用 RocksDB 存储 KV 数据
我先来问一个问题,我们要存储一个 KV 数据,即 name= “mq”,此时底层应该怎么存储数据呢?
直观来讲,以 name 为 Key,mq 为 Value 存储就可以了。但是扩展一下: 我们是不是需要知道数据的写入时间 、 数据来源(即来源 IP)等等信息。因此我们在底层存储数据时,就需要对数据进行包装,存储一些通用的数据,比如创建时间。
所以我们在底层存储数据的时候,是通过数据结构 StorageDataWrap 来包装保存数据的。
#![allow(unused)] fn main() { #[derive(Serialize, Deserialize, Debug)] pub struct StorageDataWrap { pub data: Vec<u8>, pub create_time: u64, } impl StorageDataWrap { pub fn new(data: Vec<u8>) -> Self { return StorageDataWrap { data, create_time: now_second(), }; } } }
接下来我们以保存数据为例,来看一下我们是如何完成 KV 模型数据存储的。来看下面的代码:
#![allow(unused)] fn main() { fn engine_save<T>( rocksdb_engine_handler: Arc<RocksDBEngine>, rocksdb_cluster: &str, key_name: String, value: T, ) -> Result<(), RobustMQError> where T: Serialize, { let cf = if rocksdb_cluster.to_string() == DB_COLUMN_FAMILY_CLUSTER.to_string() { rocksdb_engine_handler.cf_cluster() } else { return Err(RobustMQError::ClusterNoAvailableNode); }; let content = match serde_json::to_vec(&value) { Ok(data) => data, Err(e) => return Err(RobustMQError::CommmonError(e.to_string())), }; let data = StorageDataWrap::new(content); match rocksdb_engine_handler.write(cf, &key_name, &data) { Ok(_) => { return Ok(()); } Err(e) => { return Err(RobustMQError::CommmonError(e)); } } } }
这里有 4 个关注点:
-
RocksDBEngine 是封装了 RocksDB 读写的一个Struct,里面封装了对RocksDB的打开、读、写等操作。
-
rocksdb_engine_handler: Arc:你会发现这是通过智能指针 Arc 在多线程之间共享 RocksDBEngine。原因就是我们上面提到的,一个 RocksDB 只能由一个RocksDB对象持有,故需要在进程启动时,通过RocksDB 提供的DB::open_cf打开 RocksDB,然后通过智能指针 Arc 在多个线程中共享使用 RocksDBEngine。
-
为了后续的拆分隔离方便,数据默认是写入到名为 cluster 的 ColumnFamily。
-
数据值 Value 是一个泛型,它可以接收任何类型的数据,然后持久化存储。泛型 T 需要通过 Where 关键字限制 Value 必须实现 Serialize Trait。因为只有实现 Trait,它才能进行序列化。
tips:在这部分,你就需要去复习泛型、Arc、Where 的语法,从实际编码角度来看,这三种语法的应用非常广泛。
这里留一个思考题: 我们在 engine_save 和 write 方法中都有使用 serde_json 执行序列化,是不是重复了?是不是可以简化代码 ?
接下来我们可以封装一个 Struct 来根据 Key 保存数据。来看下面的代码:
#![allow(unused)] fn main() { pub struct KvStorage { rocksdb_engine_handler: Arc<RocksDBEngine>, } impl KvStorage { pub fn new(rocksdb_engine_handler: Arc<RocksDBEngine>) -> Self { KvStorage { rocksdb_engine_handler, } } pub fn set(&self, key: String, value: String) -> Result<(), RobustMQError> { return engine_save_by_cluster(self.rocksdb_engine_handler.clone(), key, value); } } }
这段代码比较简单,Key 和 Value 都是 String 类型,直接调用engine_save_by_cluster保存即可。
在业务逻辑上,保存数据直接用 KvStorage 即可,如下所示:
#![allow(unused)] fn main() { pub fn set(&self, value: Vec<u8>) -> Result<(), CommonError> { let req: SetRequest = SetRequest::decode(value.as_ref())?; let kv_storage = KvStorage::new(rocksdb_engine_handler.clone()); return kv_storage.set(req.key, req.value); } }
其他 Get、Delete、List、Exists 方法,思路都是类似的,就不展开了,你可以查看 Demo 中的代码,了解更多。
总结
tips:每节课的代码都能在项目 https://github.com/robustmq/robustmq-geek 中找到源码,有兴趣的同学可以下载源码来看。
这节课我们从选型考量开始讲起,讨论了为什么要选择 RocksDB,Rust RocksDB 的使用细节,以及如何使用 RocksDB 来存储 KV 型数据,进而实现了元数据存储服务的单机存储层。
从技术上来看,我们需要去重点理解为什么要用 RocksDB,有没有其他的选项。因为这个思路是通用的,我们实现其他存储系统的时候都可以借鉴。
在业界,使用 RocksDB 来实现单机存储层,是一个应用非常广泛的方案,如果你有类似的需求,建议优先考虑 RocksDB。
从 Rust 语法方面,泛型、序列化、智能指针等语法都会用到,需要你继续加深对这些语法的理解。
思考题
这里是本节课推荐的相关 issue 的任务列表,请点击查看 《Good First Issue》,任务列表会不间断地更新。欢迎给我的项目 https://github.com/robustmq/robustmq 点个 Star 啊!