基于Raft协议构建分布式集群(三)
本课程为精品小课,不标配音频
你好,我是文强。这节课我们继续完善基于 Raft 协议开发的分布式集群。我们会讲解如何开发 Raft Node 上的 Raft 状态机,并最终构建包括 发起选举、 选举 Leader、 心跳发送 、 心跳过期 等等 Raft 协议定义的核心步骤的集群。
首先我们需要再回顾一下 Raft 协议的原理,以便接下来更好地理解 Raft 状态机的构建。建议你主要回顾前面推荐的 《Raft 协议的动图原理展示》。从功能上看,Raft 算法由下面六个核心流程组成:
-
节点发现
-
发起选举
-
选举 Leader
-
心跳检测
-
心跳超时
-
重新发起选举
所以我们构建状态机也是围绕这六点展开的。最开始先来记住一个定义,就是: Raft 状态机本质上是一个 Tokio 的任务(也就是 Tokio Task)。接下来我们简单聊一下 Raft 状态机的运行原理。
状态机运行原理
先来看下面这张图:
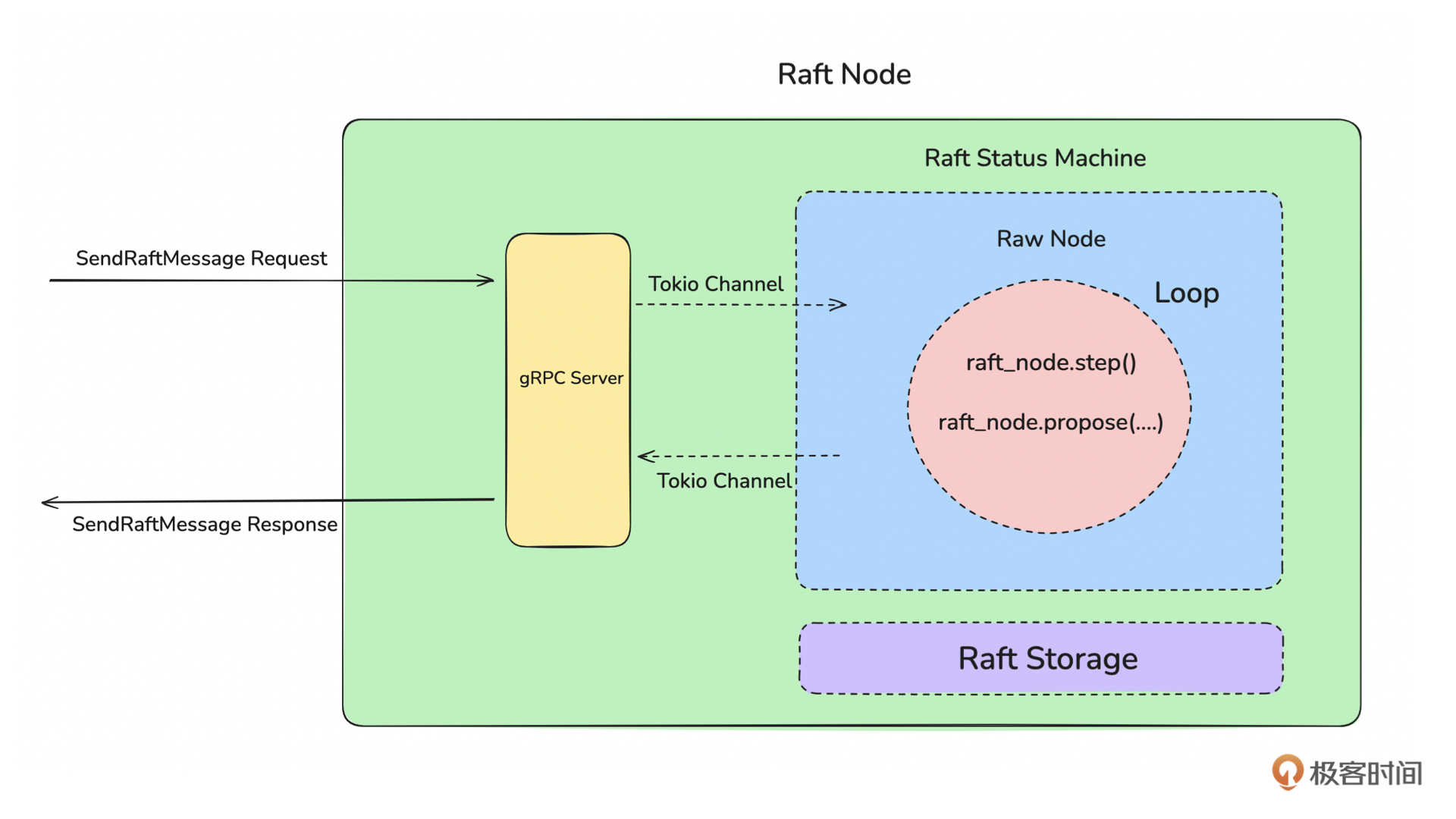
如上图所示,Raft Node 主要由 gRPC Server、Raft 状态机、Raft Storage 三部分组成。其中最关键的是 Raft 状态机,它驱动了 Raft Node 向前运行。从启动流程的角度看,服务启动后,会先启动 gRPC Server、初始化 RawNode,然后启动 Raft 状态机。Raft 状态机本质上是一个 Loop 线程,它会不间断地运行去驱动 RawNode 向前运行。
那什么叫做 RawNode 向前运行呢?
是指每个 RawNode 初始化后,需要根据自己的角色不断地做一些事情。比如,如果是 Leader 节点,那么就需要检测是否有新的用户数据写入,并将用户数据分发给多个 Follower,同时需要定时给 Follower 节点发送心跳信息。如果是 Follower 节点,则需要定时查看是否有心跳,如果有心跳则继续等待下一次心跳,如果心跳过期则发起新的选举。而这些操作都是由 Raft 状态机来驱动的。
不管是 Leader 还是 Follower 的信息,当 Raft 状态机生成消息后,都会通过 Tokio Channel 将消息从网络层发送给其他节点。从而完成发起选举、投票选举 Leader、心跳发送等行为。所以,从集群的角度来看,整体架构图如下:
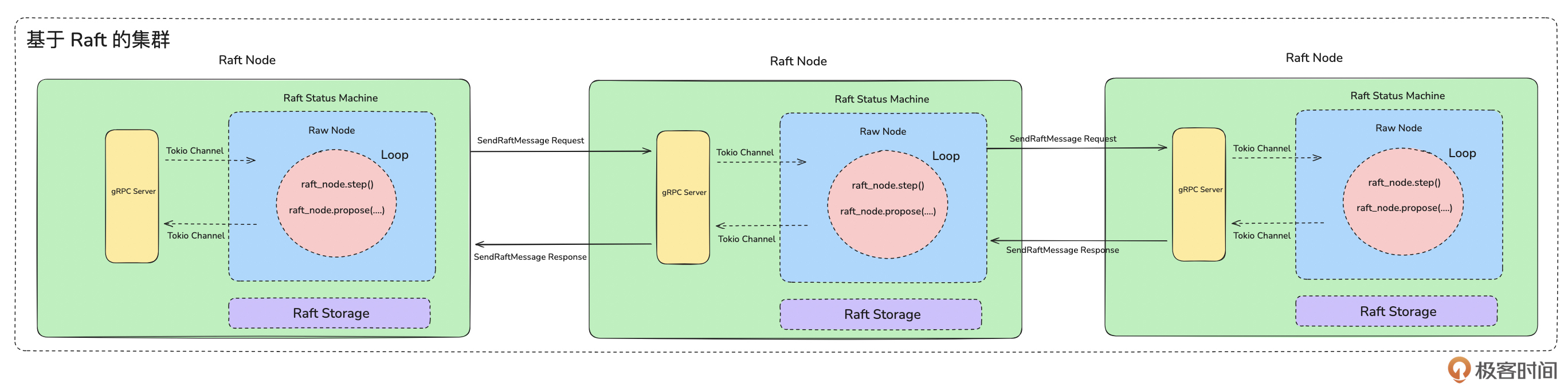
基于上面集群的架构图,我们来讲一下上面的 Raft 算法中的六个核心流程。
- 节点发现:如下代码所示,Raft Node 之间相互发现是在启动时通过 ConfState 中的voters变量来配置的。
#![allow(unused)] fn main() { // 初始化 Raft 的投票者列表 let mut cs = storage.read_lock().conf_state(); cs.voters = cluster.node_ids(); }
-
选举(发起选举和选举 Leader):RaftNode 启动时,Raft 状态机会根据配置的voters节点信息,从其他节点获取当前是否有 Leader,有的话就将自己转变为 Follower 角色,然后根据 Follower 的角色视角去驱动 Raft 状态机的运行。如果当前集群没有 Leader,则 Raft 状态机会发起选举,也就是生成 MsgType 为 MsgRequestVote 的消息,将消息通过 Tokio Channel 发送给网络层,再通过网络层发送给其他 Raft Node。
-
心跳检测:Raft Leader 运行时,Raft 状态机会不间断生成 MsgType 为 MsgHeartbeat 的消息,并将消息发送给 Follower。当 Follower 收到 MsgType 为 MsgHeartbeat 的消息时,会给 Leader 返回 MsgType 为 MsgHeartbeatResponse 的消息。
-
心跳过期 & 重新发起选举:当 Follower 状态机向前驱动时,如果检测到心跳过期,那么则生成 MsgType 为MsgRequestVote的消息,发起一次新的选举。
接下来看一段单机 RaftNode 运行,并将自己选举为 Leader 的日志信息,这段日志展示了RaftNode 从运行到选举为 Leader 的过程(日志就不展开讲了,每一行还是比较容易看懂的)。
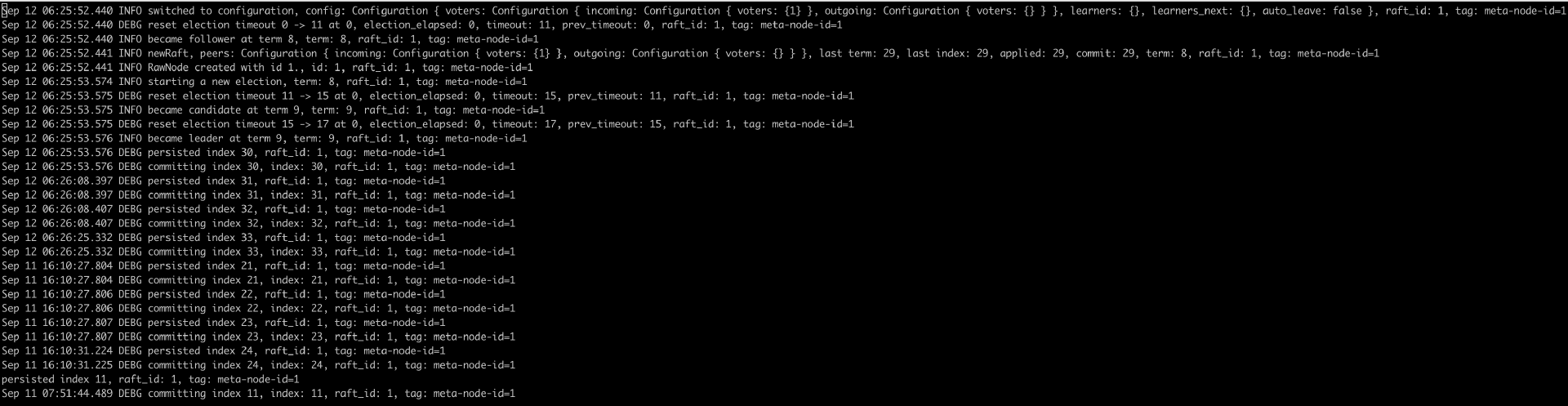
讲到这里你就会发现: Raft 集群的运行是依靠 Raft 状态机不断地向前驱动去生成不同类型的消息,从而完成不同的操作。
那接下来我们就来实现 Raft 状态机。开发 Raft 状态机的第一步是初始化 raft-rs 中的 RawNode 对象。
初始化 RawNode
在前面我们频繁提到 Raft Node 和 Raft 状态机这两个概念,现在又出现了 RawNode,我们先来看一下这三者的区别。
-
Raft Node:指 Raft 中的投票者节点,一般一个物理节点(或服务进程)就是一个 Raft Node。
-
RawNode:是 raft-rs 库的一个结构体,用于初始化一个投票者。
-
Raft 状态机:指服务进程中驱动 RawNode 状态运行的线程。一般情况下,一个 RawNode 对应一个 Raft 状态机,也就是一个线程。用于避免多个 RawNode 运行在同一个线程中相互影响。
了解完这几个概念,接下来就初始化 RawNode 对象。从实现上主要包含两步:
-
构建配置
-
创建 RawNode 对象
先来看构建配置,代码如下:
#![allow(unused)] fn main() { fn build_config(&self, apply_index: u64) -> Config { let conf = placement_center_conf(); Config { id: conf.node_id, election_tick: 10, heartbeat_tick: 3, max_size_per_msg: 1024 * 1024 * 1024, max_inflight_msgs: 256, applied: apply_index, ..Default::default() } } }
构建配置代码实现很简单,你需要重点关注 id 和 applied 这两个配置项。
-
id:指 RawNode 的唯一标识,用来区分不同的投票者。多个 RawNode 之间的 id 不能重复。
-
applied:表示当前 Raft Node 上持久化存储的最新的 commit index。因为进程会重启,所以当进程重启时,就需要从本地持久化的存储中,恢复当前 RawNode 的 commit index。(在这一步,你就看到前面持久化存储层的作用了)
接下来看一下如何创建 RawNode。
#![allow(unused)] fn main() { pub async fn new_node(&self) -> RawNode<RaftMachineStorage> { let cluster = self.placement_cluster.read().unwrap(); // 创建RawNode 的存储层,也就是 Raw 的Stroage Trait 的实现。 // 这里用了我们实现上一章实现的存储层 RaftMachineStorage let storage = RaftMachineStorage::new(self.raft_storage.clone()); // 构建 RawNode 的配置 let hs = storage.read_lock().hard_state(); let conf = self.build_config(hs.commit); // 初始化 Raft 的投票者列表 let mut cs = storage.read_lock().conf_state(); cs.voters = cluster.node_ids(); let _ = storage.write_lock().save_conf_state(cs); // raft-rs 库有自己的日志实现,也就是会打印 raft 运行日志到一个独立的文件 let logger = self.build_slog(); // 初始化一个 RawNode 实例 let node = RawNode::new(&conf, storage, &logger).unwrap(); return node; } }
上面这段代码的核心逻辑是,初始化存储层实现、初始化配置、初始化投票者列表、初始化日志、创建RawNode 实例。整体流程比较简单直观。需要注意的是,上面的代码中有这样一行:
#![allow(unused)] fn main() { cs.voters = cluster.node_ids() }
如果你对 Raft 协议理解得较多的话,就知道 Raft Node 之间需要知道对方的存在,才能进行投票选举,并将得票超过半数的 Raft Node 选举为 Leader。这行代码就是初始化配置当前总共有几个 Raft Node,让Node之间能够相互发现,从而选举出 Leader。
node_ids 方法的代码如下所示,返回的是所有投票者的节点 id 列表。
#![allow(unused)] fn main() { pub fn node_ids(&self) -> Vec<u64> { let mut voters = Vec::new(); for (id, _) in self.peers.iter() { voters.push(*id); } return voters; } }
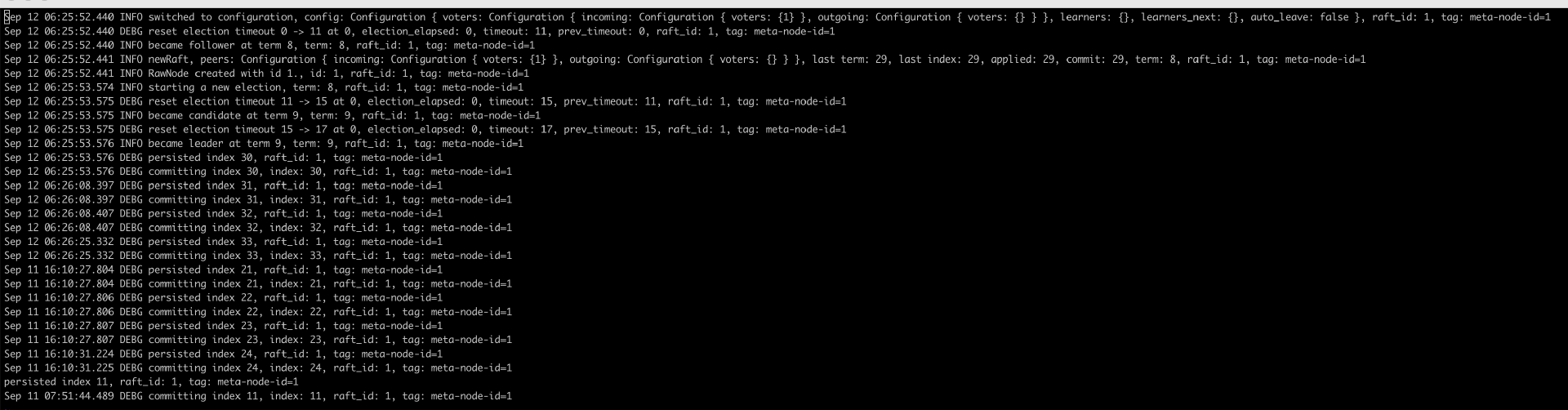
当然如果只有一个 RawNode,那么它会被自动选举为 Leader,运行日志如下:
初始化后 RawNode后,接下来我们来看状态机的具体逻辑实现。
从实现来看,状态机的代码由 驱动代码 和 逻辑代码 两部分组成。由于篇幅原因,我们这里只讲代码的主要实现逻辑,完整代码请看 Demo 示例中的 《machine.rs》。接下来先来看状态机驱动代码。
状态机驱动代码
状态机驱动代码是指驱动 Raft 状态机向前运行的主流程代码。先来看代码:
#![allow(unused)] fn main() { pub async fn run(&mut self) { // 初始化 RawNode 实例 let mut raft_node: RawNode<RaftRocksDBStorage> = self.new_node().await; // 定义每隔 100ms 向前驱动一次状态机 let heartbeat = Duration::from_millis(100); let mut now = Instant::now(); // 使用 loop 循环一直向后驱动 Raft 状态机 loop { // 接收进程停止的信号,优雅退出进程 match self.stop_recv.try_recv() { Ok(val) => { if val { info!("{}", "Raft Node Process services stop."); break; } } Err(_) => {} } // 通过 timeout 配合 receiver 实现每 100ms 向前驱动状态机 match timeout(heartbeat, self.receiver.recv()).await { // 接收其它Raft Node 上的 Raft 状态机生成的Message,进行处理 // 比如发起投票、心跳、心跳返回等等 Ok(Some(RaftMessage::Raft { message, chan })) => { match raft_node.step(message) { Ok(_) => match chan.send(RaftResponseMesage::Success) { Ok(_) => {} Err(_) => { error!("{}","commit entry Fails to return data to chan. chan may have been closed"); } }, Err(e) => { error!("{}", e); } } } // 接收写入到 Raft 状态机的用户消息,并进行处理 Ok(Some(RaftMessage::Propose { data, chan })) => { let seq = self .seqnum .fetch_add(1, std::sync::atomic::Ordering::Relaxed); match raft_node.propose(serialize(&seq).unwrap(), data) { Ok(_) => { self.resp_channel.insert(seq, chan); } Err(e) => { error!("{}", e); } } } Ok(None) => continue, Err(_) => {} } let elapsed = now.elapsed(); // 每隔一段时间(称为一个 tick),调用 RawNode::tick 方法使 Raft 的逻辑时钟前进一步。 if elapsed >= heartbeat { raft_node.tick(); now = Instant::now(); } // 在每个驱动周期(收到业务消息或者每 100ms),尝试去处理 Raft Message self.on_ready(&mut raft_node).await; } } }
上面这段代码主要逻辑已经写在注释里面了。我们总结一下核心流程。
-
通过 loop + timeout + self.receiver.recv 来驱动 Raft 状态机向前运行。即如果收到需要 Raft 状态机处理的消息,就向前驱动一步,处理这部分消息。如果没有需要 Raft 状态机处理的消息,则每 100ms 向前驱动一步。
-
Raft 状态机会接收 其他 Raft Node 运行状态消息 和 用户消息 进行处理,这两个消息是网络层 gRPC Server 通过 Tokio Channel 传递过来的。当状态机接收到消息数据后,即刻进行处理。
-
通过 self.stop_recv.try_recv() 来优雅停止状态机。
-
每 100ms 将 Raft 状态机的逻辑时钟向前驱动一步。
-
Raft 每驱动一次,则会调用 self.on_ready 尝试处理本次驱动是否有需要处理的消息。
可以看到,上面的 run 方法是一个 loop 的循环,为了不阻塞主线程,需要将它放在一个独立的子任务中运行。从代码实现上来看,如下所示直接通过 tokio::spawn 启动一个 tokio task 运行即可。
#![allow(unused)] fn main() { let mut raft: RaftMachine = RaftMachine::new( self.placement_cache.clone(), data_route, peer_message_send, raft_message_recv, stop_recv, self.raft_machine_storage.clone(), ); tokio::spawn(async move { raft.run().await; }); }
讲到这里,其实 Raft 状态机主体框架已经开发完成了。我们根据前面状态机运行原理的两张图来总结一下整体的运行流程: 进程启动,启动 gRPC Server,启动状态机,状态机会自己运行,找到 Leader 或发起 Leaer 选举。根据自身的角色生成不同的消息,通过Tokio Channel 发送给网络层,并通过网络层发送给其他节点,从而和其他 Raft 节点互动,进而完成集群的组建。
你应该会注意到,run 方法中我们通过一个 on_ready 方法来处理每一批次的 Raft 消息,也就是说在 on_ready 方法里面会完成每一批次 Raft 消息的逻辑处理。所以可以将它称为状态机逻辑代码。接下来来看一下它的实现。
状态机逻辑代码
直接来看代码:
#![allow(unused)] fn main() { async fn on_ready(&mut self, raft_node: &mut RawNode<RaftRocksDBStorage>) { // 检查 raft 状态机是否已经准备好 // 是的话,向下运行 // 否的话,表示这批次没有需要处理的消息 if !raft_node.has_ready() { return; } // 获取到这一批次需要处理的数据 let mut ready = raft_node.ready(); // 判断消息是否为空 // 如果不为空,表示 有Raft Message需要发给其他Raft Node, // 则需要把 Raft 消息通过我们构建的网络层发送给其他的 Raft Node if !ready.messages().is_empty() { // mark 1 self.send_message(ready.take_messages()).await; } // 判断这次向前驱动,是否有快照数据需要恢复 // 如果有快照数据,则需要恢复快照数据,即将快照数据持久化存储到存储层 if *ready.snapshot() != Snapshot::default() { // mark 2 let s = ready.snapshot().clone(); info!( "save snapshot,term:{},index:{}", s.get_metadata().get_term(), s.get_metadata().get_index() ); raft_node.mut_store().apply_snapshot(s).unwrap(); } // 持久化存储 Raft 日志 // 即判断是否有 Entry 需要保存 // 如果有 Entry 需要保存,则需要将 Entry 持久化保存 if !ready.entries().is_empty() { // // mark 3 let entries = ready.entries(); raft_node.mut_store().append(entries).unwrap(); } // 处理已经能够被 Apply 的消息 // 因为 Raft 存储是两阶段的,Leader 接收到数据后,需要被多个节点都处理成功后才能算处理成功 // 所以 这一步是 apply 已经被多个节点处理成功的数据 // mark 4 self.handle_committed_entries(raft_node, ready.take_committed_entries()); // 如果有 HardState 数据更新,则更新本地持久化存储的 HardState 数据 if let Some(hs) = ready.hs() { // mark 5 debug!("save hardState!!!,len:{:?}", hs); raft_node.mut_store().set_hard_state(hs.clone()).unwrap(); } // 判断是否有persisted messages 消息 // 有的话就发送给其他 Raft 节点 if !ready.persisted_messages().is_empty() { // mark 6 self.send_message(ready.take_persisted_messages()).await; } // 在确保一个 Ready 中的所有进度被正确处理完成之后,调用 RawNode::advance 接口。 let mut light_rd = raft_node.advance(ready); // 更新 HardState 中的 commit inde 信息 if let Some(commit) = light_rd.commit_index() { // mark 7 raft_node.mut_store().set_hard_state_comit(commit).unwrap(); } // mark 8 同上 self.send_message(light_rd.take_messages()).await; // mark 9 同上 self.handle_committed_entries(raft_node, light_rd.take_committed_entries()); raft_node.advance_apply(); } }
上面代码的主要逻辑已经加在注释中了,就不再重复。我们还是来总结下核心逻辑。
-
on_ready 代码把我们之前实现的网络层和存储层的逻辑都集成进来了。也就是代码中标记了 mark 1~9 位置的代码。比如当状态机生成需要发送给其他节点的消息,就调用send_message 方法将消息发给其他节点。如果需要持久化存储消息,就调用RaftMachineStorage 中对应的方法完成存储。
-
你可以认为 on_ready 代码逻辑步骤是固定的,假设你要实现自己的 Raft 状态机,那么直接把这段代码复制下来,把代码中标记了 mark 1~9 位置的代码变为自己的实现即可。
-
总结一下标记了 mark 的代码块的作用:
-
mark 1/6/8:如果有需要发送给其他 Raft Node 的消息,则通过 send_message 方法,调用 gRPC 模块,将消息发送给其他节点。
-
mark 2:恢复快照,将快照中的数据持久化到本地的 RocksDB 中。
-
mark 3:持久化存储 Raft 日志,将数据持久化存储到 RocksDB 中。
-
mark 4/9:处理业务数据,这一点我们在下节课会细讲。
-
mark 5:持久化保存 HardState 数据到 RocksDB 中。
-
mark 7:持久化保存最新的 commit index 到 RocksDB 中。
-
当完成上面的工作后,Raft 状态机也全部完成了。 同时基于 Raft 协议的分布式集群也构建完成了。讲到这里,虽然我们已经完成了每个部分的开发,但是你是不是对整个集群的运行流程还是点模糊,没有一个整体的概念?
是的,这很正常,所以接下来我们从宏观的角度来总结一下我们基于 Raft 协议构建的集群的运行逻辑和代码关系。
集群运行宏观总结
回顾一下,我们总共完成了三个事情:
-
基于 RocksDB 的 Raft Log 存储层的开发。
-
基于 gRPC 的 Raft Node 网络层的开发。
-
基于 Tokio 的 Raft 状态机的开发。
这三个工作都是指单个Raft Node 维度的实现。而从集群的角度看,就是多个Raft Node 就可以组成集群。因此只要我们启动多个 Raft Node,它就会自动组建成集群。那它是怎么组建集群的呢? 来看下图:
组建集群的代码运行逻辑如下:
-
单个 Raft Node 启动,会尝试从本地 RocksDB 的数据目录恢复数据,如果 RocksDB 目录不存在,则会创建一个新的数据目录,否则就恢复Raft Node 的状态数据。主要是通过 Storate Trait 的 initial_state 方法读取 HardState 和 ConfState 数据。
-
同时 Raft Node 会启动网络层 gRPC Server 和 Raft 状态机。
-
Raft 状态机启动后,会判断是否有 Leader,有的话就获取 Leader 信息,没有的话重新发起选举。这些动作是由 raft-rs 库的 RawNode 实现的。
-
不管是获取 Leader 还是发起选举,都是由 RawNode 发起的。由 RawNode 生成消息,然后通过网络层跟其他 Raft Node 交互。
-
选举出 Leader 后,Leader 会向 Follower 发送心跳信息,如果 Follower 没及时收到心跳,则会重新发起选举。
每个节点启动都会执行上面这些逻辑。比如单节点启动,就会将自己选为 Leader,如果有新节点启动,则会获取当前集群的 Leader 或者发起选举。以此类推,多个 Raft Node 就会组建成集群了。
在集群构建完成后,你可能有个疑问: 如果你写一条数据,这个数据最终是如何完成分布式存储的?这个问题我们留到下节课,我们会基于当前构建的 Raft 集群来完成数据的分布式多副本可靠存储。
总结
tips:每节课的代码都能在项目 https://github.com/robustmq/robustmq-geek 中找到源码,有兴趣的同学可以下载源码来看。
到了这节课,基于 Raft 协议构建分布式集群就完成了。可以看到,基于 raft-rs 库来构建集群,整个流程还是很繁杂的,要自己实现很多细节。
在这里我想说明的是,不论我们基于哪个库来实现集群,甚至自己实现一个一致性协议来构建集群,它的底层原理都是一样的,是通用的。因此在我看来,从学习的角度,选择哪个库来实现的区别不大,重要的是你能深刻理解一致性协议的细节。
客观来讲,至今为止我们也只是实现了最简单的集群。里面还有很多细节需要优化,比如异步快照构建、高性能的快照同步和恢复、Raft 日志存 RocksDB 写放大问题、Raft 节点之间高性能的消息同步等等。所以欢迎你参与我的项目 https://github.com/robustmq/robustmq,来了解更多的细节。
在实际的实现中,也会建议你可以考虑基于 openraft 库来实现自己的集群,因为 openraft 库是一个完整的实现,对于使用者来说开发理解成本会更低一些。选型的考虑过程在 第 7 课 讲完了,你可以根据自己的实际需要来选择合适的类库。
不过基于 raft-rs 库实现构建集群有一个好处是, 会让你对 Raft 的原理及实现有更深的理解。当你把这三节课的内容理解透,想必你对 Raft 协议的理解会深入很多,后续不管使用哪个 Raft 库,应该都更得心应手。
思考题
这里是本节课推荐的相关 issue 的任务列表,请点击查看 《Good First Issue》。另外欢迎给我的项目 https://github.com/robustmq/robustmq 点个 Star 啊!