基于Raft协议构建分布式集群(一)
本课程为精品小课,不标配音频
你好,我是文强。
前面我们写完了单机存储层,为了提升数据的可靠性,现在我们需要将单点存储升级为分布式存储。从技术上看,实现分布式存储需要两步:
-
构建基于某个一致性协议的分布式集群。
-
在构建完成的分布式集群上存储数据。
所以接下来,我会在 7、8、9 三节课讲如何基于 Raft 协议构建多节点组成的分布式集群,在第 10 节课会讲如何基于构建完成的分布式集群完成数据的分布式多副本存储。
Tips:接下来我们主要从代码实现的角度讲解如何基于 Raft 协议构建集群。由于篇幅和 Raft 协议本身的复杂性,无法讲得特别细致,因此建议你去复习一下 Raft 协议的内容。如有更多问题,欢迎在留言区或者进交流群与我讨论。
如何选择合适的分布式一致性协议,这个理论基础我在之前的课程《深入拆解消息队列 47 讲》的 《17|可靠性:分布式集群的数据一致性都有哪些实现方案?》 中已经系统讲过了,这里不再重复。
从技术上来看,业界有 Raft、Paxos、Zab、ISR 等一致性协议的实现。虽然各种协议的理论和具体实现都不一样,但是从原理上看它们都具备在生产环境中使用的条件。那么我们为什么选择 Raft 协议,不选择其他的协议呢?
为什么选择 Raft 协议
我们最终选择 Raft 协议主要有三点考虑:
-
如果有现成的合适的一致性协议,我们就不考虑从头实现一个一致性协议。
-
从功能上看,Raft 协议和其他一致性协议都满足 Placement Center 功能定义上的需求。
-
Rust 中有比较成熟的 Raft 协议库,并且这些库已经在成熟项目中使用,其他协议不满足这个条件。
这个思考过程还可以展开一下,希望能给你带来一些参考价值。
首先考虑的一个因素是, 选择的协议必须满足我们的业务需求。从 Placement Center 所提供的功能、数据量、QPS 来看,它的业务特点主要是存储元数据,不会有非常大的数据量,但是需要数据的高可靠,不能丢数据。所以从功能上来看,基本所有的一致性协议都可以满足我们的需求。
另外因为一致性协议本身的复杂性,从工程实现角度来看,从头写一个一致性协议非常难,工作量大,周期也长,所以大多数情况下是没必要的。因此选择的一个重要标准就是, 使用的语言有没有现成的一致性协议的实现。
从 crates.io 上看有几个成熟的 Raft 库实现,比如 openraft、raft-rs 等,但其他一致性协议,比如 Paxos,却没有比较成熟的实现。这个现象从技术上看也符合预期,因为 Paxos 的工程化落地就非常难。Raft 本身就是为了简化 Paxos 的工程实现而设计出来的。
然后考虑的第三个因素是 项目库的成熟度如何,是否具备工业化使用基础。Rust 中的 Raft 实现主要有 openraft 和 raft-rs 两个库,最后我们选择了 raft-rs 库,主要是因为:
-
raft-rs 是 TIDB 开源的库,已经经过了 TiKV 这个成熟项目的验证。
-
它只实现了 Raft 协议中的共识算法部分,其余部分自己实现,比如网络、存储层。从长期的性能、调优的角度来看,自主实现得越多,可控性越高,那么优化也就越好做。
接下来我们来简单了解一下 raft-rs 这个库。了解它主要有什么,如果要使用它来实现基于 Raft 协议的分布式集群总共要做哪些事情。
raft-rs 库的使用概述
在此之前,我建议你先复习一下 Raft 协议。这里给你推荐一个 Raft 协议的动图原理展示,如果你能够理解这个动图所表达的意思,说明你已经基本掌握了 Raft 协议。
下面来看 Raft 论文中的一张经典架构图。
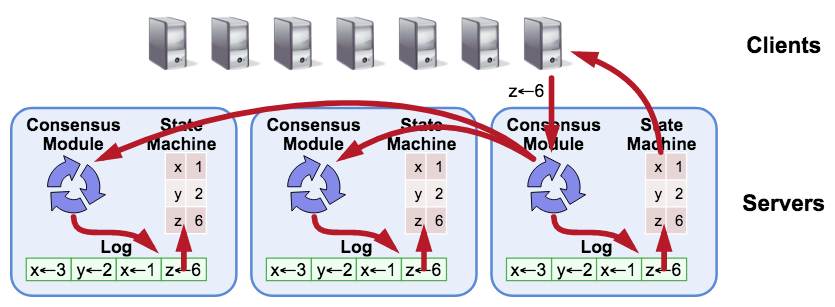
结合 Raft 原理可以知道: Raft 是通过日志来复制状态机,也就是说如果我们能保证所有机器上的日志顺序是一致的,那么按顺序执行所有日志后,则每个节点上的状态机就能达到一致的状态。
所以从代码实现来看,一个完整的Raft模型包含 共识模块、 Log、 状态机、 传输层 四个部分。
-
共识模块: 是指 Raft 核心共识算法部分。它负责完成发起选举、选举过程、心跳保持、检测心跳超时、重新发起选举等工作,也就是我们最熟悉的 Raft 算法部分。raft-rs 库就是完成这部分工作的,但也只是完成了这部分工作。
-
状态机: 是指驱动 Raft 共识模块工作的线程。它会不断检测共识模块是否需要执行某些操作,比如选举、心跳。如果需要就根据共识模块的运行结果执行对应的操作,比如给其他 Raft Node 发送消息,持久化保存数据等等。
-
Log(存储层): 是指存储 Raft 状态机运行过程中产生的 Log(也叫做 Entry)的模块,比如选举出一个新的 Leader,就会生成一个新的 Entry 需要持久化存储。
-
传输层:是指用于多个 Raft 节点之间通信的网络层。比如 Follower 节点向其他节点发起选举、Leader 向 Follower 发送心跳等等行为,都需要通过传输层将 Raft Message 发送给其他节点。
你现在可能对这四个部分有点模糊,不太理解。没关系,这很正常,你只要先记住有这四个部分,以及它们大致的作用即可。接下来我们还会详细讲解。
因此从开发的角度,基于 raft-rs 库来构建集群就有四个主要工作:
-
构建存储层: 即实现用于持久化存储 Raft Log 数据的存储层。在本次实现中,我们是基于 RocksDB 来实现的。
-
构建网络层:即实现用于在多个 Raft 节点之间进行通信的模块。在本次实现中,我们是基于 gRPC 来实现的。
-
构建单节点 Raft 状态机:比如分发数据、检测心跳、切换Leader等等。
-
整合状态机、存储层、网络层 : 构建成一个完整的 Raft 集群。
首先我们来看存储层的实现。
Tips:建议你把第 7、8、9 节课当作一个整体来看,如果在前两讲遇到不理解的地方可以先跳过,等看完三节课的全部内容再回头来看,就比较好理解了。
Raft Log 和 Storage Trait
我们已知,存储层的作用是用来持久化存储 Raft 运行过程中产生的 Log 数据。那什么是 Raft Log 呢?来看下面这张图:
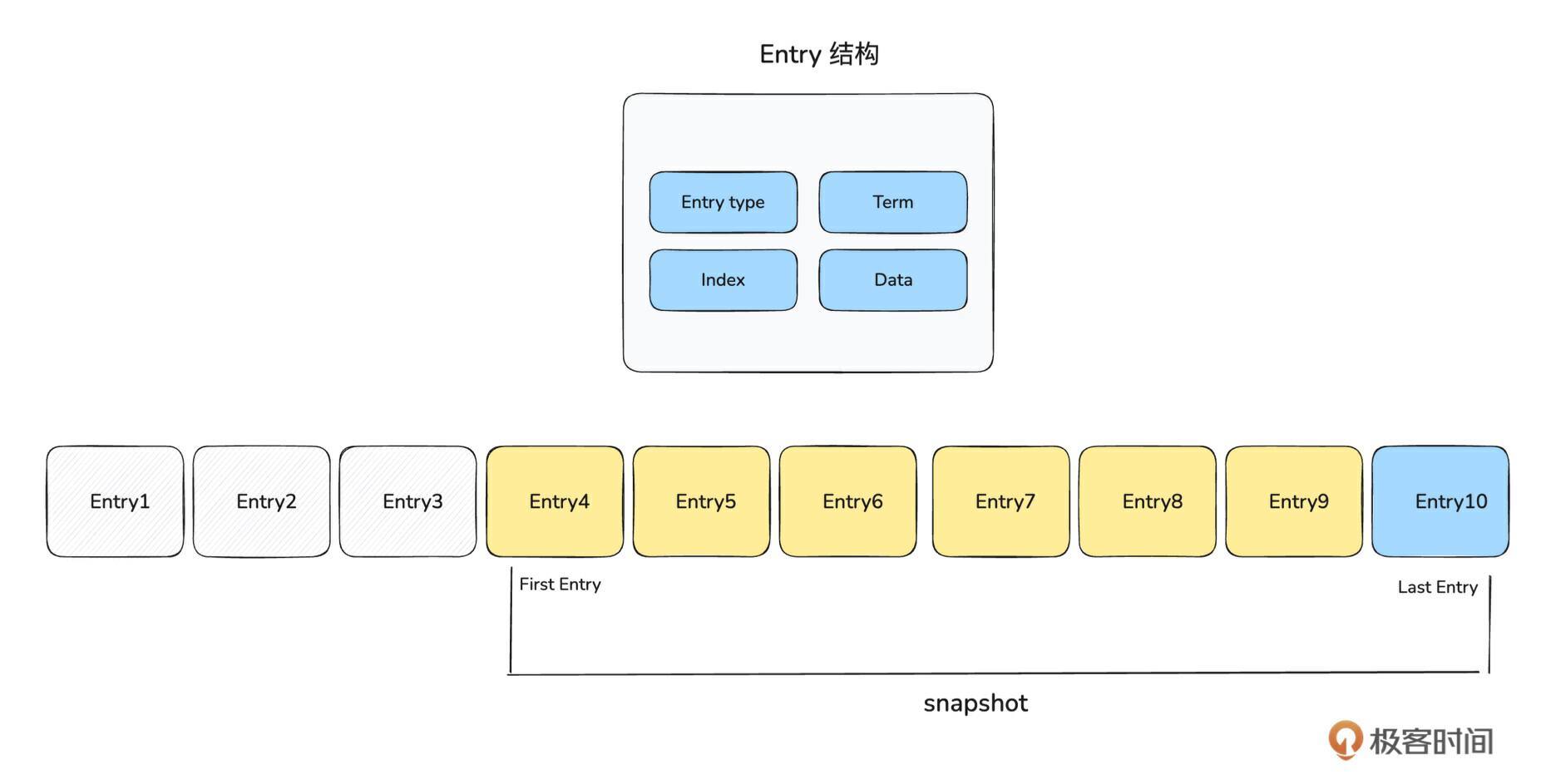
结合上图内容和 Raft 协议算法,我们可以知道, Raft Log 本质上是一系列 Entry 组成的顺序存储的日志。Entry 表示一个 Raft Log,为了节省存储空间和加快快照的生成速度,一些没用的 Raft Log 需要清理删除。所以 First Entry 是指至今还保存的最早的那条 Entry,Last Entry 是指最新的那条 Entry。快照一般指当前所有有效的 Entry 的集合。
因此,Raft Log 的核心其实是 Entry。 每一个 Entry 由 Entry Type、 Index、 Term、 Data 四部分组成。
- Entry Type:表示该 Entry 包含什么类型的数据,如下枚举类所示,有普通数据和配置变更数据两种类型。
#![allow(unused)] fn main() { pub enum EntryType { EntryNormal = 0, EntryConfChange = 1, EntryConfChangeV2 = 2, } }
-
Index:指这个 Entry 在顺序存储的日志中的偏移量。
-
Term:是 Raft 协议中的概念,用于保证 Raft Log 的一致性和顺序性。Term 从 0 开始,如果 Leader 切换一次,Term 就会 +1, 每一个 Entry 都有属于自己的 Term。
-
Data:是 Raft Log 的具体内容,不同 Entry Type 的内容是不一样。
讲到这里,我们大概知道了 Raft Log 的存储结构。接下来我们来理解一下 raft-rs 库中提供的一个名为 Storage 的 Trait。
它定义了 Raft 状态机在运行过程中会读写哪些数据。因此只要了解这个 Trait,也就理解了 Raft 运行过程中会操作哪些数据了。先来看 Storage Trait 的定义:
#![allow(unused)] fn main() { pub trait Storage { fn initial_state(&self) -> Result<RaftState>; fn entries( &self, low: u64, high: u64, max_size: impl Into<Option<u64>>, context: GetEntriesContext, ) -> Result<Vec<Entry>>; fn term(&self, idx: u64) -> Result<u64>; fn first_index(&self) -> Result<u64>; fn last_index(&self) -> Result<u64>; fn snapshot(&self, request_index: u64, to: u64) -> Result<Snapshot>; } }
从上面代码可以知道 Storage Trait 提供了 initial_state、 entries、 term、 first_index、 last_index、 snapshot 等 6 个方法来读写 Raft 的运行数据。接下来我们结合前面这张图来理解一下每个方法的作用。
1. initial_state
读取节点,本地持久化存储 Raft 集群运行状态信息,状态信息由 HardState 和 ConfState 两部分组成。如下代码所示,状态信息主要包含 Raft 集群的 term、投票者、观察者、Leader、最新 commit index 等信息。
#![allow(unused)] fn main() { pub struct HardState { // 当前 Raft 最新的 term pub term: u64, // 选举出来的 Leader pub vote: u64, // 最新提交的索引 pub commit: u64, } pub struct ConfState { // 投票者列表 pub voters: ::std::vec::Vec<u64>, // 观察者列表 pub learners: ::std::vec::Vec<u64>, ...... } }
这个方法是一个读取操作,也就说这些状态信息是在另外一个流程持久化存储的。这个流程在后面讲 Raft 状态机的时候会讲到。
2. entries
给定 Index 一个范围,比如 low ~ high,从而获取这个范围内的所有 Entry。同样的,这也是一个读取操作,也就是说 Entry 会在另外一个流程写入。同样的,Entry 存储也是在 Raft 状态机部分会讲到。
3. term
给定一个日志的 Index,查看这个 Index 对应的 Entry 所对应的 term。
4. first_index
前面提到,没用的 Entry 会被清理。因此这个方法会返回最早未被清理掉的 Entry 对应的 Index。
5. last_index
获取最新的一条 Entry 所对应的 Index。
6. snapshot
返回当前 Raft Log 的快照数据。快照数据主要包含 当前还保留的所有 Entry 信息。快照是用于当 Follower 数据落后 Leader 太多时,帮助 Follower 恢复到最新数据状态的工具。
这里在实现上需要注意的是:因为快照数据一般很大,所以一般需要异步生成,如果同步生成,会卡住主线程的运行。
讲完了 Raft 的存储层要存储什么数据,接下来我们基于 RocksDB 来实现我们的 Storage:RaftRocksDBStorage。
基于 RocksDB 的 RaftRocksDBStorage
接下来,直接来看我们实现的 RaftRocksDBStorage 的主体代码。
#![allow(unused)] fn main() { impl Storage for RaftRocksDBStorage { fn initial_state(&self) -> RaftResult<RaftState> { let core = self.read_lock(); // 数据是通过 RocksDB 持久化存储 // 通过RaftMachineStorage 的raft_state方法从 RocksDB 中取出 return Ok(core.raft_state()); } fn entries( &self, low: u64, high: u64, _: impl Into<Option<u64>>, _: raft::GetEntriesContext, ) -> RaftResult<Vec<Entry>> { let core = self.read_lock(); // 判断 low index 是否在可用范围内 if low < core.first_index() { return Err(Error::Store(StorageError::Compacted)); } // 判断 high index 是否在可用范围内 if high > core.last_index() + 1 { panic!( "index out of bound (last: {}, high: {})", core.last_index() + 1, high ) } // 从 RocksDB 中依次取出这个范围内的 Index 对应的 Entry let mut entry_list: Vec<Entry> = Vec::new(); for idx in low..=high { let sret = core.entry_by_idx(idx); if sret == None { continue; } entry_list.push(sret.unwrap()); } return Ok(entry_list); } fn term(&self, idx: u64) -> RaftResult<u64> { let core = self.read_lock(); // 判断索引是否在内存中,是的话,直接返回即可。 if idx == core.snapshot_metadata.index { return Ok(core.snapshot_metadata.index); } // 判断 index 是否在可用范围内 if idx < core.first_index() { return Err(Error::Store(StorageError::Compacted)); } // 判断 index 是否在可用范围内 if idx > core.last_index() { return Err(Error::Store(StorageError::Unavailable)); } // 从 RocksDB 中获取 Index 对应的 Entry 的 Term if let Some(value) = core.entry_by_idx(idx) { return Ok(value.term); } // 默认返回当前快照的 Term return Ok(core.snapshot_metadata.term); } fn first_index(&self) -> RaftResult<u64> { let core = self.read_lock(); // 从RocksDB 中获取持久化存储的最早的 index let fi = core.first_index(); Ok(fi) } fn last_index(&self) -> RaftResult<u64> { let core = self.read_lock(); // 从RocksDB 中获取持久化存储的最新的 index let li = core.last_index(); Ok(li) } fn snapshot(&self, request_index: u64, to: u64) -> RaftResult<Snapshot> { info!("Node {} requests snapshot data", to); let mut core = self.write_lock(); // 如果当前快照没准备,就直接返回快照还在准备中的错误。同时触发异步执行构建快照 if core.trigger_snap_unavailable { return Err(Error::Store(StorageError::SnapshotTemporarilyUnavailable)); } else { // 如果快照已经存在,则直接返回快照信息。 let mut snap = core.snapshot(); if snap.get_metadata().index < request_index { snap.mut_metadata().index = request_index; } Ok(snap) } } } }
这段代码比较长,不过框架代码不复杂。主要逻辑都加了注释,这里只总结一下核心逻辑。
-
Raft 运行数据存储在 RocksDB 是通过 RaftMachineStorage 这个对象来完成的。RaftMachineStorage 的实现在下节课我们会详细讲。
-
impl Storage for RaftRocksDBStorage,这是一个 Trait 的语法,表示RaftRocksDBStorage 实现了 raft-rs 定义的 Storage Trait。 -
RaftRocksDBStorage 分别实现了 initial_state、 entries、 term、 first_index、 last_index、 snapshot 等 6 个方法。在这 6 个方法中基于 RaftMachineStorage 对象来完成数据的读写。
当我们完成了 RaftRocksDBStorage 后,怎么用呢?答案是 在创建 Raft Node 时会用到。在 raft-rs 库中,每一个 Raft Node 启动,就需要初始化为 RawNode 对象,此时就需要配置对应的存储层实现,代码如下:
#![allow(unused)] fn main() { // 初始化一个基于 RocksDB 的 Storage Trait 实现 let storage = RaftRocksDBStorage::new(self.raft_storage.clone()); // 初始化 Raft Node let node = RawNode::new(&conf, storage, &logger).unwrap(); }
完成了 RaftRocksDBStorage 开发,我们也就完成了存储层的主体框架的开发。下节课我们还会具体讲一下在 RaftMachineStorage 中如何基于 RocksDB 完成 Raft 运行数据的读写。
总结
tips:每节课的代码都能在项目 https://github.com/robustmq/robustmq-geek 中找到源码,有兴趣的同学可以下载源码来看。
构建分布式集群,关键是选择合适的一致性协议。主要有三点考虑:
-
选择的协议需要能满足我们业务上的需求。
-
使用的语言有没有适合的一致性协议的实现
-
项目库的成熟度如何,是否具备工业化使用基础。
只有当没有符合这些要求的基础库时,才考虑自行实现一致性协议。自行实现一致性协议有很多缺点,比如周期长,开发成本高,稳定性需要经过验证等等。
raft-rs 库只完成共识算法这部分的工作,其他包括 Log 存储、状态机、传输层都得我们自己来实现,所以它不是一个拿来即用的库。基于 raft-rs 库构建集群有一个好处是, 会让你对 Raft 的原理及实现有更深的理解。
raft-rs 中 Log 存储的核心是实现 Storage 的 Trait。Storage 提供了 initial_state、 entries、 term、 first_index、 last_index、 snapshot 等 6 个方法。只要实现这个 Trait,就算完成了存储层的开发。
思考题
这里是本节课推荐的相关 issue 的任务列表,请点击查看 《Good First Issue》。 另外欢迎给我的项目 https://github.com/robustmq/robustmq 点个 Star 啊!