做好准备:写一个基础软件需要掌握哪些Rust知识点?
本课程为精品小课,不标配音频
你好,我是文强。
从这节课开始,我们正式进入实践落地阶段。为了能让你更好地理解本课程后续的内容,我会先带你了解写一个分布式基础软件所需要用到的 Rust 关键知识点。
Tips:这节课只是起到一个“引导点明”的作用,不会详细展开讲解各个知识点。建议你先根据上节课推荐的资料把 Rust 的相关知识点都过一遍,再来看这节课的内容,会更好理解。
接下来,我整理了一个常用的 Rust 知识点集合(这个信息来源于多份学习资料,我只是做了一下总结)。你可以根据表格来看一下自己对 Rust 的掌握程度,然后查缺补漏。
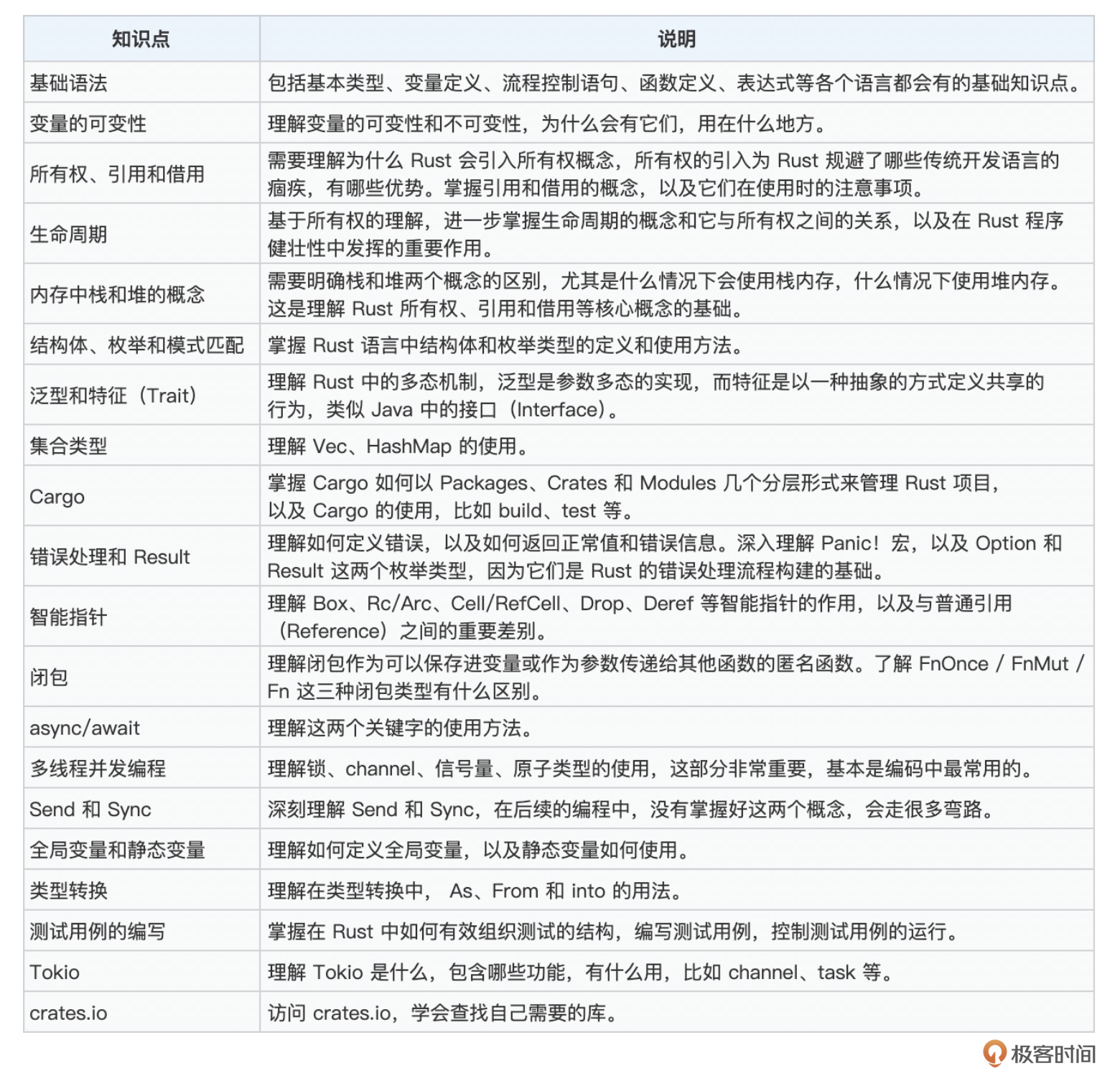
基于上面的表格,接下来我们重点讲一下在编码过程中最常用到且在理解上有一定挑战的几个知识点。
- 包管理工具:Cargo
- 生命周期和所有权
- 泛型和Trait
- 智能指针
- 并发编程和Tokio
- 测试用例
包管理工具:Cargo
无论是哪份学习资料,都会告诉你 Cargo 的重要性。在我看来 Cargo 是 Rust 的核心竞争力之一,是学习 Rust 必须完整掌握的知识点。想要学好 Cargo 看这份资料即可 《Cargo 使用指南》。
在 Cargo 里面重点关注以下三个命令,掌握后基本就入门了。
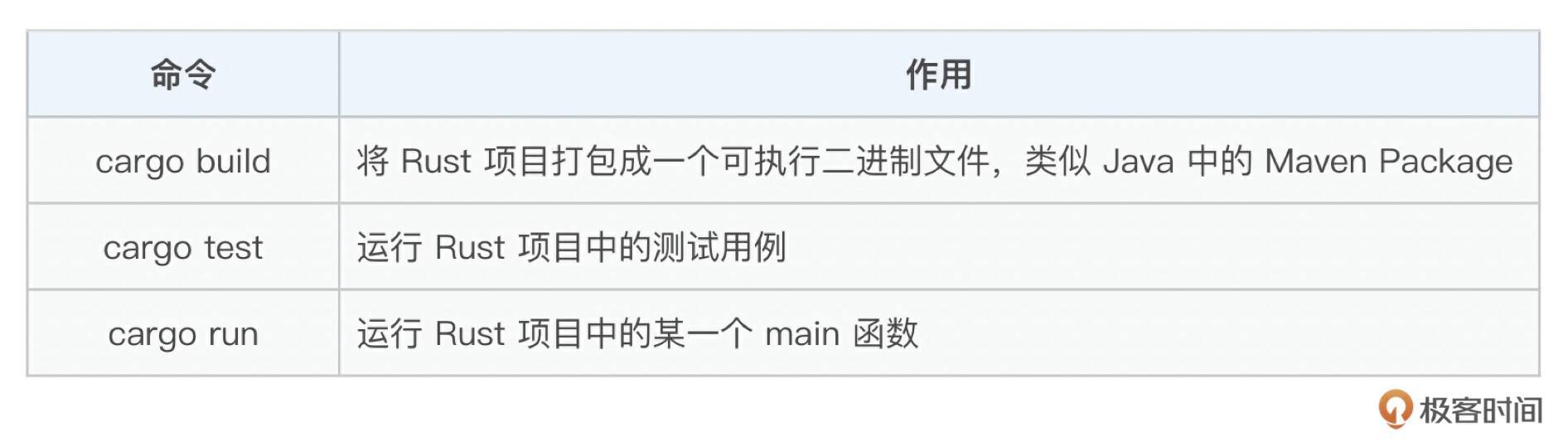
使用示例如下:
# 用 cargo build 根据 release 标准将项目打包成一个可执行的二进制文件
cargo build --release:
# 运行名为 mqtt-broker 的这个模块里面的测试用例
cargo test --package mqtt-broker
# 执行 cmd 包中名字为 placement-center 的 bin 的 main 函数,并给这个main函数传递conf参数
cargo run --package cmd --bin placement-center -- --conf=config/placement-center.toml
接下来通过真实项目中的两个 cargo.toml 来看一下如何编写 cargo 文件。
- 文件1
#![allow(unused)] fn main() { [workspace] members = [ "src/mqtt-broker" ] resolver = "2" [workspace.package] version = "0.0.1" edition = "2021" license = "Apache-2.0" [workspace.dependencies] serde = { version = "1.0", features = ["derive"] } # workspaces members mqtt-broker = { path = "src/mqtt-broker" } }
- 文件2
[package]
name = "cmd"
version.workspace = true
edition.workspace = true
license.workspace = true
default-run = "robustmq"
[[bin]]
name = "mqtt-server"
path = "src/mqtt-server/server.rs"
[dependencies]
serde.workspace = true
上面这两个文件,第一个文件是项目根目录的 cargo.toml,用处是导入依赖、组织管理子项目。第二个是子项目的cargo.toml,它是一个可执行的package,依赖父项目workspace的管理。文件内出现了以下四个知识点:
-
Cargo 中 Workspace 的使用。包括根项目中 workspace 的使用,子项目基于 workspace 特性管理依赖、版本信息等。
-
Cargo package 的定义(包括命名、版本、license)。
-
Cargo package bin 的用法。
这里就不详细展开说明每个细节了,如果你看不懂上面的语法,就完整看一下 《Cargo 使用指南》。如果你能看懂上面两个文件,说明你对 Cargo 的理解就差不多了。接下来就是在实际项目中使用 Cargo 的 build、run、test 命令看一下效果了。
接下来,来看看 Rust 的生命周期和所有权。
生命周期和所有权
可以说 Rust 这个语言的核心就是 生命周期 和 所有权 了。基本所有的语法点都是围绕这两个点来组织的。写好 Rust 代码的关键就是把这两个点理解透。这两个特性有关的知识点太多,我主要讲一下我们在实际编码中,主要会涉及的5个重点。
- 变量的可变性和不可变性。意思是 Rust 在定义变量的时候就需要指明它是否能够被修改,来看下面这个代码示例。
#![allow(unused)] fn main() { let x = 1; # 变量 x 不能被修改 let mut y = 1 # 变量 y 能被修改 }
上面代码中的 mut 关键字就是表示,这个变量能不能被修改,默认情况下变量是不能被修改的。所以在实际编码过程中,你会看到很多这样的代码写法:
#![allow(unused)] fn main() { pub struct ClientKeepAlive { stop_send: broadcast::Sender<bool>, } impl ClientKeepAlive { pub async fn start_heartbeat_check(&mut self) { loop { let mut stop_rx = self.stop_send.subscribe(); select! { val = stop_rx.recv() =>{ ...... } } } } } }
上面代码的核心是:&mut self 的使用,表明可以通过 mut self 来获取对象的可变属性,并修改它。而如果不需要修改,则改为 &self 即可。了解更多可以看 《变量绑定与解构》 这个资料。
Tips: 变量可变/不可变的特性是 Rust 安全性的一个重要来源。默认情况下变量都是不可变的,只有手动定义了mut 后,数据才能被修改。这样可以保证数据不会在某些地方被莫名修改,从而保证了数据的安全。
对于变量的可变性,再推荐一个在日常开发中会大量使用到的开发库 《DashMap》。它是HashMap 的替代品,我们在日常开发中会大量用 HashMap 来存储数据。此时就会大量用到类似 Arc<RwLock<HashMap<String,String>>> 的语法,这个用法很繁琐,性能也很低。此时可以使用DashMap来替代这个语法的使用。
- 变量的所有权和借用。Rust 语言能够没有GC(垃圾回收),其所有权特性的设计功不可没。关于 Rust 为什么可以没有 GC,你可以看 《所有权和借用》 和 《Drop 释放资源》 这两份资料来理解。
在实际编码中,所有权和借用特性主要体现在 clone() 和 & 两个语法的使用。来看个例子:
#![allow(unused)] fn main() { pub fn is_system_topic1(topic_name: String) -> bool { return true; } pub fn is_system_topic2(topic_name: &String) -> bool { return true; } let topic_name = "test".to_string(); is_system_topic1(topic_name.clone()); is_system_topic1(topic_name.clone()); is_system_topic2(&topic_name); is_system_topic2(&topic_name); }
上面定义了 is_system_topic1 和 is_system_topic2 两个方法,传递参数分别是 String和 String的引用。is_system_topic1 是把 topic_name 的所有权转移到函数中,is_system_topic2 传递了一个topic_name的引用到函数中,没有转移函数的所有权。
所以在编码中,你会大量用 clone 和 &(引用) 语法。那在编码中,什么时候用什么语法呢?来看它们在编码层面的主要区别。
-
传递引用:在多线程的环境下或者使用对象(struct)时,因为生命周期的限制,就会产生很复杂的问题,会大大增加编码的复杂度(这点会在后面的实践中展开讲,让你体会更深)。一些情况下可能还需要引入“生命周期约束”的特性。此时就需要用到所有权的转移,或者通过引入智能指针 Arc 来实现一个变量有多个所有者。
-
所有权转移:这个是最简单的用法,在每次参数传递时,都创建变量的副本,当数据较大时,会比较消耗性能。从语法上看会大量类似 xx.clone() 语法,不太友好。
所以在实践中: 建议默认优先使用引用,需要在多线程间传递数据的时候再使用clone()。
- 静态/全局变量:在实际编码中会大量用到静态和全局变量。而在生命周期和所有权的机制中,静态和全局变量的使用就变得比较复杂。相关资料可以看 《静态变量》、 《全局变量》 这两个文档。从学习的角度,只要会用就可以,底层的原理主要还是围绕生命周期来展开。来看个具体使用的例子:
#![allow(unused)] fn main() { 通过static 定义一个静态变量 static CONNECTION_ID_BUILD: AtomicU64 = AtomicU64::new(1); 通过 const 定义一个静态常量 pub const REQUEST_RESPONSE_PREFIX_NAME: &str = "/sys/request_response/"; }
再推荐一个定义静态变量经常会用到的库 《库 lazy_static》,因为静态变量是在编译期初始化的,因此无法使用函数调用进行赋值,而lazy_static允许我们在运行期初始化静态变量。
#![allow(unused)] fn main() { 通过lazy_static 动态定义静态变量 lazy_static! { static ref BROKER_PACKET_NUM: IntGaugeVec = register_int_gauge_vec!( "broker_packet_num", "broker packet num", &[ METRICS_KEY_MODULE_NAME, METRICS_KEY_PROTOCOL_NAME, METRICS_KEY_TYPE_NAME, ] ) } }
-
生命周期约束:生命周期约束是一个用得比较少,但是需要重点学习的特性。因为在某些情况下,只能用它来解决问题。详细资料可以看这个文档 《生命周期约束》。在实际编码中,生命周期约束主要用在标注引用的生命周期。 从实践的角度,建议能不用生命周期约束就不用,一般需要用到生命周期约束的地方都会有替换方案。
-
《生命周期》 和 《认识生命周期》:这两章可以放最后看,讲得比较晦涩,编码上用得少,不过加深对生命周期的理解有好处,建议你稍微看一下。
接下来,来看一下泛型和 Trait。在实际业务场景中,我们会频繁遇到需要使用泛型和Trait的场景。
泛型和 Trait
关于泛型和 Trait,你主要看这两个资料: 《泛型》 和 《特征 Trait》。看完这两篇基本就入门了。需要重点关注以下知识点:
-
泛型:泛型的定义,泛型的约束,泛型如何进行参数传递。
-
特征:特征定义,特征的实现,特征约束,特征对象,以及特征对象如何在多线程传递。
接下来通过两个例子,看一下在实际编码中,会怎么用这两个知识点。 只要你能完全理解这两段代码想表达的意思,那你对于泛型和 Trait 的了解基本就没问题了。
- 泛型
#![allow(unused)] fn main() { #[async_trait] pub trait StorageAdapter { // Streaming storage model: Append data in a Shard dimension, returning a unique self-incrementing ID for the Shard dimension async fn stream_write( &self, shard_name: String, data: Vec<Record>, ) -> Result<Vec<usize>, RobustMQError>; } pub struct MessageStorage<T> { storage_adapter: Arc<T>, } impl<T> MessageStorage<T> where T: StorageAdapter + Send + Sync + 'static, { pub fn new(storage_adapter: Arc<T>) -> Self { return MessageStorage { storage_adapter }; } // Save the data for the Topic dimension pub async fn append_topic_message( &self, topic_id: String, record: Vec<Record>, ) -> Result<Vec<usize>, RobustMQError> { let shard_name = topic_id; match self.storage_adapter.stream_write(shard_name, record).await { Ok(id) => { return Ok(id); } Err(e) => { return Err(e); } } } }
上面这段代码定义了名为 StorageAdapter 的 Trait,然后定义名为 MessageStorage 的对象,MessageStorage 包含一个变量 storage_adapter 是一个泛型。这段代码的重点是对变量storage_adapter的泛型约束:where T: StorageAdapter + Send + Sync + 'static。表示这是一个泛型,这个泛型需要满足 StorageAdapter + Send + Sync + 'static 四个约束。
然后在 MessageStorage 的方法中,append_topic_message 使用泛型约束StorageAdapter的方法 stream_write。
- Trait
#![allow(unused)] fn main() { #[async_trait] pub trait AuthStorageAdapter { async fn read_all_user(&self) -> Result<DashMap<String, MQTTUser>, RobustMQError>; } pub struct AuthDriver { driver: Arc<dyn AuthStorageAdapter + Send + 'static + Sync>, } impl AuthDriver { pub fn new(cache_manager: Arc<CacheManager>, client_poll: Arc<ClientPool>) -> AuthDriver { let driver = match build_driver() { Ok(driver) => driver, Err(e) => { panic!("{}", e.to_string()); } }; return AuthDriver { driver: driver, }; } pub async fn read_all_user(&self) -> Result<DashMap<String, MQTTUser>, RobustMQError> { return self.driver.read_all_user().await; } } }
上面这段代码在上节课就出现过,其定义了名为AuthStorageAdapter的Trait和名为AuthDriver的 Struct,通过build_driver方法构建Trait的不同实现,通过Arc<dyn AuthStorageAdapter + Send + 'static + Sync> 实现变量在不同线程间的传递。
接下来我们来看看Rust中的智能指针。
智能指针
只要写 Rust 代码,智能指针基本就是最常用的特性之一,你如果没用到,那就说明你的项目不是一个真正的生产项目。要了解智能指针的详细信息,看这个资料 《智能指针》 即可。
Rust 中包含了丰富的智能指针,包括 Box、Rc/Arc、Cell/RefCell、Drop、Deref 等等。在实际编码中,我们最常用的是 Box、Rc/Arc、Cell/RefCell 三类,来看下它们各自的作用。
- Box
智能指针 Box 的核心功能是允许 将一个值分配到堆上,然后返回一个指针指向堆上的数据。从实际作用上来看,主要有以下3个使用场景:
-
将数据分配在堆上,比如在数据较大时,不想在转移所有权时进行数据拷贝。
-
类型的长度在编译期无法确定,但是在变量定义时又需要知道类型的长度时。
-
特征对象,用于说明对象实现了一个特征,而不是某个特定的类型。
上面第 1 点,直接将数据固定在堆上听起来很抽象,有啥用呢?举个例子。
在消息队列中,服务端 Server 需要大量接收客户端数据进行处理和保存。当数据很大时(比如 10MB),在数据转移所有权过程中,需要大量拷贝数据,此时数据太大,拷贝就需要消耗大量性能。
正常情况下,我们可以通过下面的结构体 RequestPackage 来传递数据,客户端的数据放在 packet 属性里面。
#![allow(unused)] fn main() { #[derive(Clone, Debug)] pub struct RequestPackage { pub connection_id: u64, pub addr: SocketAddr, pub packet: MQTTPacket, } }
如果 packet 太大,则会严重影响性能。此时可以把代码改为:
#![allow(unused)] fn main() { #[derive(Clone, Debug)] pub struct RequestPackage { pub connection_id: u64, pub addr: SocketAddr, pub packet: Box<MQTTPacket>, } }
改完后,packet 只是一个Box指针,不包含实际的数据体,所以在转移所有权拷贝数据过程中,拷贝的是引用指针数据,此时就可以避免在转移所有权过程中因数据太大而带来的性能问题。
2和3属于一个类型,属于 Box 的用法,本质上来看,也是将数据固定在堆上,返回一个引用。这个资料可以参考 《特征对象》。
- Rc/Arc
解决Rust中一个值在同一时刻只能有一个所有者的问题,即 允许一个值在同一时刻拥有多个所有者。如果你对 Rust 的所有权机制有足够了解,则很容易理解这句话的意思。如果不理解,可以看一下前面提到的《生命周期和所有权》部分。
从实际编码中,Rc 用得相对比较少,基本用的都是 Arc。因为 Rc 用于单线程,Arc 用于多线程。而在实际业务中,基本都是多线程编程。所以你需要重点了解 Arc 的用法,主要参考这份资料 《Rc 与 Arc 实现 1vN 所有权机制》。
下面来看一段 Arc 经典使用案例的代码。
#![allow(unused)] fn main() { pub struct MqttBroker { subscribe_manager: Arc<SubscribeManager>, connection_manager: Arc<ConnectionManager>, } impl MqttBroker { pub fn new( client_poll: Arc<ClientPool>, cache_manager: Arc<CacheManager>, ) -> Self { let subscribe_manager = Arc::new(SubscribeManager::new( cache_manager.clone(), client_poll.clone(), )); let connection_manager = Arc::new(ConnectionManager::new(cache_manager.clone())); return MqttBroker { subscribe_manager, connection_manager, }; } } }
这段代码的意思是,我们定义两个 subscribe_manager 和 connection_manager 分别来管理消息队列的订阅和连接数据。在实际场景中,这两个数据都需要在不同的线程中被操作(比如读取和写入)。此时如果不用智能指针 Arc,则 SubscribeManager 和 ConnectionManager 这两个 struct 是不能在多线程共享的。
简单来说就是: 如果一个数据要在多线程间共享,就必须使用 Arc。
- Cell/RefCell
通过学习所有权的部分,我们知道在 Rust 的定义中: 一个变量同时只能拥有一个可变引用或多个不可变引用,不能既拥有一个可变引用,又拥有多个不可变应用。在实际编码中,这个语法会给我们带来很大的限制,导致我们无法实现某些功能或大大增加实现成本。
Tips:提醒一下,不要一开始就用 Rust 去写 LeeCode 的数据结构算法,会写到怀疑人生。其中一个很大原因就是上面这个限制。
所以 Rust 提供了智能指针 Cell/RefCell 来绕过这个限制,即: 通过 Cell/RefCell 可以在拥有不可变引用的同时修改目标数据。简单来说就是, 变量可以在拥有不可变引用的同时拥有可变引用。
在看到这个语法时,我的第一反应是,这不是绕过了 Rust 的安全机制吗?一个变量可以同时读和写,会降低 Rust 的安全性吧。如果你也这样想,就表示你对 Rust 的所有权和安全性的理解是不错的。
是的,就是会有这个问题。那为什么还有这个语法呢?
主要原因是,编译器不可能做到尽善尽美,太死的限制会导致我们编码遇到很大的问题(在我看来,限制太多是导致 Rust 学习曲线陡峭的主要原因之一)。而当你对自己代码很有信心时,你就可以通过 Cell 和 RefCell 来绕过所有权的限制。所以 用这个语法后你需要自己保证数据的安全性。
因此这个语法在实际业务类编码当中用得比较少,反而在一些基础库中是一个常见用法。在我们要实现某些很基础功能的时候,你应该就会用到它。对它有兴趣,你可以看 《Cell 与 RefCell 内部可变性》,再去看看这个库 《DashMap》 的源码。
接下来我们来看看并发编程和 Tokio。
异步编程和 Tokio
在任何语言中,并发编程都是语言的核心,在 Rust 中也是一样的。从学习资料的角度,建议你先看 《async/await 异步编程》,然后再看这两个资料 《Tokio 官网》 和 《Rust 异步编程和 Tokio 框架》,基本就对 Rust 异步编程有个大概的了解了。这三份资料大部分在讲异步编程的底层原理,目的是帮助你更好地理解 Rust 异步编程,这部分反复看到能理解就可以。
从实际编码的角度,使用方式很简单,主要就是对 async、await、tokio 的使用。从功能上看,这三者的关系是: async 定义异步代码块,然后在 Tokio(Runtime)里面调用代码块的 .await 方法,运行这个异步任务。
接下来来看一段实际的业务代码。
#![allow(unused)] fn main() { let runtime = create_runtime( "storage-engine-server-runtime", conf.system.runtime_worker_threads, ); pub async fn report_heartbeat(client_poll: Arc<ClientPool>, stop_send: broadcast::Sender<bool>) { loop { let mut stop_recv = stop_send.subscribe(); select! { val = stop_recv.recv() =>{ match val{ Ok(flag) => { if flag { debug(format!("Heartbeat reporting thread exited successfully")); break; } } Err(_) => {} } } _ = report(client_poll.clone()) => { } } } } runtime.spawn(async move { report_heartbeat(client_poll, stop_send).await; }); }
在上面的代码中:
-
通过 create_runtime 创建一个 Tokio Runtime。
-
通过 async 定义一个名为 report_heartbeat 的异步运行的函数。这个函数的功能是定时上报心跳。
-
将report_heartbeat函数放在 Runtime 里面运行,Runtime 里面再通过.await 方法驱动异步任务运行。
这段代码是经典的Rust 异步编程的实现,其他的实现基本都是这段代码的变种。 在实际编码中,你还需要重点理解一下 Rust 闭包的用法,经常会用到。具体可以看这个资料 《闭包 Closure》。
在上面的例子中,异步任务是运行在 Tokio Runtime 中的。接下来通过一张图,来理解一下 Tokio 是什么,以及 Rust 异步编程(async/await)和 Tokio 的关系。
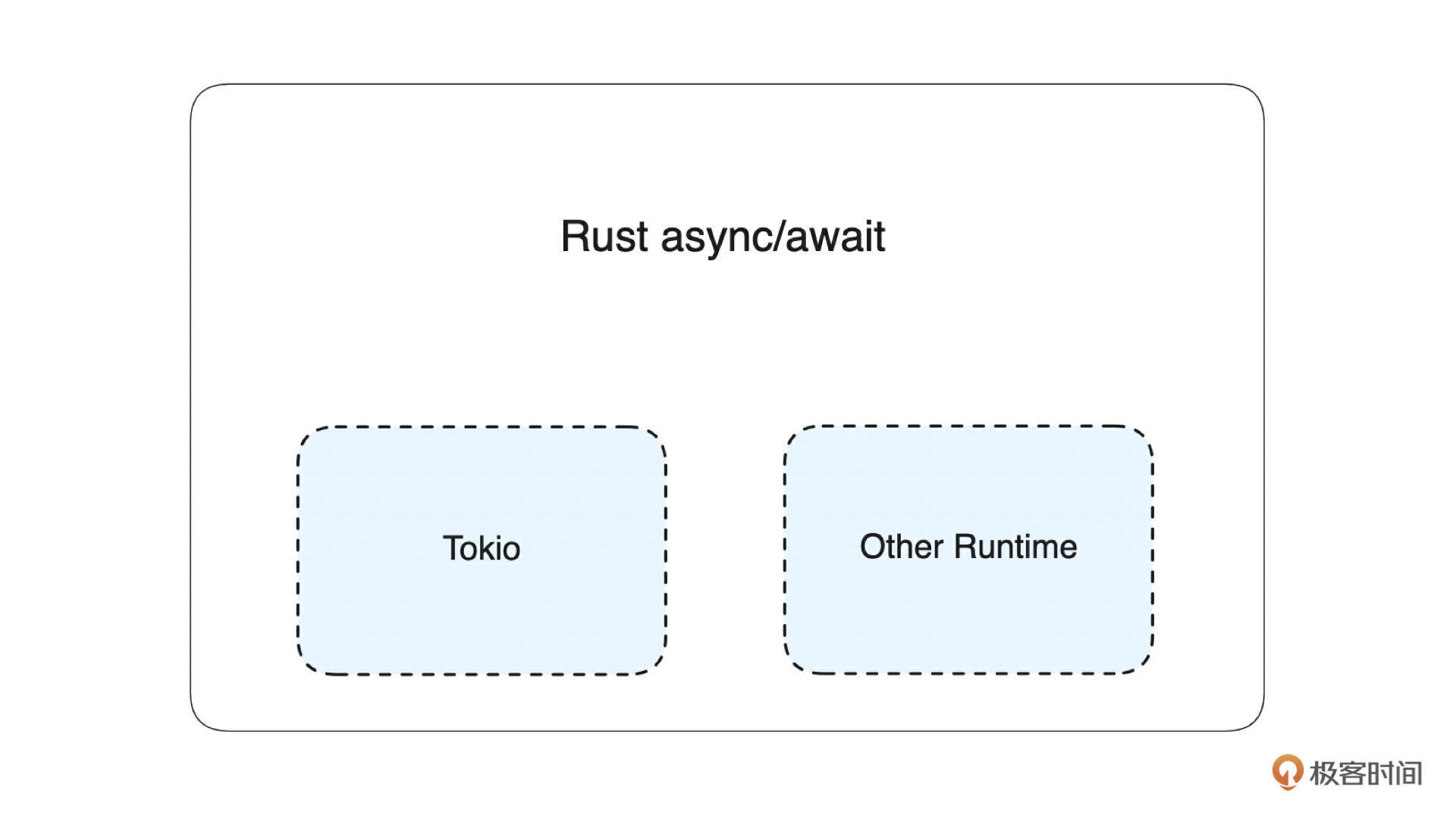
如上图所示,Tokio(Runtime)是 Rust 异步编程的一种实现。在 Rust 中,官方是没有提供给异步任务运行的地方(也就是 Runtime),是依赖社区提供的 Runtime,比较主流的实现有 Tikio、async-std 等等。 随着社区的发展,Tikio 是实现最好 、 性能最高的一个,逐步成为了唯一的选择。
Tokio 是一个生态,Runtime只是它的一部分。它还包含下面这些生态库(详细信息看 Tokio 官网):
-
Hyper:支持 HTTP 1 和 2 协议的 HTTP 客户端和服务器库。
-
Tonic:gRPC 客户端和服务器库。
-
Tower:用于构建可靠客户端和服务器的模块化组件,包括重试、负载平衡、过滤、请求限制功能等。
-
Mio:操作系统事件 I/O API 之上的最小可移植 API。
-
Tracing:对应用程序和库的统一洞察,提供结构化、基于事件的数据收集和记录。
-
Bytes:网络应用程序的核心是操作字节流,Bytes 提供了一组丰富的实用程序来操作字节数组。
从编码常用功能的角度,Tokio 还实现了异步版本的 channel、 Mutex 、 RwLock 、 Notify 、 Barrier 、 Semaphore 等实现,来提供线程间的数据通信以及状态同步、协调等等。其中 channel 和 lock 在编码过程中会大量用到,这块需要重点学习。
从学习 Tokio 的角度看,你首先要理解它的 Runtime 实现,然后再根据自己的需要了解对应的生态库,然后在编码中领会 Tokio 各种 channel 和 lock 等的使用。
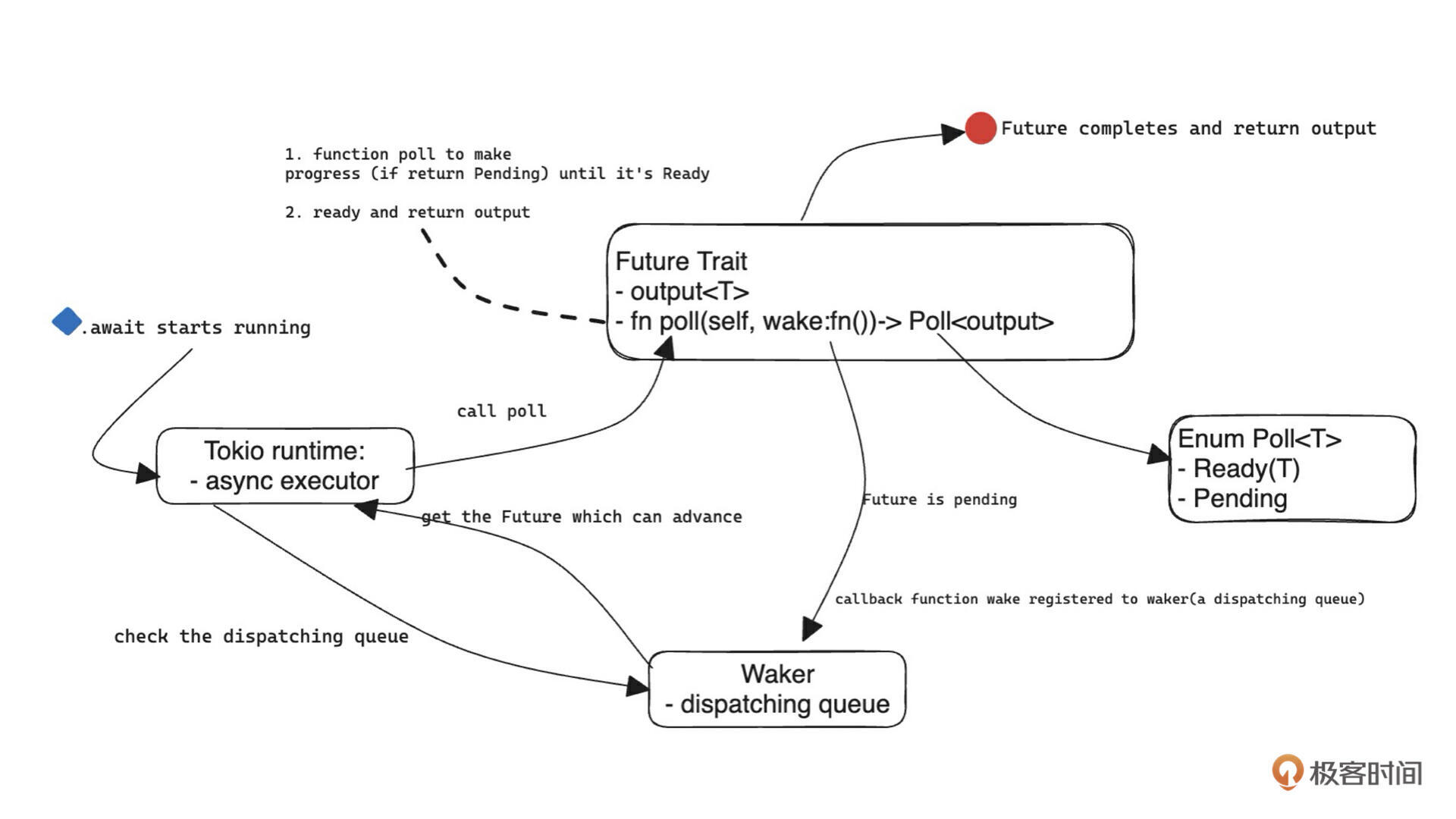
最后,放一张 Tokio 内核运行原理的架构图。你可以结合上面推荐的资料来理解它,这里就不展开了。
最后,再来看看测试用例。
测试用例
Rust 的测试用例从语法上看比较简单,主要关注 assert_eq! 和 assert! 两个语法,就不展开讲了,详细资料可以参考这个文档 《自动化测试》。测试用例的核心操作是通过 assert 来判断数据是否符合预期,比如:
#![allow(unused)] fn main() { assert_eq!(res.len(), 2); # 判断res 的长度是否等于 2,等于 2 就成功,不等于 2 就失败 assert!(!res.is_none()); # 判断 res 是否为 none }
在实际场景中, 写测试用例关注的主要不是语法,而是如何写一个好的测试用例来验证我们的代码逻辑是没问题的。 那怎么写呢?来看个实际的例子。
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use std::sync::Arc; use crate::storage::mqtt::topic::MQTTTopicStorage; use crate::storage::rocksdb::RocksDBEngine; use common_base::config::placement_center::PlacementCenterConfig; use metadata_struct::mqtt::topic::MQTTTopic; #[tokio::test] async fn topic_storage_test() { let mut config = PlacementCenterConfig::default(); config.data_path = "/tmp/tmp_test".to_string(); config.data_path = "/tmp/tmp_test".to_string(); let rs = Arc::new(RocksDBEngine::new(&config)); let topic_storage = MQTTTopicStorage::new(rs); let cluster_name = "test_cluster".to_string(); let topic_name = "loboxu".to_string(); 1. 保存数据 let topic = MQTTTopic { topic_id: "xxx".to_string(), topic_name: topic_name.clone(), retain_message: None, retain_message_expired_at: None, }; topic_storage .save(&cluster_name, &topic_name, topic) .unwrap(); 2. 保存数据 let topic_name = "lobo1".to_string(); let topic = MQTTTopic { topic_id: "xxx".to_string(), topic_name: topic_name.clone(), retain_message: None, retain_message_expired_at: None, }; topic_storage .save(&cluster_name, &topic_name, topic) .unwrap(); 3. 判断是否写入两条数据 let res = topic_storage.list(&cluster_name).unwrap(); assert_eq!(res.len(), 2); let res = topic_storage .get(&cluster_name, &"lobo1".to_string()) .unwrap(); assert!(!res.is_none()); 4. 删除一条数据 let name = "lobo1".to_string(); topic_storage.delete(&cluster_name, &name).unwrap(); 5. 判断数据是否存在 let res = topic_storage .get(&cluster_name, &"lobo1".to_string()) .unwrap(); assert!(res.is_none()); } } }
这是一个很典型的测试用例。其功能是:判断 MQTTTopicStorage 这个对象中的数据增删改查的代码行为是否符合预期。在代码中,第 1 和 2 步,保存了两行数据,第3 步判断是否成功写入两条数据,第4步删除数据,第5步判断数据是否删除成功。通过这五个步骤,完成了逻辑验证的闭环。
这段代码的核心是通过不同的 assert 操作来验证逻辑的闭环。而这也是我们写测试用例的目标。所以我们在写测试用例的时候,重要的是 逻辑闭环,即能够通过获取各个操作的结果,来判断行为是否符合预期。
关于在实际业务中,如何通过集成测试来保证代码质量,我们后面再详细展开讲。
总结
这节课我们挑了几个在写分布式应用过程中需要重点了解的知识点来展开讲。内容相对比较精简,但都给了对应的资料地址,当你对知识点有疑惑时,应该跳转到对应的资料去看。只要能看透,基本就能掌握相关知识点。
不过要想用 Rust 真正写一个工业应用,你还得把课程开头的《Rust 知识点集合》100% 掌握才行。Rust 是一门学习成本较高的语言,就是需要你反复地去学习和体会各个语法和特性。
思考题
你觉得我们的《Rust 知识点集合》还缺少哪些内容呢?
欢迎补充,如果今天的课程对你有所帮助,也欢迎你转发给有需要的同学,我们下节课再见!